





这个事起源于跟朋友一次聚会,他比较忙,一刻也不能停地处理工作。我就看他一直在看Excel表格,根据数据的特征不断地做决定。我比较好奇就问什么样的数据要做什么样的处理,他说了一些指标,比如X指标、Y指标都高,就执行A方案;X指标高、Y指标低,就执行B方案。
我程序员思维就冒出来了,说这也不用你一条条地看吧,你把标准列出来,例如X、Y到多少算高,处理方案订下来,写个Python程序跑一遍Excel表格结果就出来了——这其实就是给数据分类打标签。这就引出了本文想说的——聚类。
分类是指根据已经给出的正确的分类数据,通过其分类模型,对新数据进行分类。
而聚类,虽然也是将一堆数据分成几“类”——在聚类中,这叫“簇”,但是相比分类有明确的定义,聚类则是将相似的数据“聚”成一“簇”,至于这一“簇”是什么,我们不关心,我们只关心如何计算相似度。
算法很多,这里只介绍K均值算法。算法很简单,过程如下:
1、确定要聚成K个簇。
2、随机选择K个对象,作为每个簇的质心。
3、遍历其他对象,计算其与每个质心的距离(距离算法后述),并将其划分到最近质心的簇中。
4、计算每个簇中所有数据的平均值,将其设为新的质心。
5、重复3、4,直到新旧质心相等,我们视为其已经收敛。注意:不断地重复3、4步骤,质心的位置一定会在某处收敛,这是经过数学证明了的。
6、输出结果。
直接上代码:
public class KMeans { public static void main(String[] args) { List nodes = KMeans.buildNodes(100); int k = 3; // 因为是随机选初始质心,数据也是随机生成,所以本例就直接选前K个作为质心。 List centres = Lists.newArrayListWithCapacity(k); Map> centreMap = Maps.newHashMap(); for (int i = 0; i < k; i++) { Node n = nodes.get(i); centres.add(n); centreMap.put(i, new ArrayList()); } // System.out.println("初始质心:"); // System.out.println(centres.toString()); // System.out.println("数据:"); // System.out.println(nodes.toString()); // System.out.println("=================="); KMeans kmeans = new KMeans(); kmeans.kmean(nodes, centres, centreMap, k); } public void kmean(List nodes, List centres, Map> centreMap, int k) { boolean flag = true; while (flag) { // 遍历所有对象,计算其与所有质心的距离,并分簇 for (int i = 0; i < nodes.size(); i++) { Node node = nodes.get(i); int tmpDistance = Integer.MAX_VALUE; int tmpCode = Integer.MAX_VALUE; // System.out.println("计算Node" + node.toString() + "到各质心的距离"); for (int j = 0; j < centres.size(); j++) { Node centre = centres.get(j); // if (KMeans.nodeEquals(centre, node)) { // continue; // } //质心就是节点,不再计算距离 if (centre.equals(node)) { continue; } int distance = Distance.euclidean(node, centre).intValue(); // System.out.println("临时距离=" + tmpDistance); // System.out.println(node.toString() + "到质心" + centre.toString() + "的距离" + distance); if (distance < tmpDistance) { tmpDistance = distance; tmpCode = j; } } centreMap.get(tmpCode).add(node); // System.out.println("============="); } // 分簇完毕,根据每簇的节点计算新的质心。质心可以为虚拟的坐标点 List newCentres = Lists.newArrayListWithCapacity(k); Map> newCentreMap = Maps.newHashMap(); for (Map.Entry> entry : centreMap.entrySet()) { if (entry.getValue().size() == 1) { // 如果每簇只有一个Node,则不再计算,它就是质心 newCentres.add(entry.getValue().get(0)); newCentreMap.put(entry.getKey(), new ArrayList()); } else { // 计算新质心 Node newCentre = KMeans.getCentre(entry.getValue()); //某簇没有节点,也就没有新质心 if (Objects.isNull(newCentre)) { continue; } newCentres.add(newCentre); newCentreMap.put(entry.getKey(), new ArrayList()); } } // 新质心与原质心列表完全相同,代表已经收敛,最终结果已出,跳出循环 if (newCentres.containsAll(centres) && centres.containsAll(newCentres)) { flag = false; } // System.out.println("原质心:"); // System.out.println(centres.toString()); // System.out.println("计算结果:"); // System.out.println(centreMap.toString()); // System.out.println("新质心:"); // System.out.println(newCentres.toString()); // // System.out.println("是否收敛:" + converge); // KMeans.show(centres, centreMap); // System.out.println("-----------------"); if (!flag) { System.out.println("最终结果:"); KMeans.show(newCentres, centreMap); } centres.clear(); centreMap.clear(); centres = newCentres; centreMap = newCentreMap; } } /** * 打印结果 * * @param centres 质心列表 * @param centreMap 已分簇的数据 */ public static void show(List centres, Map> centreMap) { int i = 0; for (Map.Entry> entry : centreMap.entrySet()) { for (Node n : entry.getValue()) { System.out.println("[" + n.getX() + ", " + n.getY() + "," + i + "],"); } i++; } for (Node node : centres) { System.out.println("[" + node.getX() + ", " + node.getY() + "," + i++ + "],"); } } /** * 根据坐标判断是否为同一节点 * * @param n1 * @param n2 * @return */ public static boolean nodeEquals(Node n1, Node n2) { return n1.getX() == n2.getX() && n1.getY() == n2.getY(); } /** * 计算每簇Node的平均值,获取质心 * * @param nodes * @return */ public static Node getCentre(List nodes) { // 分簇之后,很有可能所有数据都离某一个质心最近,导致有些质心周围没有数据 if (nodes.isEmpty()) { return null; } int x = 0, y = 0; int size = nodes.size(); for (Node node : nodes) { x = x + node.getX(); y = y + node.getY(); } return new Node(x / size, y / size); } /** * 初始化散点数据 * * @return */ public static List buildNodes(int size) { List nodes = Lists.newArrayListWithCapacity(size); // 生成随机数据。Node除了X、Y的坐标外,后面还有一个Code值,这是我为了在图表中标注颜色用的,实际不参与计算 for (int i = 0; i < size; i++) { Node node = new Node((int) (Math.random() * 100), (int) (Math.random() * 100)); nodes.add(node); System.out.println("[" + node.getX() + ", " + node.getY() + ",0],"); } // nodes.clear(); // 以上是随机生成节点列表,下面是为了演示质心的选择会导致分簇结果不同而写的固定数据 // nodes.add(new Node(42, 7)); // nodes.add(new Node(94, 44)); // nodes.add(new Node(96, 66)); // nodes.add(new Node(62, 84)); // nodes.add(new Node(29, 33)); return nodes; }}Node就坐标XY与Code三个值,Code是我为了在图表中b区分颜色所用,实际不参与计算。
有些要单独说说:
1、质心的选择。文献上都说初始质心要从数据中随机选取,因为我的数据都是随机生成的,所以就偷懒直接取前K个数据作为初始质心。
2、随机获取初始质心,可能会导致同一份数据,分簇结果不同,如下:
数据集合:[62, 84],[29, 33],[42, 7],[94, 44],[96, 66]。两次运算,选取的初始质心不同,结果如下图:
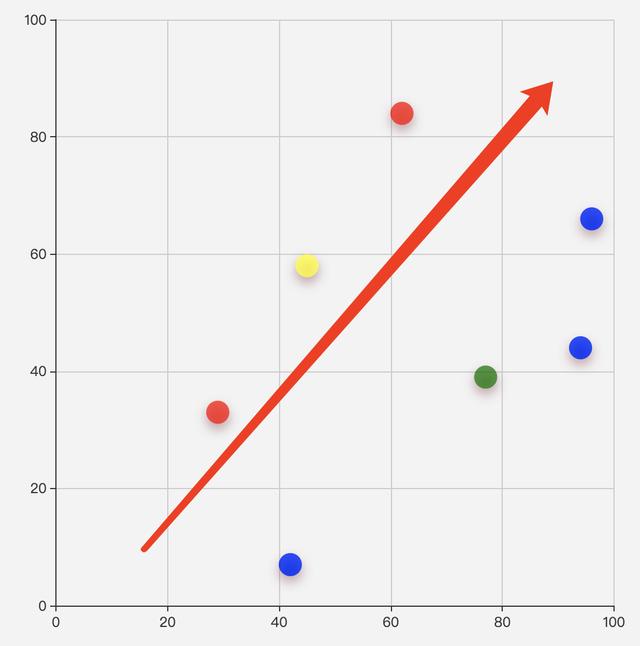
结果1
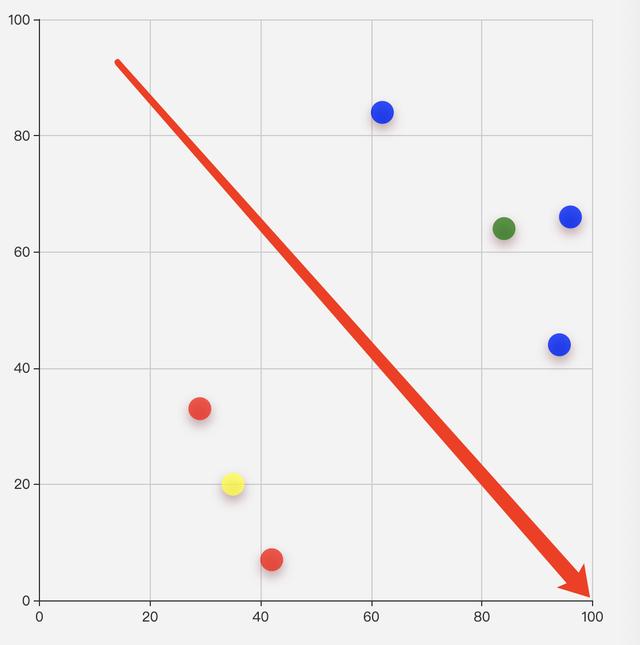
结果2
红蓝节点为分簇结果,黄绿为收敛最后的虚拟质心。
原因就是初始质心不同,导致第一次分簇结果不同,导致新计算的质心不同,导致最终分簇结果不同。
为了解决此问题,就有了KMeans++算法,后续篇我会说一下,如果有的话~~。
3、距离计算。本文采用了欧几里得距离,详情可参看前文。本文只有XY二维数据,如果是XYZ三维数据,可以写成√( (x1-x2)^2+(y1-y2)^2+(z1-z2)^2,高维数据以此类推。欧几里得距离只适用于连续变量。
欧几里得距离计算的是点与点的距离,并没有考虑方向这一因素。举例:
A商品原价100,涨价到150;B商品原价1000,涨价到1500;C商品200,降价到150。
如果按照价格绝对值看,AC的价格差不多,欧几里得距离相近,应聚为一类。
但是按照价格波动来看,AB都是涨价,幅度一致,C则是降价,所以AB应聚为一类。这时候就不适用欧几里得距离了,我们可以采用夹角余弦距离,来计算其相似度。其公式为:
(X1*X2+Y1*Y2)/(√X1^2+Y1^2+√X2^2+Y2^2)。
同欧几里得距离一样,也可以计算高维数据。
除了这两个距离计算方式,还有其他的,后续篇我会说一下,如果有的话~~。
KMeans也有不少缺陷,故衍生了不少算法,例如KMeans++等,后续篇我会说一下,如果有的话~~
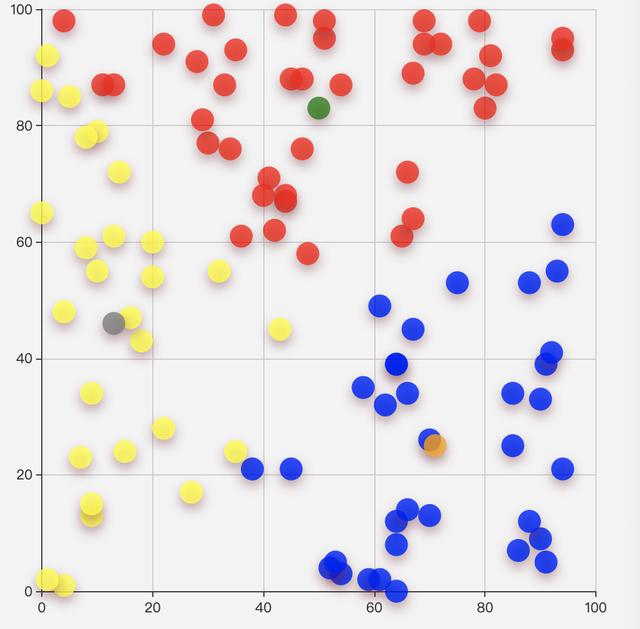
下图是我某次跑的数据结果:















 1308
1308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









