







上一节我们讲了一个非常常见的分类算法逻辑回归,那么如何去评价分类结果的好坏呢?
Mr.喵:Python与机器学习:逻辑回归zhuanlan.zhihu.com
对于分类算法的评价比对回归算法的评价复杂得多
准确率的陷阱和混淆矩阵
我们习惯于用分类准确率来评价分类结果的好坏,但是对于极度偏斜(Skewed Data)的数据,只使用分类准确度是远远不够的,需要使用混淆矩阵来进一步分析
混淆矩阵 Confusion Matrix
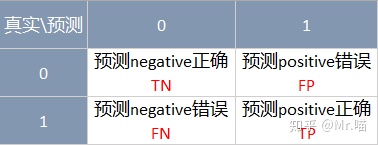
精准率和召回率

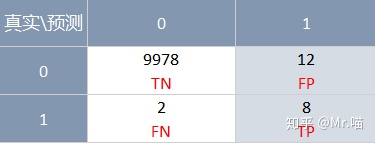
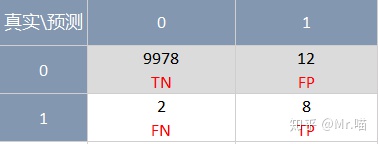
精准率: 是指对于我们预测为正例(positive)的样本中,正确预测为正例的占比
e.g. 精准率 = 8/(8+12) = 40%
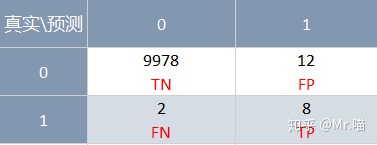
召回率:是指对于真实发生为正例(positive)的样本中,正确预测为正例的占比
e.g. 召回率 = 8/(8+2) = 80%
虽然Precision和Recall的值我们预期是越高越好,但是这两个值在某些场景下却是存在互斥的,对于使用精准率还是使用召回率的选择,我们需要视具体使用场景而定,有的场景更注重精准率,有的场景更注重召回率。但也有场景更希望获得精准率和召回率两者之间的平衡。
F1 Score
F1 Score是precision和recall二者都兼顾的指标,是precision和recall的调和平均值
Scikit-learn中的precision & recall & F1 Score
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target.copy()
y[digits.target==9] = 1
y[digits.target!=9] = 0
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
log_reg.score(X_test, y_test) # 准确率0.9755555555555555
y_predict = log_reg.predict(X_test)
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_predict)array([[403, 2],
[ 9, 36]], dtype=int64)
from sklearn.metrics import precision_score
precision_score(y_test, y_predict) # 精准率0.9473684210526315
from sklearn.metrics import recall_score
recall_score(y_test, y_predict)0.8
from sklearn.metrics import f1_score
f1_score(y_test, y_predict) # F1 Score0.8674698795180723
精准率-召回率的平衡
我们知道逻辑回归的决策边界为:
并且Precision和Recall的趋势相反,所以可以通过调节threshold,来控制precision-recall之间的平衡。
精准率-召回率曲线
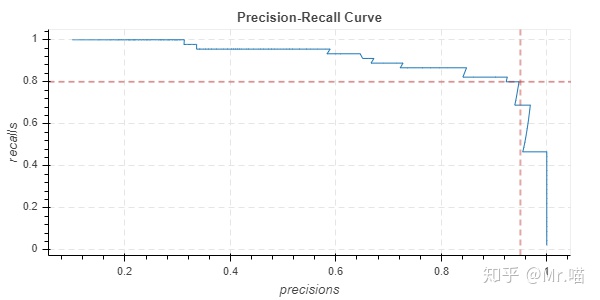
从图中可以看到,拐点处就是precision-recall两者的平衡点,我们可以通过精准率-召回率曲线找到最佳的threshold
Scikit-learn 中的Precision-Recall Curve
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_test, decision_scores)
plt.plot(thresholds, precisions[:-1])
plt.plot(thresholds, recalls[:-1])
plt.plot(precisions, recalls)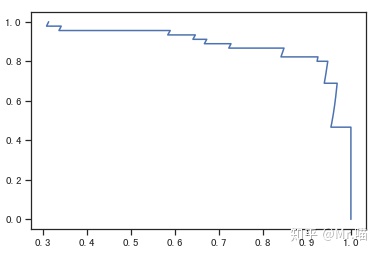
ROC曲线
ROC曲线是描述TPR和FPR之间的关系的曲线,
TPR:是指对于真实发生为正例(positive)的样本中,正确预测为正例的占比,跟Recall一样
FPR:是指对于真实发生为负例(Negative)的样本中,错误预测为正例的占比
TPR和FPR的趋势一致
ROC可以反映模型分类效果的好坏,但是无法直接从图中识别出分类最好的阈值,事实上最佳阈值是视具体的场景而定的,特别是对于极度偏斜的数据,查看precision和recall非常有必要
ROC对应的AUC越大,说明模型效果分类越好
Scikit-learn中的ROC
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set(font='SimHei',style='ticks')
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target.copy()
y[digits.target==9] = 1
y[digits.target!=9] = 0
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
decision_scores = log_reg.decision_function(X_test)
from sklearn.metrics import roc_curve
fprs, tprs, thresholds = roc_curve(y_test, decision_scores)
plt.plot(fprs, tprs)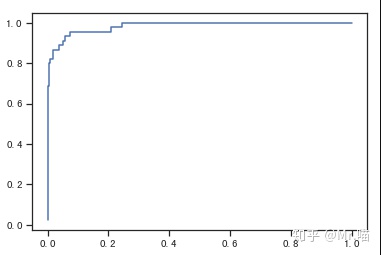
from sklearn.metrics import roc_auc_score
roc_auc_score(y_test, decision_scores) #AUC0.9830452674897119















 200
200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









