







文章:Two-Stream Convolutional Networks for Action Recognition in Videos(NIPS2014)
链接:https://arxiv.org/abs/1406.2199
虽然在2013年就在人类行为识别的一篇文章中提出了3D卷积的内容,但效果并不好,直到这篇文章出来以后才意味着深度学习在行为识别中迈出了重大的一步。
主要贡献点:
1、首先,我们提出了一种融合时空网络的双流convnet体系结构。
2、第二,我们证明了在多帧密集光流上训练的convnet的方法,即使在训练数据有限的情况下仍能获得很好的性能。
3、最后,将多任务学习应用于两种不同的动作分类数据集,可以增加训练数据量,提高训练数据的性能。
介绍:所谓two-stream是指空间stream和时间stream,视频可以分成空间与时间两个部分,空间部分指独立帧的表面信息,关于物体、场景等;而时间部分信息指帧间的光流,携带着帧之间的运动信息。相应的,所提出的网络结构由两个深度网络组成,分别处理时间与空间的维度。结构如下图所示:
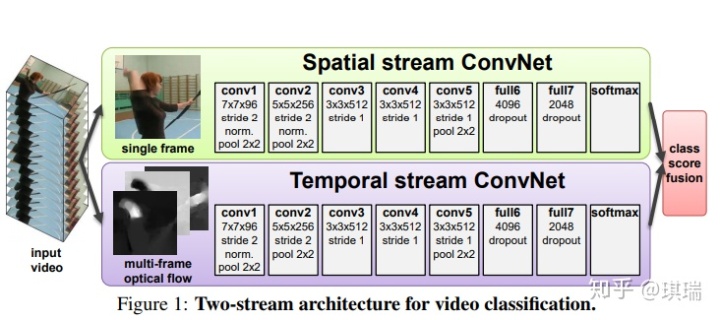
上层的Spatio Stream Convet处理静态的帧画面,输入是单个帧画面,得到画面中物体的特征,还可以使用ImageNet challenge数据集种有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2778
2778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









