







本博客来源于CSDN机器鱼,未同意任何人转载。
更多内容,欢迎点击本专栏,查看更多内容。
目录
本博客内容基于Pytorch1.8可完全跑通。
0 引言
在【博客】里,我们提出了双流CNN的故障诊断方法,但是两个CNN通道都是输入的振动信号,1DCNN输入的是1*1024的信号,2DCNN输入的是32*32的信号(32*32=1024)。实质上都是振动信号,为此我们结合【博客】的小波时频图,与快速傅里叶变换频谱信号,构建基于FFT频谱与小波时频图的双流CNN轴承故障诊断模型,其中2DCNN以时频图为输入,1DCNN以FFT频谱为输入。

1 基于FFT频谱与小波时频图的双流CNN轴承故障诊断模型
其结构如图2所示。原理如下:
基于2D-CNN与1D-CNN,构建双通道的CNN(双流CNN),其中2D-CNN以小波时频图为输入,而1D-CNN以FFT频谱信号为输入,分别进行卷积层与池化层的特征提取之后,拉伸为特征向量,然后在汇聚层进行拼接,接着是全连接层与分类层。此种方法可以实现1维时域特征与2维时频域特征的有效融合,并以此来提高分类正确率。以下内容均在Pytorch1.8中实现。
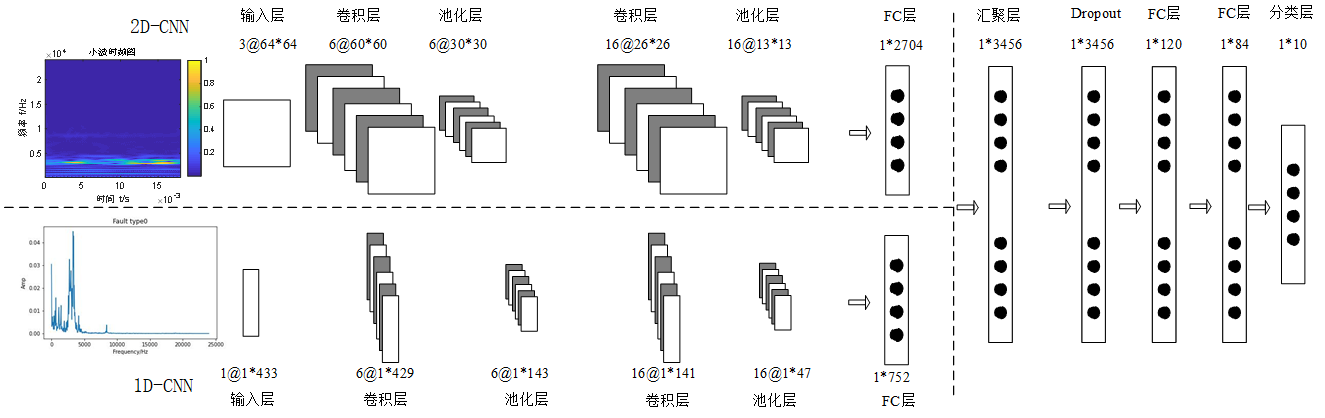 图 2 双流CNN结构
图 2 双流CNN结构
2 数据准备
参考我的另一篇【博客】,里面可以获得我这个博客所用到的数据。运行下面代码提取训练集与测试集。
# -*- coding: utf-8 -*-
import os
from scipy.io import loadmat,savemat
import numpy as np
from sklearn.model_selection import train_test_split
# In[]
lis=os.listdir('./data/')
N=200;Len=1024 #每种故障取N个样本,每个样本长度是Len
# 一共10类 标签是0-9
data=np.zeros((0,Len))
label=[]
for n,i in enumerate(lis):
path='./data/'+i
print('第',n,'类的数据是',path,'这个文件')
file=loadmat(path)
file_keys = file.keys()
for key in file_keys:
if 'DE' in key:
files= file[key].ravel()
data_=[]
for i in range(N):
start=np.random.randint(0,len(files)-Len)
end=start+Len
data_.append(files[start:end])
label.append(n)
data_=np.array(data_)
data=np.vstack([data,data_])
label=np.array(label)
# 9:1划分数据集
train_x,test_x,train_y,test_y=train_test_split(data,label,test_size=.1,random_state=0)
# In[] 保存数据
savemat('result/data_process.mat',{'train_x':train_x,'test_x':test_x,
'train_y':train_y,'test_y':test_y})2.1 小波时频图提取
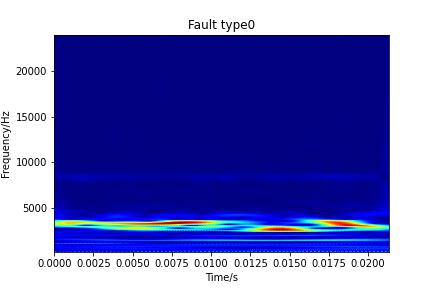
首先对于每种故障类型,都提取一张小波视频图画图。
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
# 每种故障取一个样本出来画图举例
import numpy as np
import pywt
import os
from scipy.io import loadmat
# In[]
lis=os.listdir('./data/')
Len=1024
data=[]
for n,i in enumerate(lis):
path='./data/'+i
print('第',n,'类的数据是',path,'这个文件')
file=loadmat(path)
file_keys = file.keys()
for key in file_keys:
if 'DE' in key:
files= file[key].ravel()
start=np.random.randint(0,len(files)-Len)
end=start+Len
data.append(files[start:end])
# In[] 参数设置
for i in range(10):
sampling_rate=48000# 采样频率
wavename = 'cmor3-3'#cmor是复Morlet小波,其中3-3表示Fb-Fc,Fb是带宽参数,Fc是小波中心频率。
totalscal = 256
fc = pywt.central_frequency(wavename)# 小波的中心频率
cparam = 2 * fc * totalscal
scales = cparam / np.arange(totalscal, 1, -1)
[cwtmatr, frequencies] = pywt.cwt(data[i], scales, wavename, 1.0 / sampling_rate)
t=np.arange(len(data[i]))/sampling_rate
plt.figure()
plt.plot(t, data[i])
plt.xlabel('Time/s')
plt.ylabel('Amplitude')
plt.title('Fault type'+str(i))
plt.savefig('result/Fault type'+str(i)+' Signal.jpg')
plt.close()
plt.figure()
t,frequencies = np.meshgrid(t,frequencies)
plt.pcolormesh(t, frequencies, abs(cwtmatr),cmap='jet')
plt.xlabel('Time/s')
plt.ylabel('Frequency/Hz')
plt.title('Fault type'+str(i))
plt.savefig('result/Fault type'+str(i)+' Spectrum.jpg')
plt.close()接着我们对数据提取得到data_process.mat写一个循环,提取训练集与测试集的时频图。
# -*- coding: utf-8 -*-
# 对所有样本依次计算时频图 并保存
from threading import Thread
import matplotlib.pyplot as plt
import numpy as np
import pywt
from scipy.io import loadmat
import os
import shutil
shutil.rmtree('image/')
os.mkdir('image/')
os.mkdir('image/train')
os.mkdir('image/test')
# In[]
def Spectrum(data,label,path):
label=label.reshape(-1,)
for i in range(data.shape[0]):
sampling_rate=48000# 采样频率
wavename = 'cmor3-3'#cmor是复Morlet小波,其中3-3表示Fb-Fc,Fb是带宽参数,Fc是小波中心频率。
totalscal = 256
fc = pywt.central_frequency(wavename)# 小波的中心频率
cparam = 2 * fc * totalscal
scales = cparam / np.arange(totalscal, 1, -1)
[cwtmatr, frequencies] = pywt.cwt(data[i], scales, wavename, 1.0 / sampling_rate)
t=np.arange(len(data[i]))/sampling_rate
t,frequencies = np.meshgrid(t,frequencies)
plt.pcolormesh(t, frequencies, abs(cwtmatr),cmap='jet')
plt.axis('off')
plt.savefig(path+'/'+str(i)+'_'+str(label[i])+'.jpg', bbox_inches='tight',pad_inches = 0)
plt.close()
data=loadmat('result/data_process.mat')
Spectrum(data['train_x'],data['train_y'],'image/train')
Spectrum(data['test_x'],data['test_y'],'image/test')
# p1 = Thread(target=Spectrum, args=(data['train_x'],data['train_y'],'image/train'))
# p2 = Thread(target=Spectrum, args=(data['test_x'],data['test_y'],'image/test'))
# p1.start()
# p2.start()
# p1.join()
# p2.join()
2.2 FFT频谱提取
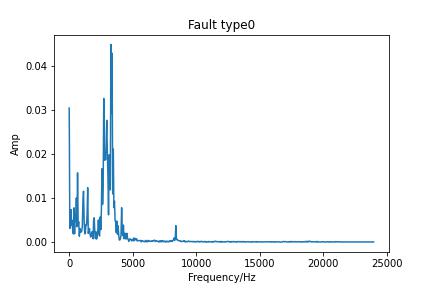
首先写一个程序来提取每种故障类型的FFT,用于可视化。
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
# 每种故障取一个样本出来举例
import numpy as np
import os
from scipy.io import loadmat
from scipy.fftpack import fft#快速傅里叶变换
# In[]
lis=os.listdir('./data/')
Len=1024
data=[]
for n,i in enumerate(lis):
path='./data/'+i
print('第',n,'类的数据是',path,'这个文件')
file=loadmat(path)
file_keys = file.keys()
for key in file_keys:
if 'DE' in key:
files= file[key].ravel()
start=np.random.randint(0,len(files)-Len)
end=start+Len
data.append(files[start:end])
# In[] 参数设置
for i in range(10):
sampling_rate=48000# 采样频率
N=data[i].shape[0]
x = np.arange(N) # 频率个数
half_x = x[range(int(N/2))] #取一半区间
fft_y=fft(data[i])
abs_y=np.abs(fft_y) # 取复数的绝对值,即复数的模(双边频谱)
normalization_y=abs_y/N #归一化处理(双边频谱)
normalization_half_y = normalization_y[range(int(N/2))]
Fre = np.arange(int(N/2))*sampling_rate/N # 频率坐标
plt.figure()
plt.plot(Fre,normalization_half_y)
plt.xlabel('Frequency/Hz')
plt.ylabel('Amp')
plt.title('Fault type'+str(i))
plt.savefig('result/Fault type'+str(i)+' FFT Spectrum.jpg')
plt.close()接着我们对数据提取得到data_process.mat写一个循环,提取训练集与测试集的FFT数据。
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
import os
from scipy.io import loadmat,savemat
from scipy.fftpack import fft#快速傅里叶变换
# In[] 参数设置
def Spectrum(data):
fea=[]
N=data.shape[1]
for i in range(data.shape[0]):
fft_y=fft(data[i])
abs_y=np.abs(fft_y) # 取复数的绝对值,即复数的模(双边频谱)
normalization_y=abs_y/N #归一化处理(双边频谱)
normalization_half_y = normalization_y[range(int(N/2))]
fea.append(normalization_half_y)
return np.array(fea)
data=loadmat('result/data_process.mat')
train_y=data['train_y']
test_y=data['test_y']
train_x=Spectrum(data['train_x'])
test_x=Spectrum(data['test_x'])
savemat('result/data_fft.mat',{'train_x':train_x,'test_x':test_x,
'train_y':train_y,'test_y':test_y})
3 模型搭建与训练
# coding: utf-8
# FFT频谱(频域特征)+小波时频图(时频域特征),双流CNN卷积神经网络实现2种特征的有效融合
# In[1]: 导入必要的库函数
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader,TensorDataset
from sklearn.preprocessing import MinMaxScaler,StandardScaler
import matplotlib.pyplot as plt
if torch.cuda.is_available():
torch.backends.cudnn.deterministic = True
from scipy.io import loadmat
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
torch.manual_seed(0)
import os
from PIL import Image
# In[2] 定义数据提取函数
def read_directory(directory_name,height,width,normal):
# directory_name='小波时频/train_img'
#height=64
#width=64
#normal=1
file_list=os.listdir(directory_name)
file_list.sort(key=lambda x: int(x.split('_')[0]))
img = []
label0=[]
for each_file in file_list:
img0 = Image.open(directory_name + '/'+each_file)
gray = img0.resize((height,width))
img.append(np.array(gray).astype(np.float))
label0.append(float(each_file.split('.')[0][-1]))
if normal:
data = np.array(img)/255.0#归一化
else:
data = np.array(img)
data=data.reshape(-1,3,height,width)
label=np.array(label0)
return data,label
# In[2] 加载数据
num_classes=10
height=64
width=64
# 小波时频图---2D-CNN输入
x_train,y_train=read_directory('image/train',height,width,normal=1)
x_valid,y_valid=read_directory('image/test',height,width,normal=1)
# FFT频域信号--1D-CNN输入
datafft=loadmat('result/data_fft.mat')
x_train2=datafft['train_x']
x_valid2=datafft['test_x']
ss2=StandardScaler().fit(x_train2)
x_train2=ss2.transform(x_train2)
x_valid2=ss2.transform(x_valid2)
x_train2=x_train2.reshape(x_train2.shape[0],1,-1)
x_valid2=x_valid2.reshape(x_valid2.shape[0],1,-1)
# 转换为torch的输入格式
train_features = torch.tensor(x_train).type(torch.FloatTensor)
valid_features = torch.tensor(x_valid).type(torch.FloatTensor)
train_features2 = torch.tensor(x_train2).type(torch.FloatTensor)
valid_features2 = torch.tensor(x_valid2).type(torch.FloatTensor)
train_labels = torch.tensor(y_train).type(torch.LongTensor)
valid_labels = torch.tensor(y_valid).type(torch.LongTensor)
print(train_features.shape)
print(train_features2.shape)
print(train_labels.shape)
N=train_features.size(0)
# In[3]: 参数设置
learning_rate = 0.01#学习率
num_epochs = 200#迭代次数
batch_size = 16 #batchsize
# In[4]:
# 模型设置
class ConvNet(torch.nn.Module):
def __init__(self, num_classes):
super(ConvNet, self).__init__()
# 2D-CNN 输入为64*64*3 的图片
self.net1 = nn.Sequential(
nn.Conv2d(3, 6, kernel_size=5), #卷积,64-5+1=60 ->60*60*6
nn.MaxPool2d(kernel_size=2), #池化,60/2=30 -> 30*30*6
nn.ReLU(), #relu激活
# nn.BatchNorm2d(6),
nn.Conv2d(6, 16, kernel_size=5), #卷积,30-5+1=26 ->26*26*16
nn.MaxPool2d(kernel_size=2), #池化,26/2=13 ->13*13*16
nn.ReLU(), #relu激活
# nn.BatchNorm2d(16)
)
# 1D-CNN 输入1*512FFT频谱信号
self.net3 = nn.Sequential(
nn.Conv1d(1, 6, kernel_size=5), #卷积,512-5+1=508 ->1*508*6
nn.MaxPool1d(kernel_size=3,padding=1), #池化,(508+1)/3=170 -> 1*170*6
nn.ReLU(), #relu激活
nn.Conv1d(6, 16, kernel_size=3), #卷积,170-3+1=168 ->1*168*16
nn.MaxPool1d(kernel_size=3), #池化,168/3=56 ->1*56*16
nn.ReLU() #relu激活
)
self.classifier = nn.Sequential(
nn.Linear(13*13*16+56*16, 120), #全连接 120
nn.ReLU(), #relu激活
# nn.Dropout(0.5), #dropout 0.5
nn.Linear(120, 84), #全连接 84
nn.ReLU(), #relu激活
nn.Linear(84, num_classes), #输出 5
)
def forward(self, x1,x2):
x1 = self.net1(x1)#进行卷积+池化操作提取图片特征
x2 = self.net3(x2)#进行卷积+池化操作提取fft频谱特征
x1=x1.view(-1, 13*13*16)
x2=x2.view(-1, 56*16)
x=torch.cat([x1,x2],dim=1)#拉伸向量,拼接
logits = self.classifier(x)#将上述特征拉伸为向量输入进全连接层实现分类
probas = F.softmax(logits, dim=1)# softmax分类器
return logits, probas
# 计算准确率与loss,就是把所有数据分批计算准确率与loss
def compute_accuracy(model, feature,feature1,labels):
correct_pred, num_examples = 0, 0
l=0
N=feature.size(0)
total_batch = int(np.ceil(N / batch_size))
indices = np.arange(N)
np.random.shuffle(indices)
for i in range(total_batch):
rand_index = indices[batch_size*i:batch_size*(i+1)]
features = feature[rand_index,:]
features1 = feature1[rand_index,:]
targets = labels[rand_index]
features = features.to(device)
features1 = features1.to(device)
targets = targets.to(device)
logits, probas = model(features,features1)
cost = loss(logits, targets)
_, predicted_labels = torch.max(probas, 1)
num_examples += targets.size(0)
l += cost.item()
correct_pred += (predicted_labels == targets).sum()
return l/num_examples,correct_pred.float()/num_examples * 100
model = ConvNet(num_classes=num_classes)# 加载模型
model = model.to(device)#传进device
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)#优化器
loss=torch.nn.CrossEntropyLoss()#交叉熵损失
# In[5]:
train_loss,valid_loss=[],[]
train_acc,valid_acc=[],[]
for epoch in range(num_epochs):
model = model.train()#启用dropout
total_batch = int(np.ceil(N / batch_size))
indices = np.arange(N)
np.random.shuffle(indices)
avg_loss = 0
for i in range(total_batch):
rand_index = indices[batch_size*i:batch_size*(i+1)]
features = train_features[rand_index,:]
features2 = train_features2[rand_index,:]
targets = train_labels[rand_index]
features = features.to(device)
features2 = features2.to(device)
targets = targets.to(device)
logits, probas = model(features,features2)
cost = loss(logits, targets)
optimizer.zero_grad()
cost.backward()
optimizer.step()
model = model.eval()#关闭dropout
with torch.set_grad_enabled(False): # save memory during inference
trl,trac=compute_accuracy(model, train_features,train_features2,train_labels)
val,vaac=compute_accuracy(model, valid_features,valid_features2,valid_labels)
print('Epoch: %03d/%03d training accuracy: %.2f%% validing accuracy: %.2f%%' % (
epoch+1, num_epochs,
trac,
vaac))
train_loss.append(trl)
valid_loss.append(val)
train_acc.append(trac)
valid_acc.append(vaac)
torch.save(model,'model/W_CNN2.pkl')#保存整个网络参数
# In[]
#loss曲线
plt.figure()
plt.plot(np.array(train_loss),label='train')
plt.plot(np.array(valid_loss),label='valid')
plt.title('loss curve')
plt.legend()
plt.show()
# accuracy 曲线
plt.figure()
plt.plot(np.array(train_acc),label='train')
plt.plot(np.array(valid_acc),label='valid')
plt.title('accuracy curve')
plt.legend()
plt.show()
# In[6]: 利用训练好的模型 对测试集进行分类
model=torch.load('model/W_CNN2.pkl')#加载模型
#提取测试集图片
x_test,y_test=read_directory('image/test',height,width,normal=1)
x_test2=datafft['test_x']
x_test2=ss2.transform(x_test2)
x_test2=x_test2.reshape(x_test2.shape[0],1,-1)
test_features = torch.tensor(x_test).type(torch.FloatTensor)
test_features2 = torch.tensor(x_test2).type(torch.FloatTensor)
test_labels = torch.tensor(y_test).type(torch.LongTensor)
model = model.eval()
_,teac=compute_accuracy(model, test_features,test_features2,test_labels)
print('测试集正确率为:',teac.item(),'%')
我们注意到1DCNN输入的size是1*512,这是FFT的特性决定的,FFT提取的频谱是对称的,我们只需要用一半。


从正确率与loss曲线可以看出,网络在200次训练的时候基本就完全收敛了,保存此时的模型,用于测试集分类。.

4 结语
采用小波时频图与FFT频谱信号构建双流CNN故障诊断模型,能极大的提高故障诊断正确率,最终测试集的正确率达到100%。哎呀真开心,又水了一篇博客。

球球不要问完整代码了,完整代码和数据上面都有,稍微有点动手能力就能成功运行,非要我打包压缩好的,可以见评论区。记住,所有的代码和数据都可以在博客中找到。
更多内容请点击【专栏】获取,您的点赞与收藏是我更新Python神经网络1000案例分析的动力。


















 804
804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











