







文章:Searching and mining trillions of time series subsequences under dynamic time warping
来源:KDD2012
一、笔记概述
阅读论文的研究对象是“如何快速的计算两个并未完全对齐的时间序列数据(Time series data)之间的距离,确认其对齐后(即二者最小距离时)能否达到相似的标准,从而实现从万亿级数据中寻找相似片段的目标。”利用的方法是对动态时间规整算法(Dynamic Time Warping,后文简称DTW)进行改进。
二、朴素DTW逻辑
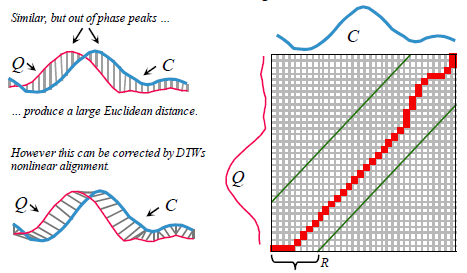
- 何为两个序列的距离
DTW核心是将两个不同的序列按照对齐后比较,而如何才是最好对齐呢?对齐的方式有很多,最好的对齐方式就是两个序列的距离最小,同时这个最小的距离即被定义为两个序列的距离。
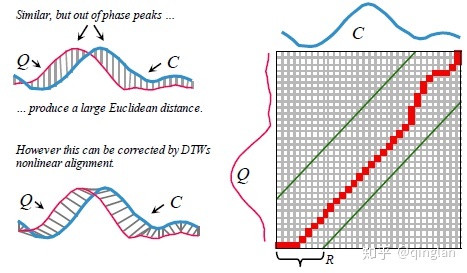
如图所示,两条长度不同的序列Q,C,假设Q的序列长度为n,而C的序列长度为m,那么我们需要构建一个n*m的矩阵,其中矩阵元素(i,j)表示Qi和Cj之间的距离。每个矩阵元素表示Qi和Cj对齐,那么从矩阵左下角到右上角可以找到很多路径(从左下角到右上角是因为两个不同的序列无论长短,它们的起始点和终止点肯定是对应的),
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 453
453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









