






本文是基于阅读《Searching and Mining Trillions of Time Series Subsequences under Dynamic Time Warping》的理解。由于本人以前对相关方面接触的不是很多,对该行业相应的一些基本理念也不是很清楚,在小白的情况下阅读这篇论文还是比较吃力的,我还没有很清楚地理解这篇论文T~T,所以我就先写写我对DTW的理解啦~至于对作者提出的4个优化方案,我还没有彻底理解明白,所以先空一小块,等我完全明白了我再来更新,不会太久的!!请大家见谅啦~
论文链接:
https://www.cs.ucr.edu/~eamonn/SIGKDD_trillion.pdfwww.cs.ucr.edu上课的时候在老师的讲解下对DTW有了一些了解:
DTW(Dynamic Time Warping):动态时间规整/动态时间扭曲。emmmm~我百度了一下,貌似对Warping没有个定下来的概念,不过“规整”好像大多数人用的比较多。
DTW就是通过计算两个时间序列的距离,比较这两个时间序列的相似度,由日本学者Itakura提出。主要应用于语音识别,文本对比,天气预测,股票预测等方面
假设有一个长时间序列T,
它有个子序列
指定一个序列 Q,

欧式距离只能是两个序列一对一映射,像图中的阴影线一样,比较像是DTW的一个特例,因为DTW允许一对多的映射。欧式距离的缺点在于当数据集出现异常值(即数据不是很规范)的时候,欧几里德距离表现不"稳定"
如果用DTW来对两个序列进行比较的话,可以构造一个n×n矩阵,
矩阵的
翘曲路径是一组连续的矩阵元素,它们定义了qc之间的映射。翘曲路径的第t个元素定义为
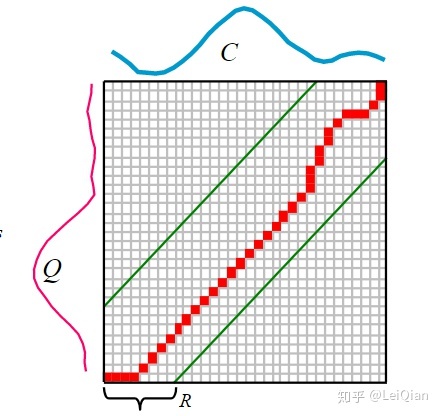
不过有受到以下几点约束:①P的起始点和结尾点必须是Q,C重合对应的起始和结束点,即最左下角和右上角的两个点;②下一步必须是相邻的单元格,即不能间隔跨度太大;③时间间隔必须相同;④通过限制偏离对角的距离在全局上限制翘曲路径
在作者提出优化之前,已知的算法优化有:
①省略平方根的计算,不会影响最终结果,减少计算量,更易于解释;
②利用计算量小的下界来删除没有可能的候选对象。 一个可用的下界为:
③计算ED和
④DTW过程中提前终止。虽然DTW在计算完所有长度之前是不能确定最优的,但是如果计算得到
⑤使用多核获得本质上的线性加速,就是从硬件上获得更高的配置,就像打英雄联盟一样(虽然举例有点不太恰当,我不是网瘾少女T~T)
目前我的理解就只能到这啦~~等我过两天再把作者的优化补上来~~见谅啦















 478
478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









