






此篇主要介绍,文本pdf的表格抽取有哪些python包(不涵盖扫描件的pdf或表格本身为图片的)。
首先pdf的解析工具有很多,如下图。
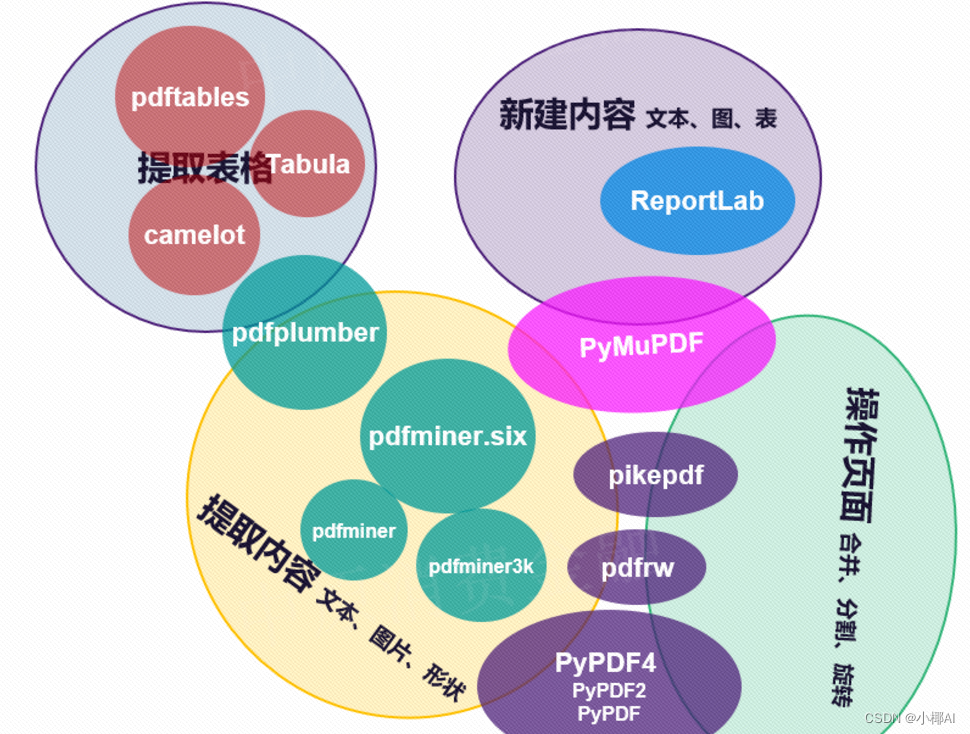
那么根据前辈们以及自己的尝试,可以有效提取表格的工具的有:camelot、pdfplumber以及tabula。
| 工具 | git最新更新时间 | git地址 | star个数 | 优点 | 缺点 | 帮助文档 |
| camelot | 3年前 | GitHub - atlanhq/camelot: Camelot: PDF Table Extraction for Humans | 3.3k | 能提取完整表格和不完整表格 | 不能对无线表格有效提取,可以通过stream模式(规则进行结构化) | Camelot: PDF Table Extraction for Humans — Camelot 0.10.1 documentation |
| pdfplumber | 1周前 | https://github.com/jsvine/pdfplumber | 3k | 能提取完整表格,提取结果较为规范 | 不能对无线表格有效提取 | pdfplumber/README-CN.md at stable · hbh112233abc/pdfplumber · GitHub |
| tabula-py | 3天前 | GitHub - chezou/tabula-py: Simple wrapper of tabula-java: extract table from PDF into pandas DataFrame | 1.7k | 能提取完整表格 | 提取结果不规范,不能对无线表格有效提取 | tabula-py: Read tables in a PDF into DataFrame — tabula-py documentation |
注意:tabula-py依赖于GitHub - tabulapdf/tabula: Tabula is a tool for liberating data tables trapped inside PDF files
(tabula-py 就是对它做了一层 python 的封装,所以也依赖 java7/8)
1、camelot
使用camelot读取表格,并生成excel
import camelot
path_file = "交通银行.pdf"
# ========= 使用camelot提取表格
tables = camelot.read_pdf(path_file, pages="1,2,3,4,5", flavor="stream") # 前提要知道至少有5页
# tables = camelot.read_pdf(path_file, pages="1,2,3,4,5", flavor="lattice") # 使用lattice
# 有线表格时,使用lattice;无线表格时,建议使用stream,再规则化
print(len(tables))
# ========= 表格写入excel
_writer = pd.ExcelWriter("{}.xlsx".format(path_file.split(".")[0]))
for i in range(len(tables)):
_data = tables[i].df
_data.to_excel(_writer, sheet_name="page-{}".format(i))
_writer.save()
_writer.close()2、pdfplumber
使用pdfplumber读取表格,并生成excel
import pdfplumber
import pandas as pd
path_file = "交通银行.pdf"
# ========= 使用pdfplumber提取表格
pdf = pdfplumber.open(path_file)
# ========= 表格写入excel
_writer = pd.ExcelWriter("{}.xlsx".format(path_file.split(".")[0]))
for i in range(5): # 最起码有5页
table = pdf[i].extract_table() # 每页只有一个表格
_data = pd.DataFrame(table)
_data.to_excel(_writer, sheet_name="page-{}".format(i))
_writer.save()
_writer.close()3、tabula
使用tabula读取表格,并生成csv
import tabula
path_file = "交通银行.pdf"
# ========= 使用tabula提取表格 convert PDF into CSV file
tabula.convert_into("test.pdf", "{}.csv".format(path_file.split(".")[0]), output_format="csv", pages='all')注意:依赖Java 8+,需要安装对应的JDK
4、总结
本篇主要介绍了目前抽取文本pdf的三种有效工具。
值得注意的是,这里只介绍了抽取表格的实现方式,没有列出样例效果;因为笔者认为这三种各有优劣势(虽然倾向于camelot,更加灵活,输出更加多样),在实际应用中,可以各自尝试,知道优劣,最终选择对自己最有用的工具。
另外,如果是pdf扫描件,需要利用深度学习的方法(进行表格结构识别、单元格识别以及OCR文本识别)进行表格结构化。


















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











