







0. 前言
深度学习分布式训练任务,就是由多个进程一起协作完成某个模型的训练,这些进程可以运行在单个机器上,也可以运行在多个机器上;可以运行在 CPU Device(设备)上,也可以运行在 GPU、NPU(华为昇腾)、XPU(百度昆仑) Device 上;可以运行在 Host(物理机) 上,也可以运行在 Container(容器)、VM(虚拟机)上。那么,相比于单体训练,分布式训练能带来哪些好处呢?分布式进程是如何启动的呢?这些进程之间需要交互吗?如何给每个进程分配训练任务?本文将带你来一起寻找这些问题的答案。
1. 深度学习如何选择分布式训练框架?
大模型带来的挑战主要有两点:海量样本、参数(万亿级别)和较长的收敛时间。一般来说,单张 GPU A100 显存大小 40G、单台华为 2288H V5 的内存大小能达到上百 G,所以大模型的训练得借助多机多卡,但是随着机器数的增加,收益却不能带来线程增长,这主要是机器间通信开销指数增加,分布式训练还得保证一定的多卡加速比。
大模型主要分为两类:一是搜索、推荐、广告类任务,它的特点是海量样本及大规模稀疏参数(sparse embeddings),适合使用 CPU/GPU 参数服务器模式(PS);另一种是 CV、NLP 任务,它的特点是常规样本数据及大规模稠密参数,它适合用纯 GPU 集合通信模式(Collective)。参数服务器模式从第一代 Alex Smola 在 2010 年提出的 LDA(文本挖掘领域的隐狄利克雷分配模型),到第二代 Jeff Dean 提出的 DistBelief,接着到第三代李沐提出的相对成熟的现代 Parameter Server 架构,再到后来的百花齐放:Uber 的 Horvod,阿里的 XDL、PAI,Meta 的 DLRM,字节的 BytePs、美团基于 Tensorlow 做的各种适配等等。参数服务器的功能日趋完善,性能也越来越强,有纯 CPU、纯 GPU,也有异构模式。另一方面,基于纯 GPU 的集合通信模式的分布式训练框架,伴随着 Nvidia 的技术迭代,特别是 GPU 通信技术(GPU Direct RDMA)的进步,性能也变得愈来愈强。
AI 模型训练任务流程:初始化模型参数 -> 逐条读取训练样本 -> 前向、反向、参数更新 -> 读取下一条样本 -> 前向、反向、参数更新 -> … 循环,直至收敛。
在软件层面的体现就是计算机按顺序运行一个个 OP(计算单元,可以理解为函数)。假如一个大模型的 OP 总数为n,第 i个 OP 的输入、输出变量、参数、优化器中间状态变量个数总共为mi ,训练单条样本需要的算力为 ci Flops(浮点运算次数),那么需要存储的累计变量个数为 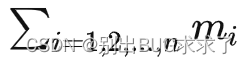
,所需总算力为 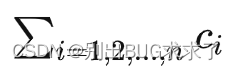
,同时考虑到不同 OP 之间的存储、算力需求差异很大,比如有的 OP 需要消耗巨大的存储能力,却只要很少的算力,而有的 OP 需要巨大的算力,却对存储的要求很低。第i个 OP 和第j 个OP 之间的通信开销(带宽和时延)标识为k_i,j . 从数学上看,如果给定固定数量的 CPU、GPU 机器卡数,那么在存储资源利用率λ、算力资源利用率η 、最短训练时间γ等指标上通过凸优化理论可以取得(近似)最优解。
然而,即使从数学原理上求出了最优的参数和 OP 放置策略,从工程实践上看,实现复杂度非常高且几乎无法复用(对于一个新来的大模型),这是由深度学习框架的实现原理决定的。我们再来看看市面上已有的分布式策略,比如:
- 数据并行:最容易理解,海量训练样本切分到不同机器上,传统的参数服务器模式是典型代表
- 模型并行:把模型本身进行切分,使得每台机器(显卡)上只需要存模型的一部分,实现方式多种多样:
- 只切分模型参数
- 只做模型的简单横向切分,一个 Layer 切成多个 Partition
- 对一个算子进行拆分,比如 FC(全连接层),把参数和计算的切分到多个GPU上,通过通信完成这个原子计算
- 流水线并行:老生常谈了,通过划分 micro batch 让计算机在通信的时候不要停止计算
- Sharding:可以理解为是比较易用的模型并行,主要是参数、梯度、优化器状态切分到不同机器(显卡)
- Offload:巨量稀疏参数卸载到 SSD、Host 内存、HBM(显存)等,采用多级存储架构;而对于稠密参数,则需要借用混合精读
- Recompute:用时间换空间的思想,即在前向时只保存部分中间结果,在反向时重新计算没保存的部分
混合并行:上述能用的并行策略全用上
上述这些并行策略有哪些特点呢?比较容易想到,但是实施起来,有一定开发量且难以复用。这里,我再补充一条,就是 C++ 软件层面本身的性能优化,涉及到代码优化、执行流程优化、iCache、iTable、PGO 等优化,预计在训练速度上至少有 10% 的提升,而且对每个模型基本都有效。但是,很少看到有人这样干过。一方面原因是相比于宏观层面的并行策略能带来巨大的性能提升,这部分的性能提升点显得很小;另一方面原因,也可能是能够做到软件性能极致优化(结合操作系统和编译器)的专业人才在 AI 领域是稀缺的。
从个人经验来看,如果按数学上最优的策略来执行分布式训练任务,能带来大约 30% 的成本降低和碳排放(对应的绝对成本降低可大了去了),能节省巨大的人力开发成本,而且使得模型能够快速收敛、上线并快速迭代。想要达成这一目标,我们要从哪些方向着手呢?这里先卖个关子,先看看现有的分布式训练框架的运行机制。
2. 深度学习分布式训练框架的运行机制
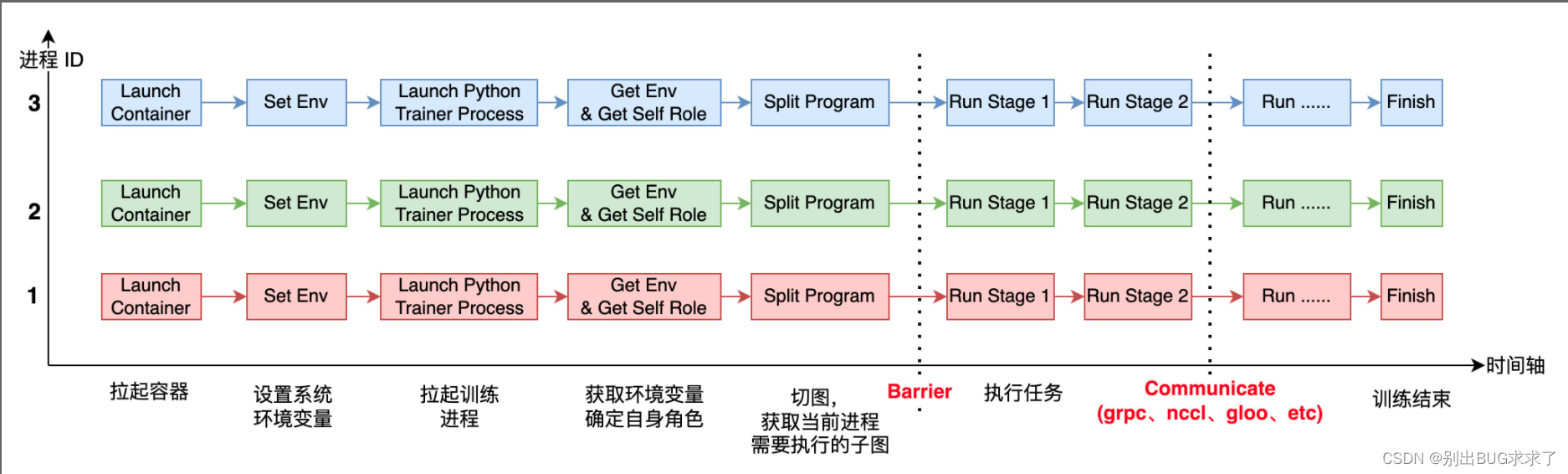
上图表示的是 3 个进程(运行在容器里)一起协作来完成 AI 模型的分布式训练。
每个进程启动后,它需要感知自己全局的进程数( world_size)及自身的进程 ID(或者 rank_id),由于每个进程上运行的都是同一份训练脚本,所以得事先在每个进程所在的系统上设置不同的环境变量,进程运行起来之后,就可以获取环境变量,从而确定自己的角色(Worker、PServer、Coordinator 等)及rank_id、world_size 等信息。
在运行过程中,还有两个重要的环节是 Barrier 和 Communicate. Barrier 的目的是为了实现进程间同步,比较成熟的开源项目有 gloo、mpi 等。Communicate 操作就是实现通信,满足进程间数据交换需求。通信可以在同类型硬件之间发生,比如 CPU 到 CPU、GPU 到 GPU,也可以发生在不同硬件之间,比如 GPU 到 CPU,通信后端也有多种形式,比如 grpc、nccl、socket 等。
3. 深度学习分布式训练框架的理想形态
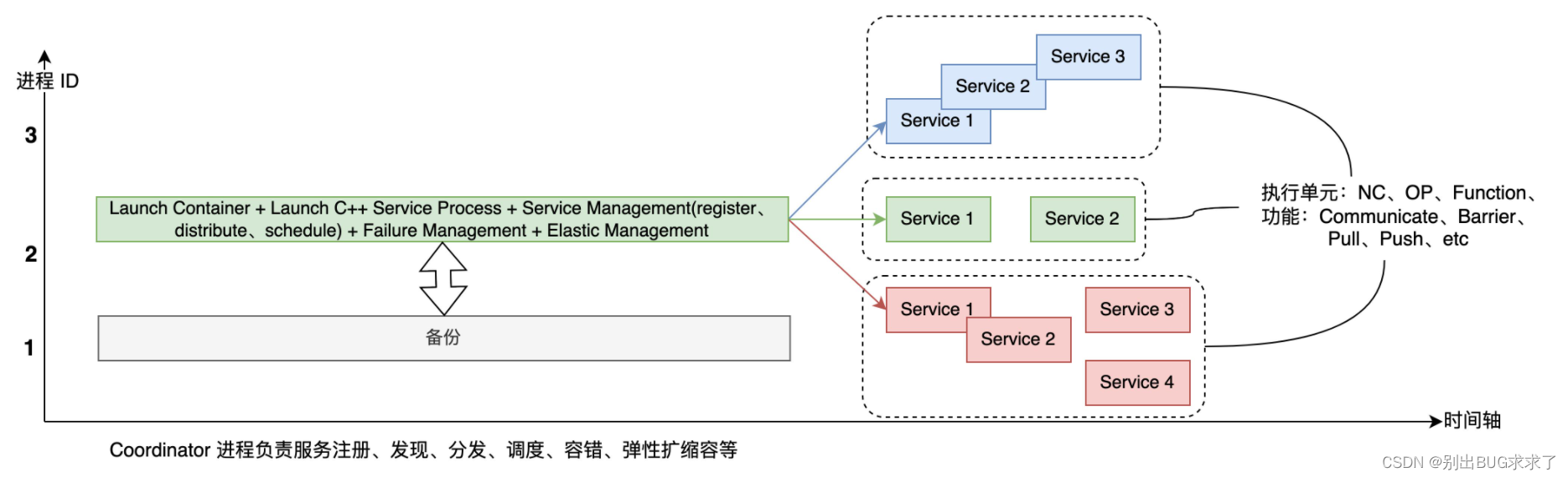
上一节中提到的深度学习分布式框架是当前主流的实现,如 Tesorflow、Pytorch、Paddle 等,它的一大优点是开发起来比较容易,能快速部署。然而,它的扩展性较差,也无法满足最优的调度部署要求。于是,参考云原生的架构,这里我提出了分布式训练框架的一种理想形态(上图)。同一种颜色的服务运行在同一个进程里,它们可以是顺序执行,也可以是并行执行的,可以运行在协程上,也可以运行在线程里,可以采用"去中心化"或者是"有中心化"的基于事件的调度策略。
首先,有一个集中的切图、调度中心、服务管理模块,用户可以自定义各种切图策略、调度算法及服务管理策略。其次,训练任务完全微服务化(Service),从执行单元上来看,这里的 Service 可以是 Nerual Cell(OP 之上的概念,比如一个 Encoder、Decoder 模块),也可以是 OP,还可以是其他 Function(函数);从功能上来说,这些 Service 可以是通信相关、Barrier 相关、也可以是 Push、Pull 相关。那么从当前的深度学习分布式训练框架演进到下一代,需要做哪些工作呢?
- 框架的运行大脑 - Coordinator
- 自动切图策略,这里包括一些具体的优化算法,如 allreduce fuse 等
- C++ 后端代码服务化,去耦合,无状态改造
- 统一的通信前端接口,支持多样的后端
用户在提交大模型的训练任务时,只需要提供一个可用资源规格列表、训练样本及模型组网图,剩下的事就可以全交给框架了。新一代的分布式深度学习训练框架带来的好处是显而易见的:
- 为执行理论最优的调度策略提供了框架支持,从而最大化经济效益
- 参数服务器模式和集合通信模式大一统
- 用户上手成本更低、便于二次开发
- 零成本迁移云上部署
- 用户组网时,不需要一行一行写 OP,也可以直接组装 Service(Python 端表示),能支持大一统之后的神经网络架构
















 728
728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











