







前言
最近学习机器学习。决策树一节有两个核心概念:信息量和信息熵。查了一些资料,将理解记录在此。
信息量
试着将世界上的一些习以为常的东西量化,是提高生活效率和质量的一大核心方式。和人聊天,看电影,战争…每件事中都有着信息这一抽象概念。能把这一概念量化,用数字去衡量的话,就能用科学方法提高管理利用信息的效率了。信息论就是在做这样一件事。
但是将信息量化,该怎么选择公式,要基于信息的特点:
- 信息量是正数(不然还能偷走信息)
- 信息量可以相加(比如一句话含有信息量3,另一句含有信息量2,两句话一共就含有信息量5,而不是3或7)
- 某件事的信息量和这件事发生的概率的关系可以用连续函数来表示(比如假设月球撞地球概率为
0.000001%,我现在肚子很饿的概率为99%,那么前者对应信息量大,后者对应信息量小) - 一件事情,可能的结果的数量越多,这件事含有的信息量越大(比如蒙答案时,单选题的信息量没有多选题大,因为多选题有更多的可能的选择组合)
那么对数函数y = -log(x)在底数大于1时,就能很好的符合信息的这些特性:
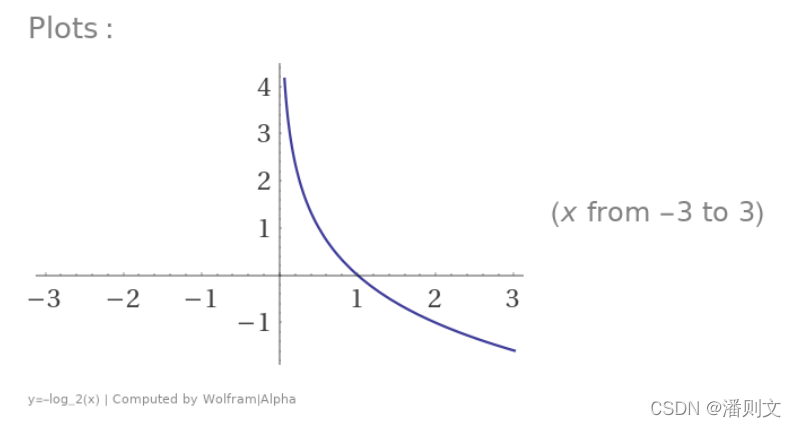
- 一件事发生的概率在0-1之间,x表示概率的话,
-log(x)是正数 - 两件事分别发生的概率是
a和b,信息量为-log(a)和-log(b),同时发生的话信息量为-log(ab) = -log(a) + -log(b) x表示概率的话,log(x)确实是连续的函数,每种概率都对应一个信息量- 假设一件事有n种等可能的结果,n越大,每种结果代表的信息量
-log(1/n)也越大(因为得知结果后,排除了更多的错误的答案)
信息熵
信息熵是用来衡量一件事,平均而言,能给我们带来的信息量的多少。是信息量的期望。
因为现实生活中,一件事的不同结果发生的概率不同,带来的信息量也有所不同,那么对这些结果的信息量加权平均,就能估量一件事背后的信息量大小了(比如月球撞地球和到了饭点肚子饿)。
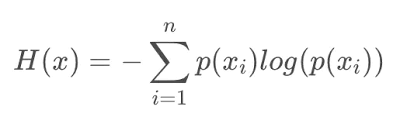
信息增益
信息增益,是得知了一个信息后,信息的不确定性减少的程度。用来衡量得知的这个信息的价值。
基于上面两个概念,某件事中,一个结果的信息量,减去这件事的信息量期望,得到的就是得知这个结果后,我们所获得信息增益。
决策树中,有时就是用这个指标,来选择用来决策的特征的。

















 1308
1308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









