





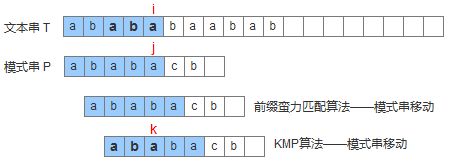
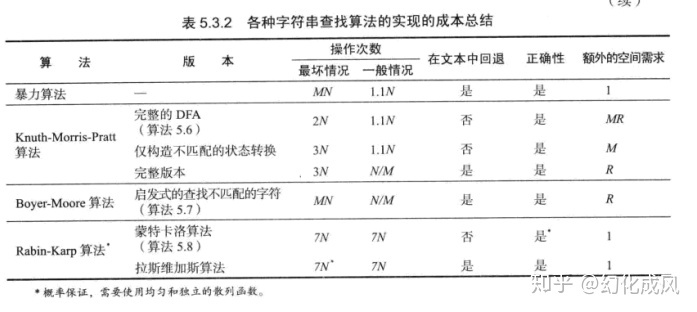
暴力子字符串查找算法
对于字符串txt和子字符串pat,判断txt中是否包含pat,如果有找出pat的位置。
一般的思路是从txt的字符0-n与pat的字符0-m进行匹配,如果遇到不匹配的字符,再从txt的字符1-n与pat的字符0-m进行匹配,直到pat的字符都匹配了或txt的字符都遍历完了。代码如下:
public static int search1(String pat, String txt) {
int m = pat.length();
int n = txt.length();
for (int i = 0; i <= n - m; i++) {
int j;
for (j = 0; j < m; j++) {
if (txt.charAt(i+j) != pat.charAt(j))
break;
}
if (j == m) return i; // found at offset i
}
return n; // not found
}
还有一种思路是用于遍历txt的索引i和遍历pat的索引j一起递增,当出现不匹配的字符时,j设成0,i回退到i-j的位置。代码如下
// return offset of first match or N if no match
public static int search2(String pat, String txt) {
int m = pat.length();
int n = txt.length();
int i, j;
for (i = 0, j = 0; i < n && j < m; i++) {
if (txt.charAt(i) == pat.charAt(j)) j++;
else {
i -= j;
j = 0;
}
}
if (j == m) return i - m; // found
else return n; // not found
}
这两种算法都称为暴力子字符串查找,时间复杂度是O(nm)
KMP算法
而KMP算法的思路是不回退i,记录当txt[i]和pat[j]不匹配时,txt[i+1]应该从pat的第几个字符开始进行匹配,用j记录。
例如txt=ABABAC, 当pat=AC时,i=1,j=1时出现不匹配,此时txt[i+1]=txt[2]应该从pat[0]开始匹配,修改j=0
当pat=ABAC时,i=3,j=3时出现不匹配,此时txt[i+1]=txt[4]应该从pat[2]开始匹配,修改j=2,因为前面两个字母已经匹配了。
KMP算法利用确定有向状态自动机(DFA)记录txt[i]对应的pat[j],示意图如下:
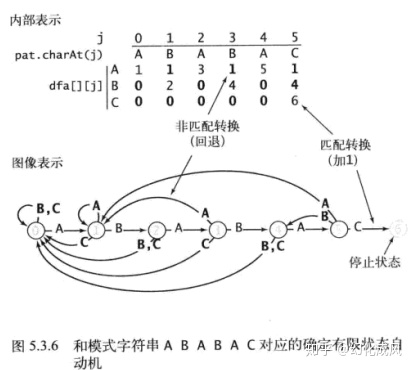
pat=ABABAC,当匹配j=0时,若txt[i]=A,则txt[i+1]对应pat[1],j=1,从pat的1位置开始匹配
若txt[i]=B或C或其他字符,则txt[i+1]对应pat[0],j=0,从pat的0位置开始匹配
当匹配到j=1时,若txt[i]=B,则txt[i+1]对应pat[2],j=2,从pat的2位置开始匹配
若txt[i]=A,则txt[i+1]对应pat[1],j=1,从pat的1位置开始匹配,因为第一个字母A已经匹配了
若txt[i]=C或其他字符,则txt[i+1]对应pat[0],j=0,从pat的0位置开始匹配
代码如下
public class KMP {
private final int R; // the radix
private int[][] dfa; // the KMP automoton
private char[] pattern; // either the character array for the pattern
private String pat; // or the pattern string
//根据pat算出对应的DFA
//示意图如下
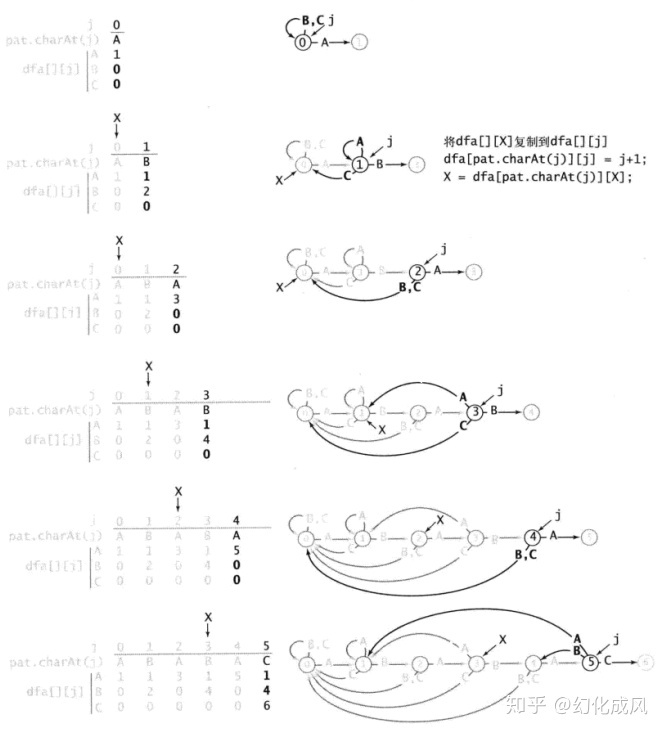
public KMP(String pat) {
this.R = 256;
this.pat = pat;
// build DFA from pattern
int m = pat.length();
dfa = new int[R][m];
dfa[pat.charAt(0)][0] = 1;
for (int x = 0, j = 1; j < m; j++) {
//计算当txt[i]与pat[j]对比时,若txt[i]=c,则匹配下个字符txt[i+1]时对应的pat中j的位置,存储在dfa[c][j]
//j的位置实际就是txt[i-j]到txt[i]对应字符串前后缀的公共最长子串
//如txt=ABABAC,pat=ABAC,当第1次匹配失败时i=j=3,txt[i-j]到txt[i]对应ABAB,他的前缀是{A,AB,ABA},后缀是{B,AB,BAB},他们的公共最长子串是AB,长度为2,所以j=2。
//i=4时与j=2对比,txt[4]与pat[2]对比
//当txt[i]与pat[j]匹配时,j=j+1,不匹配时j的位置=dfa[c][x], 从DFA的构造示意图中可以看出x正好是dfa[pat.charAt(j)][x]
for (int c = 0; c < R; c++)
dfa[c][j] = dfa[c][x]; // 复制匹配失败情况下的值
dfa[pat.charAt(j)][j] = j+1; // 设置匹配成功情况下的值
x = dfa[pat.charAt(j)][x]; // 更新重启状态
}
}
//根据构造的DFA在字符串txt中查找pat
public int search(String txt) {
// 在txt上模拟DFA的运行
int m = pat.length();
int n = txt.length();
int i, j;
//dfa[txt[i]][j]存储的是检查txt[i+1]时pat中j应该对应的位置
//所以如果txt[i]!=pat[j],则j = dfa[txt.charAt(i)][j],根据DFA回退j到合适的位置
//如果txt[i]=pat[j],则dfa[txt[i]][j]=j+1,j=j+1, 当一直匹配j最终等于m,匹配成功
//或者i >=n 匹配失败
for (i = 0, j = 0; i < n && j < m; i++) {
j = dfa[txt.charAt(i)][j];
}
if (j == m) return i - m; // found
return n; // not found
}
改进版KMP算法
前面的KMP算法空间复杂度是字母表R的大小,下面改进的KMP算法空间复杂度是pat的长度m。
构造NFA时,若txt[i]与pat[j]不匹配,i不加1,只回退j的值,记录下次txt[i]应该对应的pat中的索引newj,保存在next[j]中,而newj的值正好是pat[0]到pat[j-1]对应字符串前后缀的公共最长子串,所以不需要知道txt[i]的值。
例如txt=ABABAC,pat=ABAC,当第1次匹配失败时i=j=3,pat[0]pat[j-1]对应ABA,他的前缀是{A,AB},后缀是{A,BA},他们的公共最长子串是A,长度为1,所以newj=1。newj=next[j]=1,下次txt[3]与pat[1]对比。
public class KMPplus {
private String pattern;
private int[] next;
// create Knuth-Morris-Pratt NFA from pattern
//ABAC
//next数组计算流程,官方版本
// public KMPplus(String pattern) {
// this.pattern = pattern;
// int m = pattern.length();
// next = new int[m];
// int j = -1;
// for (int i = 0; i < m; i++) {
// if (i == 0) next[i] = -1;
// else if (pattern.charAt(i) != pattern.charAt(j)) next[i] = j;
// else next[i] = next[j];
// while (j >= 0 && pattern.charAt(i) != pattern.charAt(j)) {
// j = next[j];
// }
// j++;
// }
//
// for (int i = 0; i < m; i++)
// StdOut.println("next[" + i + "] = " + next[i]);
// }
//next数组计算流程,版本2,可以理解为在txt=pat中查找pat本身的过程,初始i=0,j=-1,
//j=-1表示txt[i]与pat[0]匹配失败,i和j都要++
public KMPplus(String pattern) {
this.pattern = pattern;
int m = pattern.length();
next = new int[m+1];
next[0] = -1; //表示txt[i]与pat[0]匹配失败,i和j都要++,都从下个字符开始匹配
int i = 0, j = -1;
//例如pat=ABAC
//i=0,j=-1时,next[1]=0
//i=1=B,j=0=A时,j = next[j]=-1
//i=1=B,j=-1时,next[2]=0
//i=2=A,j=0=A时,next[3]=1
//i=3=C,j=1=B时,j = next[j]=0
while (i < m)
{
//j表示上次匹配后pat的新位置,j=-1表示i和j都要++,都从下个字符开始匹配
if (j == -1 || pattern.charAt(i) == pattern.charAt(j))
{
++i;
++j;
//next[i]就是i之前已经匹配的字符个数,也是在pat[i]匹配失败时下个pat的位置
next[i] = j;
}
else
j = next[j]; //获取匹配失败时,下个pat的位置j
}
for ( i = 0; i < m; i++)
System.out.println("next[" + i + "] = " + next[i]);
}
// simulate the NFA to find match
public int search(String text) {
int m = pattern.length();
int n = text.length();
int i, j;
for (i = 0, j = 0; i < n && j < m; i++) {
//当txt[i]与pat[j]不匹配时,i不动,根据next数组回退j的值
while (j >= 0 && text.charAt(i) != pattern.charAt(j))
j = next[j];
j++;
}
if (j == m) return i - m;
return n;
}
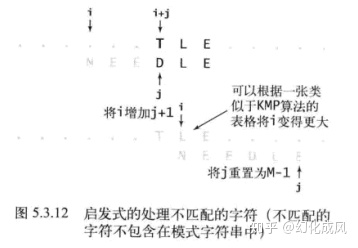
BoyerMoore算法
BoyerMoore算法是从模式字符串pat的右边开始匹配pat的每个字符,
例如在字符串txt=FINDINAHAYSTAKCNEEDLE中查找pat=NEEDLE,示意图如下

先拿txt中位置5的字符N跟pat的最后一个字符E比较,不匹配,移动i到位置5字符N的位置,因为N包含在pat中,再拿txt中位置10的字符S跟pat的最后一个字符E比较,不匹配,移动i到位置11字符T的位置,直到最后匹配到pat,代码如下
public class BoyerMoore {
private final int R; // the radix
private int[] right; // the bad-character skip array
private char[] pattern; // store the pattern as a character array
private String pat; // or as a string
public BoyerMoore(String pat) {
this.R = 256;
this.pat = pat;
//用right数组记录字母表中的每个字符在pat中的最右位置,如果不在pat中则返回-1
right = new int[R];
for (int c = 0; c < R; c++)
right[c] = -1;
for (int j = 0; j < pat.length(); j++)
right[pat.charAt(j)] = j;
}
//在匹配失败时,根据txt中匹配失败的字符在right数组中的位置决定i移动的位置,
//如果匹配失败的字符不包含在pat中,i增加j+1,就是移动i到j+1的位置,
//如果匹配失败的字符包含在pat中,i增加 j - right[txt.charAt(i+j)],让i处的字符与pat中最右边该字符的位置对齐,
//如果这样i无法增加,则将i加1,
//示意图如下

public int search(String txt) {
int m = pat.length();
int n = txt.length();
int skip;
for (int i = 0; i <= n - m; i += skip) {
skip = 0;
for (int j = m-1; j >= 0; j--) {
if (pat.charAt(j) != txt.charAt(i+j)) {
skip = Math.max(1, j - right[txt.charAt(i+j)]);
break;
}
}
if (skip == 0) return i; // found
}
return n; // not found
}
RabinKarp算法
RabinKarp算法是一种基于散列的字符串查找算法,通过散列函数将长度为M的模式字符串pat转成散列值,然后取文本txt中所有可能长度为M的字符串通过相同的散列函数转成散列值与pat的散列值进行比较,如果相同再比较每个字符是否相同。示意图如下
在文本txt=3141592653589793中查找pat=26535
字符串中的每个字符相当于R进制的数字,pat相当于M位的R进制数

如果用一般的散列函数这种做法会比暴力子字符串算法慢很多,而RabinKarp算法可以在常数时间内算出M个字符的散列值,代码如下
public class RabinKarp {
private String pat; // the pattern // needed only for Las Vegas
private long patHash; // pattern hash value
private int m; // pattern length
private long q; // a large prime, small enough to avoid long overflow
private int R; // radix
private long RM; // R^(M-1) % Q
public RabinKarp(String pat) {
this.pat = pat; // save pattern (needed only for Las Vegas)
R = 256;
m = pat.length();
q = longRandomPrime();
// precompute R^(m-1) % q for use in removing leading digit
RM = 1;
for (int i = 1; i <= m-1; i++)
RM = (R * RM) % q;
patHash = hash(pat, m);
}
// Compute hash for key[0..m-1].
private long hash(String key, int m) {
long h = 0;
for (int j = 0; j < m; j++)
h = (R * h + key.charAt(j)) % q;
return h;
}
// Las Vegas version: does pat[] match txt[i..i-m+1] ?
private boolean check(String txt, int i) {
for (int j = 0; j < m; j++)
if (pat.charAt(j) != txt.charAt(i + j))
return false;
return true;
}
public int search(String txt) {
int n = txt.length();
if (n < m) return n;
//取0到m-1间的字符串计算散列值
long txtHash = hash(txt, m);
//进行一次比较
if ((patHash == txtHash) && check(txt, 0))
return 0;
// check for hash match; if hash match, check for exact match
//快速计算txt中每个长度为m的子字符串的散列值进行匹配比较
for (int i = m; i < n; i++) {
// Remove leading digit, add trailing digit, check for match.
txtHash = (txtHash + q - RM*txt.charAt(i-m) % q) % q;
txtHash = (txtHash*R + txt.charAt(i)) % q;
// match
int offset = i - m + 1;
if ((patHash == txtHash) && check(txt, offset))
return offset;
}
// no match
return n;
}
// a random 31-bit prime
private static long longRandomPrime() {
BigInteger prime = BigInteger.probablePrime(31, new Random());
return prime.longValue();
}















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









