







摘要:机器学习任务中最核心的工作是对构造合适的损失函数,并对其进行优化,得到最终的模型。那么如何来构造损失函数,常用的构造函数背后有哪些理论的支撑,本篇文章从熵的角度来解析,希望对对读者起到抛装引玉的作用。
一、 基础概念
信息量
对于离散概率,定义p_i的信息量为
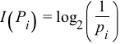
可以理解为需要查找多少次可以找到对应的离散值,比如概率0.125,对应的信息量是3,也就是说需要至少折半查找3次才能找到对应的离散取值。
信息熵(Information entropy)
衡量信息的不确定性(对于人来说),熵越小,信息就越确定。通俗的说,可以从几个方面来描述,比如人判断一件事情时有把握的程度、信息压缩编码时最小需要的位数。简单的说,熵反应了信息量。定义如下
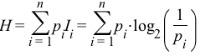
交叉熵(Cross Information entropy)
如果一件事情的不确定性为0,那么信息熵也为0,所以信息熵可以理解为消除事件不确定性所要付出的代价,而实际当中很难采用最真实的概率分布来对事件进行判断,而是采用一种接近真实的概率分布,比如q来拟合真实的场景,将q带入信息熵的公式就可以得出交叉熵的定义
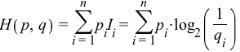
交叉熵所代表的含义是,采用非真实概率分布q下,要消除事件的不确定性所付出的代价,通常情况下,交叉熵要比信息熵大,证明的方法可参考Gibbs inequality
相对熵(relative Information entropy)
交叉熵减去信息熵即是相对熵的定义
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2206
2206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









