






“
阅读本文大概需要 5 分钟。
”大家好,我是大鹏,城市数据团联合发起人,致力于 Python 数据分析、数据可视化的应用与教学。
和很多同学接触过程中,我发现自学 Python 数据分析的一个难点是资料繁多,过于复杂。大部分网上的资料总是从 Python 语法教起,夹杂着大量 Python 开发的知识点,花了很多时间却始终云里雾里,不知道哪些知识才是真正有用的。本来以为上手就能写爬虫出图,却在看基础的过程中消耗了一周又一周,以至于很多励志学习 Python 的小伙伴牺牲在了入门的前一步。

于是,我总结了以下一篇干货,来帮助大家理清思路,提高学习效率。总共分为三大部分:做 Python 数据分析必知的语法,如何实现爬虫,怎么做数据分析。
1.必须知道的两组 Python 基础术语
A.变量和赋值
Python 可以直接定义变量名字并进行赋值的,例如我们写出 a = 4 时,Python 解释器干了两件事情:
在内存中创建了一个值为 4 的整型数据
在内存中创建了一个名为 a 的变量,并把它指向 4
用一张示意图表示 Python 变量和赋值的重点:
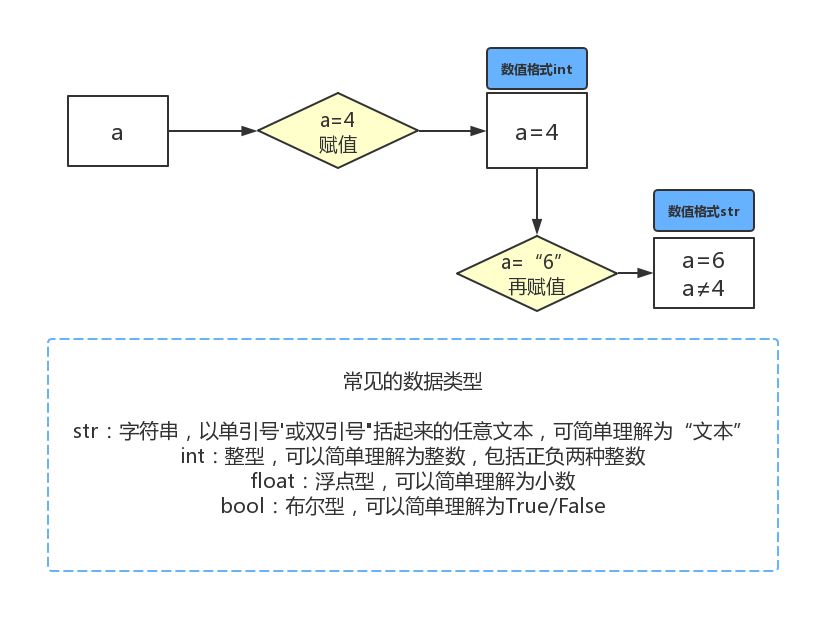
例如下图代码,“=”的作用就是赋值,同时 Python 会自动识别数据类型:
#整型数据B.数据类型
在初级的数据分析过程中,有三种数据类型是很常见的:
列表 list(Python 内置)
字典 dict(Python 内置)
DataFrame(工具包 pandas 下的数据类型,需要 import pandas 才能调用)
它们分别是这么写的:
列表(list):
#列表
liebiao=[1,2.223,-3,'刘强东','章泽天','周杰伦','昆凌',['微博','B站','抖音']]list 是一种 有序 的集合,里面的元素可以是之前提到的任何一种数据格式和数据类型(整型、浮点、列表……),并可以随时指定顺序添加其中的元素,其形式是:
#ist是一个可变的有序表,所以,可以往list中追加元素到末尾:
liebiao.append('瘦')
print(liebiao)
#结果1
>>>[1, 2.223, -3, '刘强东', '章泽天', '周杰伦', '昆凌', ['微博', 'B站', '抖音'], '瘦']
#也可以把元素插入到指定的位置,比如索引号为5的位置,插入“胖”这个元素:
liebiao.insert(5,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8172
8172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









