









看了好多代码,目前为止都是散乱的分享,接下来将整理作为专题,进行系统化的一个分享整理,也是我自己学习的过程。第一个的系统化的分享专题——python办公自动化。代码后面的#所表示的是注释,对本行代码进行解释的内容,用#号开头是让程序理解这是注释不需要运行的意思。
本模板旨在分享和解读完整代码,只要你有安装配置好python环境,在pycharm里安装相应的第三方文件库,黏贴代码即可运行,我会尽量在代码后面都进行标注解读。我们以实用型为目的学习。编程类学习,从模仿中掌握突破。需要python教学视频和资料的在公众号菜单栏获取,有任何问题欢迎公众号后台联系我或加我微信。python安装教程
注:import后导入的模块需要单独安装,有些是自带的,但是要实现更复杂的功能一般是安装第三方模块。安装方法:
1.win+r,调出命令提示窗口,输入cmd再按回车键。
2.输入安装指令(电脑要联网,推荐使用国内镜像网站,安装更快,不然很慢)
Python pip安装第三方库的国内镜像
Windows系统下,一般情况下使用pip在DOS界面安装python第三方库时,经常会遇到超时的问题,导致第三方库无法顺利安装,此时就需要国内镜像源的帮助了。
使用方法如下:
例如:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xxx(这里的xxx是模块名),这样就会从清华这边的镜像去安装pyspider库。

PyPDF2 官网:https://pythonhosted.org/PyPDF2/
* PyPDF2 可以更好的读取、写入、分割、合并 PDF 文件;
* pdfplumber 官网:https://github.com/jsvine/pdfplumber
* pdfplumber 可以更好地读取 PDF 文件内容和提取 PDF 中的表格;
* 这两个库不属于 python 标准库,都需要单独安装;
1)python提取PDF文字内容
#利用 pdfplumber 提取文字import PyPDF2 #导入模块import pdfplumberwith pdfplumber.open("餐饮企业综合分析.pdf") as p:workbook=openpyxl.load_workbook("DataSource\Economics.xlsx") page = p.pages[2] print(page.extract_text())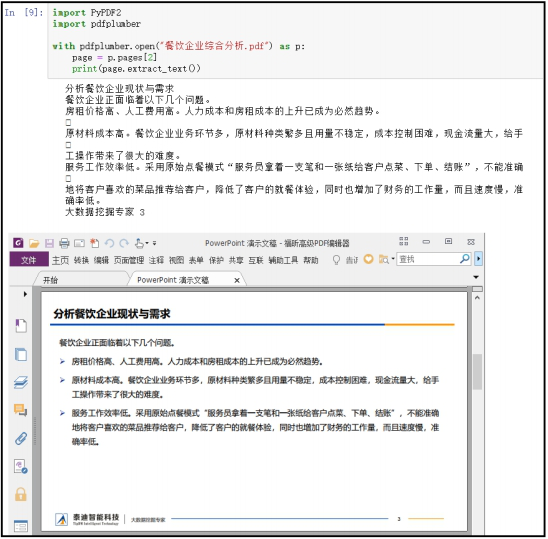
2)利用pdfplumber提取表格并写入excel
* extract_table():如果一页有一个表格;
* extract_tables():如果一页有多个表格;
import PyPDF2import pdfplumberfrom openpyxl import Workbookwith pdfplumber.open("餐饮企业综合分析.pdf") as p: page = p.pages[4] table = page.extract_table() print(table) workbook = Workbook() sheet = workbook.active for row in table: sheet.append(row workbook.save(filename = "新 pdf.xlsx")
结果如下
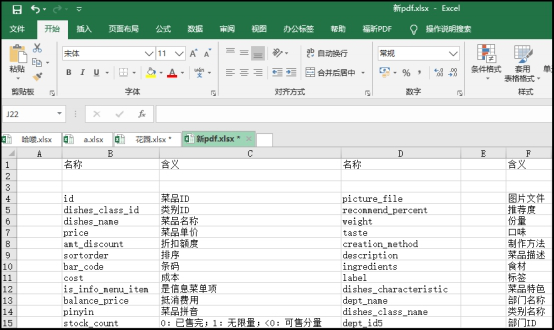
缺陷:可以看到,这里提取出来的表格有很多空行,怎么去掉这些空行呢?
判断:将列表中每个元素都连接成一个字符串,如果还是一个空字符串那么肯定就是空行。
import PyPDF2import pdfplumberfrom openpyxl import Workbookwith pdfplumber.open("餐饮企业综合分析.pdf") as p: page = p.pages[4] table = page.extract_table() print(table) workbook = Workbook() sheet = workbook.active for row in table: if not "".join([str(i) for i in row]) == "": sheet.append(row) workbook.save(filename = "新 pdf.xlsx")结果如下:
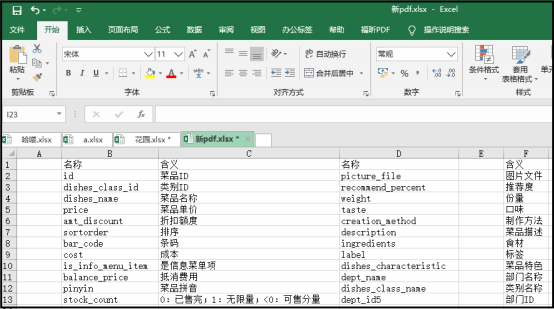

okok,今天的分享到此结束,欢迎各位三连 。长按下方图片关注公众号。
。长按下方图片关注公众号。


















 1924
1924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









