






 本文介绍了TensorBoard在PyTorch中的安装与使用,包括如何创建SummaryWriter,记录标量、直方图、图片数据,以及网络结构图。通过TensorBoard可以直观地可视化模型的训练过程和各种指标。
本文介绍了TensorBoard在PyTorch中的安装与使用,包括如何创建SummaryWriter,记录标量、直方图、图片数据,以及网络结构图。通过TensorBoard可以直观地可视化模型的训练过程和各种指标。
一、tensorboard介绍
我装的pytorch的版本更新到1.6,我用conda一键命令安装pytorch会自动装好tensorboard。如果电脑没有装,可以通过pip install tensorboard进行安装。
使用tensorboard我们可以将模型和一些指标记录到一个日志文件中,以便在TensorBoard UI中进行可视化。pytorch模型和张量支持标量、图像、直方图、graphs以及嵌入可视化。
二、tensorboard的使用
2.1创建一个SummaryWriter
常用的两种初始化SummaryWriter的方法:
writer1 = SummaryWriter('runs/exp')
writer2 = SummaryWriter()
有了这些日志文件,可以通过在终端中输入tensorboard --logdir=<your_log_dir>,然后打开网址http://localhost:6007/就可以看到可视化的图片了。
其中的<your_log_dir>既可以是单个 run 的路径,如上面 writer1 生成的runs/exp;也可以是多个 run 的父目录,如runs/下面可能会有很多的子文件夹,每个文件夹都代表了一次实验,我们令--logdir=runs/就可以在 tensorboard 可视化界面中方便地横向比较runs/下不同次实验所得数据的差异
一个实验可以记录很多信息。 为了避免UI混乱并更好地进行结果的展示,我们可以通过对图进行分层命名来对图进行分组。 例如,“Loss/train”和“Loss/test”将被分组在一起,而“Accuracy/train”和“Accuracy/test”将在TensorBoard界面中分别分组。
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()
for n_iter in range(100):
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)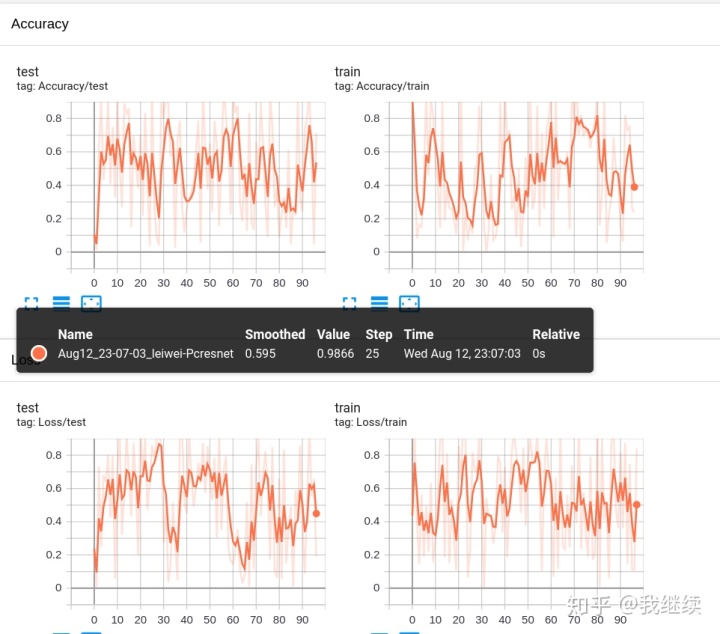
2.2 添加标量数据到summary
add_scalar(tag,scalar_value,global_step=None,walltime=None)
功能:在一个图表中记录一个标量的变化,常用于Loss和Accuracy曲线的记录
参数:
tag(string):图的标题
scalar_value(float or string/blobname):用于保存的值,曲线图的y坐标
global_step(int):记录的训练全局步数。曲线图的x坐标
add_scalars(main_tag,tag_scalar_dict,global_step=None,walltime=None)
功能:在一个图表中记录多个标量的变化,常用于对比。如trainLoss和validLoss的比较等。
参数:
main_tag(string):图标签的父名称
tag_scalar_dict(dict):字典的key是变量的tag,相当于标签的子名称,value是变量的值
global_step(int):记录的训练全局步数。曲线图的x坐标
举例说明:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()
r = 5
for i in range(100):
writer.add_scalars('run_14h', {'xsinx':i*np.sin(i/r),
'xcosx':i*np.cos(i/r),
'tanx': np.tan(i/r)}, i)
writer.close()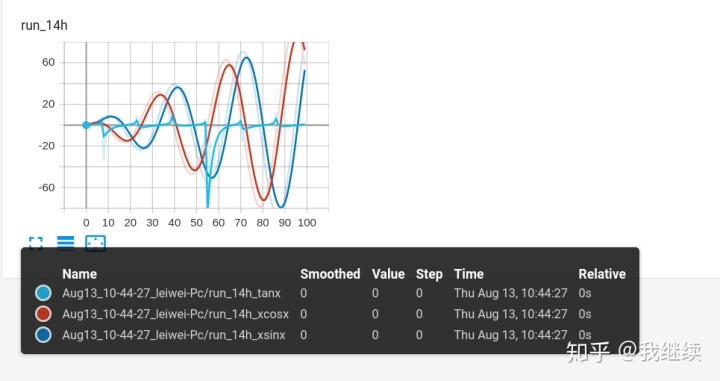
最终生成三个文件夹,文件夹的名字由父名称和子名称组成的

2.3添加直方图数据到summary
add_histogram(tag,values,global_step=None,bins='tensorflow',walltime=None,max_bins=None)
功能:绘制直方图和多分位数折线图,常用于监测权重值和梯度的分布变化情况,便于诊断网络更新是否正确
参数:
tag(string):图的标题
values(torch.Tensor,numpy.array, orstring/blobname):用于建立直方图的值
global_step(int):记录的训练全局步数。
bins(string) – One of {‘tensorflow’,’auto’, ‘fd’, …}.决定如何取bins,默认为‘tensorflow’
举例说明:
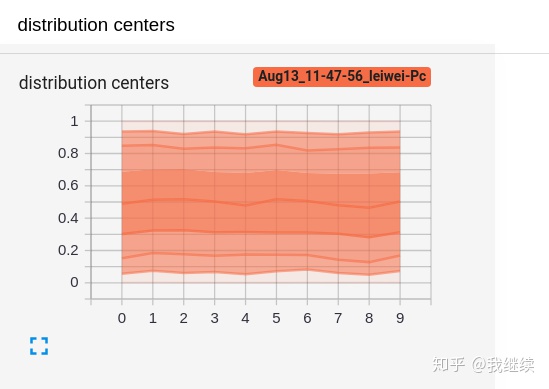
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()
for i in range(10):
x = np.random.random(1000)
print(x)
writer.add_histogram('distribution centers', x , i)
writer.close()
2.4 添加图片数据到summary
add_image(tag,img_tensor,global_step=None,walltime=None,dataformats='CHW')
功能:
绘制图片,可用于检查模型的输入,监测feature map的变化,或者观察weights。
参数:
tag(string):图的标题
img_tensor(torch.Tensor,numpy.array, orstring/blobname):需要可视化的图片数据
global_step(int):记录的训练全局步数.
dataformats:数据格式,默认是CHW。其他格式有'HWC'和'HW'
from torch.utils.tensorboard import SummaryWriter
import numpy as np
img = np.zeros((3, 100, 100))
img[0] = np.arange(0, 10000).reshape(100, 100) / 10000
img[1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
img_HWC = np.zeros((100, 100, 3))
img_HWC[:, :, 0] = np.arange(0, 10000).reshape(100, 100) / 10000
img_HWC[:, :, 1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
writer = SummaryWriter()
writer.add_image('my_image', img, 100)
# If you have non-default dimension setting, set the dataformats argument.
writer.add_image('my_image_HWC', img_HWC, 100, dataformats='HWC')
writer.close()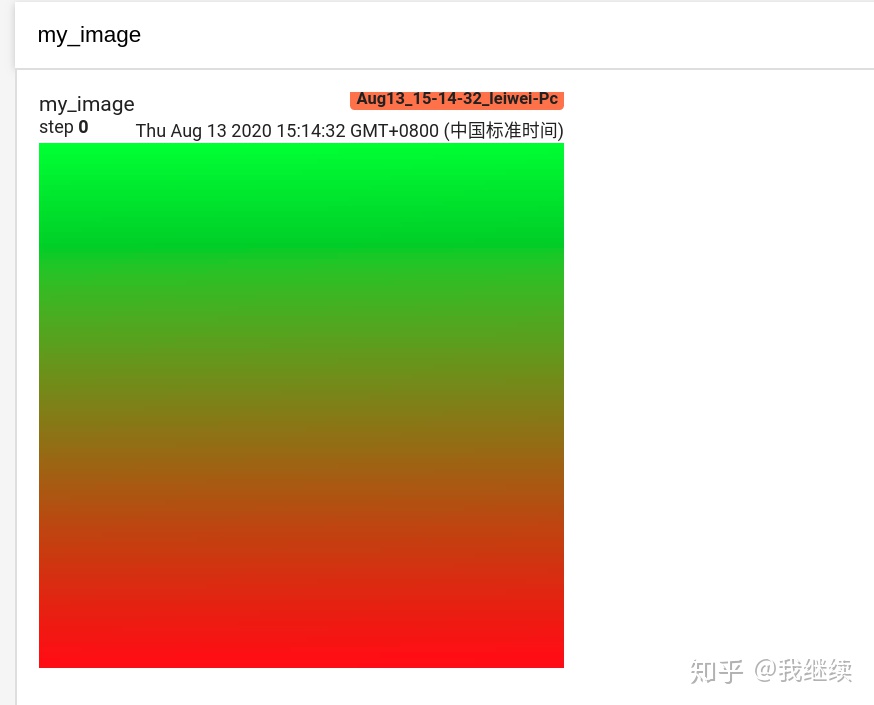
当需要对一个batch大小的图片可视化的时候,要借助下面函数将一组图片拼接成一张图片,便于可视化。
torchvision.utils.makegrid(tensor,nrow=8,padding=2,normalize=False,range=None,scale_each=False,pad_value = 0)
tensor(Tensor or list):需要可视化的数据,shape:(batch, C, H,W)
padding(int):每张图片之间的间隔,默认为2
nrow(int):一行显示几张图,默认为8
normalize(bool):是否进行归一化至[0,1]
range(tuple):设置归一化的min和max,如不设置,默认从tensor中找max和min。
scale_each(bool):每张图片是否单独进行归一化,还是选择所有的图片数据的min和max归一化
pad_value(float):填充部分的像素值,默认为0,填充黑色。
add_images(tag,img_tensor,global_step=None,walltime=None,dataformats='NCHW')
功能:其实和上面的一样,添加一个batch大小的数据给summary
参数:
tag(string):图的标题
img_tensor(torch.Tensor,numpy.array, orstring/blobname)需要可视化的图片数据,有四个维度。
global_step(int):记录的训练全局步数.
dataformats:数据格式,默认是'NCHW'。其他格式有'NHWC'
from torch.utils.tensorboard import SummaryWriter
import numpy as np
img_batch = np.zeros((16, 3, 100, 100))
for i in range(16):
img_batch[i, 0] = np.arange(0, 10000).reshape(100, 100) / 10000 / 16 * i
img_batch[i, 1] = (1 - np.arange(0, 10000).reshape(100, 100) / 10000) / 16 * i
writer = SummaryWriter()
writer.add_images('my_image_batch', img_batch, 0)
writer.close()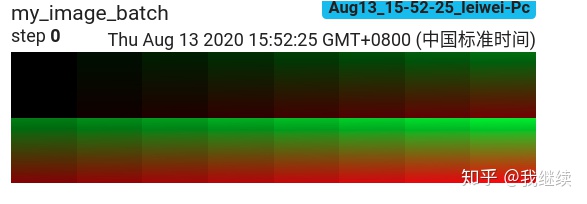
2.4 添加网络结构图到summary
add_graph(model,input_to_model=None,verbose=False)
功能:绘制网络结构拓扑图
参数:
model(torch.nn.Module):模型实例
input_to_model(torch.Tensororlist of torch.Tensor):模型的输入数据,可以选择一个随机数,只要符合shape就可以了。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









