






点击订阅“CAAI认知系统与信息处理专委会”
1. 任务背景
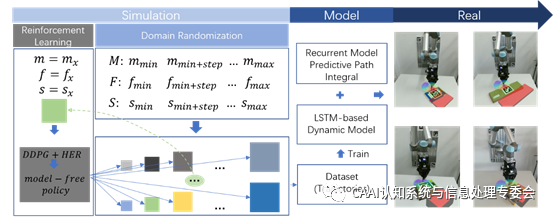
物体的欠驱动推动在机器人灵巧操作任务中一直都是一个研究热点,为物体建立准确的运动预测模型一直都是任务核心问题。基于物理学的力学模型在实际应用中也不够准确和稳定,因为物体的物理属性如接触面摩擦情况和转动惯量等只能近似。而基于统计学的数学模型[1,2]通常需要大量的训练数据,在真实机器人上获取大量数据是一个耗费大量时间和精力的工作。
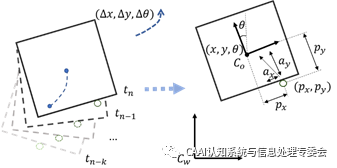
在本篇论文中,我们首先用DDPG强化学习算法[3]在仿真环境中训练一个物体推动策略,用此策略获取物体运动数据,训练一个LSTM网络模型用于拟合物体运动模型。在真实机器人实验中,仿真中训练的循环模型可以通过有限的几步物体-机器人交互信息进行自适应调整,迅速拟合到物体的真实运动模型。在仿真环境获取物体运动数据过程中,使用域随机算法[4,5],改变物体物理属性,获取所有可能的运动轨迹分布。得到物体运动模型之后,进一步提出使用该模型的控制算法Recurrent Model Predictive Path Integral (RMPPI),此算法是在原有MPPI算法(GradyWilliams et al.)基础上通过增加对历史轨迹的记忆缓存,实现了模型在线的参数自适应调整。
 关注公众号,了解最前沿“机器人智能技术”
关注公众号,了解最前沿“机器人智能技术”





----------------------------------------------------------
第四期“机器人智能论坛”如期而至。8月20日下午7点30分,丁汉院士主题报告。第二场德国汉堡大学专场,由三位年轻学者分享机器人智能的最新前沿成果。精彩不断,敬请关注!
关注公众号,了解最前沿“机器人智能技术”















 1711
1711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









