





项目名称:泰坦尼克号生存率预测1.导入数据
这里使用kaggle kernel编写代码
数据下载地址为:https://www.kaggle.com/c/titanic
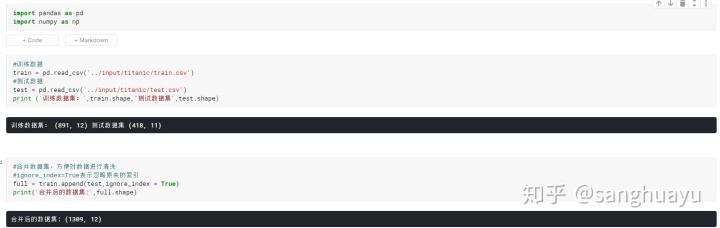
2.数据统计分析
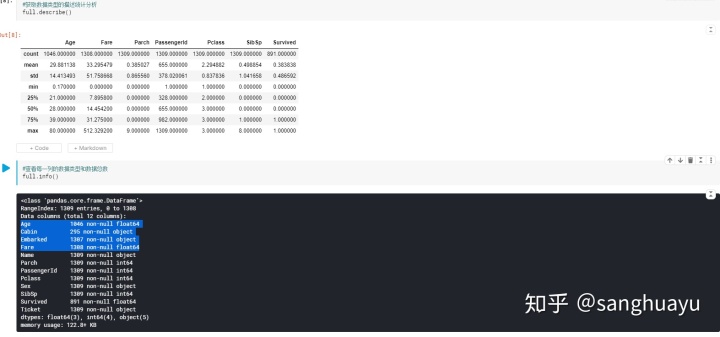
通过describe和info方法,我们可以发现Age,Cabin,Embarked和Fare的数据都有不同程度的缺失,同时Age和Fare的数据存在错误的数据。
3.数据清洗
a)首先对数据类型缺失值的处理
这里使用fiilna方法进行填充,填充值为平均值。

b)字符串类型缺失数据的处理

4.特征提取
数值类型:直接使用
时间序列:转成单独的年、月、日
分类数据:用数值代替类别,One-hot编码
这里分类数据又分为:有类别的以及字符串,有类别的包括Sex,Embarked以及Pclass,字符串则包括:Name,Cabin以及Ticket
分类数据的特征提取:性别

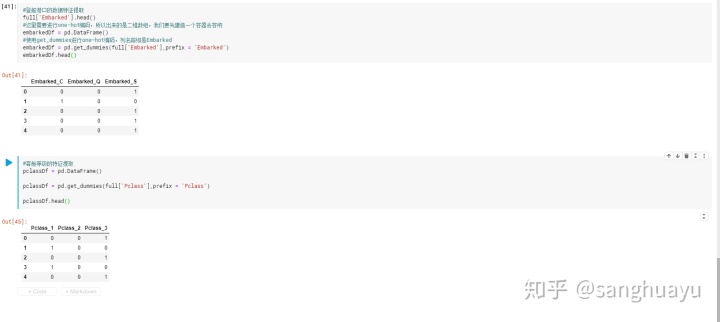
分类数据的特征提取:登船港口,客舱等级
这里使用get_dummies方法来进行one-hot编码
分类数据的特征提取:姓名
先定义一个提取姓名中名称的函数,使用的是split方法

再用map和get_dummies函数进行处理

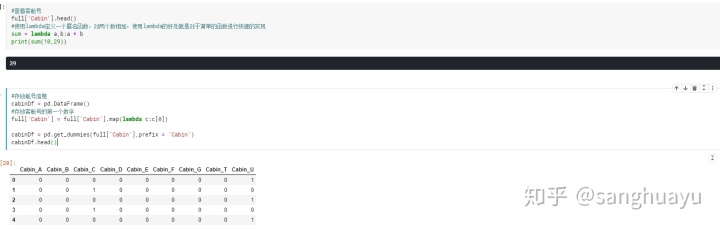
分类数据的特征提取:客舱号
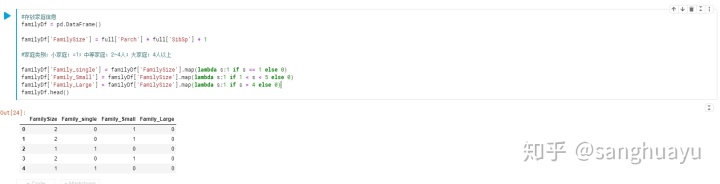
分类数据的特征提取:家庭类别
这里通过分类,将家庭规模分为单个,小家庭以及大家庭并存储至familyDf数据集中
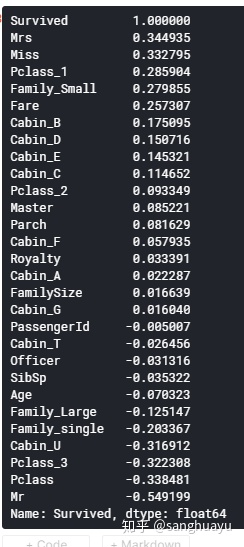
特征选择:使用corr分析各个数据

这里将与生存率有关的相关系数进行降序排列,看看谁与生存率的关系最大
5.构建模型
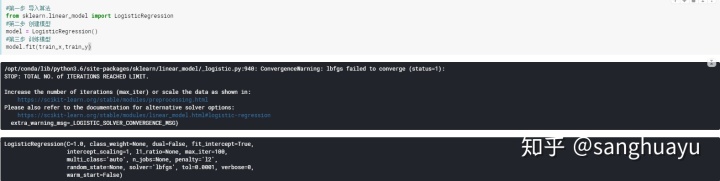
首先使用train_test_split函数用于将矩阵随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签。

再使用LogisticRegression进行逻辑回归的模型进行训练
评估模型:这里使用model.score方法对模型进行评估,最终得到模型的准确率为0.8。

6.方案实施
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









