






本文的订阅号小文章,欢迎加阿猫微信
标准差、Z分数到底是什么鬼??标准差与Z分数的原理与实例介绍 | 心理统计学mp.weixin.qq.com
阿猫同志目前在职读研的专业是应用心理学,2月完成了心理与教育测量学的学习,3月目前在自学心理与教育统计学,每日上班+学习的充实生活,让我想说一句

心理测量学需要有心理统计学基础,当时阿猫在学习常模参照测验时,就面临了对测验的原始分数要转换为标准分数(Z分数)的内容不甚了解的窘境,当时阿猫是是这样的

由于当时不太理解标准差和Z分数的原理,只了解标准差的公式和Z分数的公式,粗略得了解它们在测量学中的应用,就标记了问号以便在后续统计学的学习中进行额外关注。
接下来在3月学习统计学的差异量数时,额外关注了标准差和Z分数的知识,当时自己研究了很久后就继续学习后面的推论统计,发现这两个概念又不是很清晰了,诶?我不是当时看懂了么?什么情况?

紧接着阿猫使出了吃鱼挑刺的劲头,仔细研究后才发现当时以为自己看懂了,其实不然。
由于标准差和Z分数非常重要,尤其标准差是推论统计的基础,所以阿猫非常认真对待,仔细把标准差和Z分数的原理都梳理了一遍,在这里进行一个简单的介绍,由于个人知识水平有限,如果有理解的偏差,还请不吝赐教。
以下直奔主题,内容以提问形式进行展开:

首先,我们先看下标准差的计算公式,这里需要有平均数的基础知识,但不再进行描述。
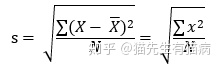
式中s为标准差,X为某组数据的原始分数,X杠为平均值,N为总数量,x为离均差,即
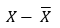
我们通过一个例子和几何图形来说明:

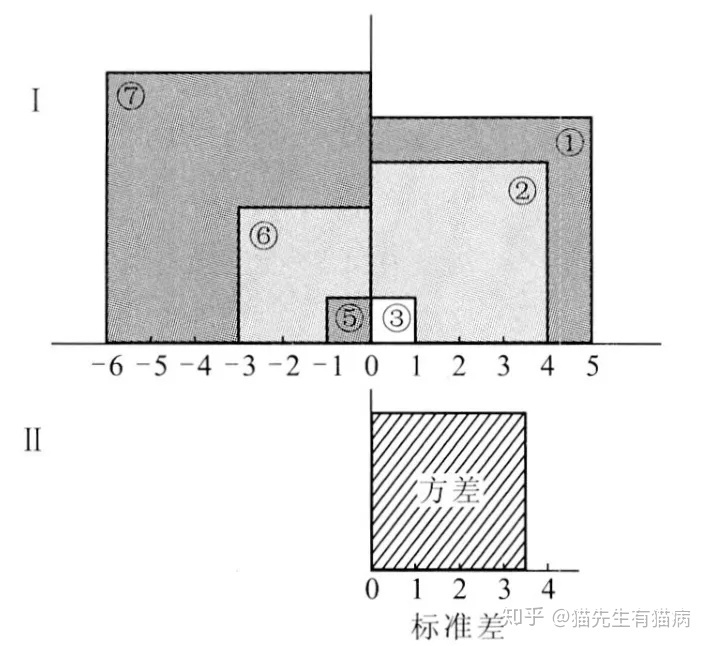
我们可以看到坐标轴以平均值为参考点,标记了被试的原始分数的离均差,离均差的平方就是各个正方形的面积,对应的就是表中的第四列。标准差就是把每个原始分数与平均数的距离(即离均差)先平方再求和,得到一个超级大正方形的总面积,然后除以N算出每个小正方形面积(即单位正方形),再开根号,得到的是单位正方形边长,这个边长就是标准差。那为什么不直接离差求和除以N呢?因为原始分数的离均差之和为0,这样是算不出来,所以才用平方和再开根,其计算的原理是正方形面积求边长。
那么我们最终求出来的标准差实际上是一个单位距离,这个单位距离就是个值,越大说明所有原始分数距离平均数的距离越远,离中趋势越大,分布越分散;值越小说明所有原始分数距离平均数的距离越近,集中趋势越大,分布越集中,这就体现了标准差是如何描述一组数据离散程度的原因。
通过几何原理,我们就知道标准差其实就是个单位距离(边长),它将所有原始分数距离平均数的距离求平方和,将所得的大正方形除以N等进行了等距的划分,开平方后依然是等距的,它代表了一个单位,但这个单位是相对本组数据来说的。
理解了标准差的原理和意义,我们来看标准分数,即Z分数。首先我们来看标准分数的定义,它是以标准差为单位表示一个原始分数在团体中所处位置的相对位数量数。离平均数有多远,即表示原始分数在平均数以上或以下几个标准差的位置,从而明确该分数在团体中的相对地位的量数。定义理解起来较为抽象,我们直接来看公式

式中s为标准差,X为某组数据的原始分数,X杠为平均值,N为总数量,x为离均差,即
我们先来看分母,即标准差s,通过上述的解释,我们已经知道标准差是该组数据的一个单位距离,它是这组数据等距后的标准单位,因此可以作为分母。再来看分子,即离差,它是每个原始分数和平均值的差值,即原始分数距离平均数的位置,因为平均值是这组数据算出来的固定值,原始分数与它做差值,就等于把平均数作为标杆,以平均数为参照点,这个位置除以标准差这个单位,就是这个原始分数距离平均数多少个标准差。那么,分子是原始分-平均数(该组数据的常数),分母是标准差(是该组数据的单位),所以相除算出的Z分数,Z分数也是等距的。
我们来看Z分数的性质,每组数据的原始分数转换为Z分数后成为一组新的Z分数数据,这组新的数据,它的平均值是0,标准差是1,注意是Z分数的平均值是0,标准差是1,不是原始数据的平均值和标准差,所以当给出任何一组连续的随机变量的数据时,如果它的数据分布是正态分布(注意这是前提),你都能转换成Z分数,得到的每组Z分数的平均值都是0,每组Z分数的标准差都是1。
我们计算得出的Z分数有什么用呢?为什么算Z分数呢?我们通过下面的实例进行说明。
首先我们先只看A组的数据
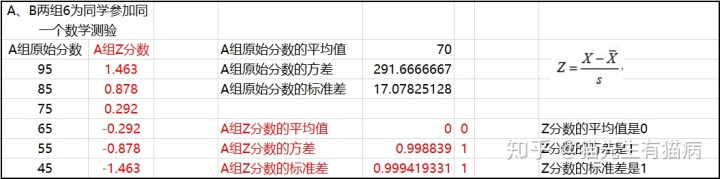
这组数据转换完势必会有正负值,我们可以直观得知道多少个正值在平均水平之上,多少个负值在平均水平之下,也就是说你能知道原始分数多少个在平均分之上,多少个在平均分之下,Z分数的优点是快速、直观,当数据量大时,无法明确看到平均数参照点的时候,通过转换Z分数,可以更加直观表明原始分数在该组数据分布中的位置,故Z分数也称为相对位置量数。
接下来我们看A组和B组两组数据。
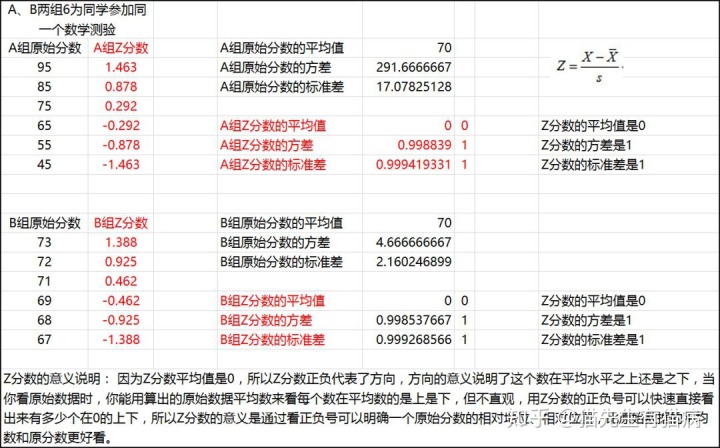
A、B两组都参加数学测验,这两组分数原始分分布不同,但平均数都是70,转化为Z分数后,可以分别看到这两组数据各自分数的相对位置,注意是各自的,也就是说如果你直接单看这两组的Z分数,通过这两组的Z分数比较这两组差异是没有意义的。为什么?因为Z分数是对一组自己的数据来看其相对位置的,两组之间互相看相对位置是没有意义的,比如当你只看A、B两组的Z分数(注意不看均值和标准差),这时你根本看不出来A组是分散的、B组是集中的,那这个怎么看,需要配合标准差来看,因为标准差是单位,Z分数乘以标准差就是离差,就是距离平均值的位置。
1. 价值一:用于比较几个分属性质不同的观测值在各自数据分布中相对位置高低。
我们通过体重和身高举例,一个人的体重和身高这就是不同质的观测,如果已知身高和体重各自数据分布的平均值和标准差,可以分别算Z分数,假设某人身高的Z分数=0.5,体重的Z分数=1.2,就能知道这个人的体重离平均数的距离比身高离平均数的距离要远,结论是这个人在这个团体里身高偏高,体重偏重,也就是说Z分数它能针对这个人来看团体内这两个属性的各自差异,而不是拿这一个团体的身高和体重这两组的Z分数比大小,也就是说某一个人Z身高0.5和Z体重1.2,单看0.5和1.2这两个数是没有可比性的,而是要放在各自的群里看这个人的这两个值的相对位置,所以对比不同质分数,不是简单对比这两个值,而是带着团体的性质对比相对位置。
回到这个应用价值,“几个分属性值不同的观测值”就是身高和体重,“各自数据分布中相对位置高低”就是各身高在身高的数据分布中高低和体重在体重的数据分布中的高低,比较的维度是1个人在这两个分属性中各自的相对位置。
2. 价值二:计算不同质的观测值的总和或平均值,以表示在团体中的相对位置。
例如高考,各科成绩分布都是正态分布,但各科的难易度不同,所以各科的成绩(即原始分数)就不是同质的。比如:
已知:语文平均是80,标准差8;数学平均55,标准差4;英语平均值42,标准差5,
甲考生语文70、数学57、英语45,原始分总和为172分
乙考生语文90、数学51、英语40,原始分总和为181分
经过Z分数转换
甲考生语文0、数学0.5、英语0.6,Z分总和为1.1
乙考生语文2.5、数学-1、英语-0.4,Z分总和为1.1
结论:两个学生三门功课Z分数总分均为1.1,说明两个学生总分是没有差异的。
回到应用价值:计算了不同质的总和(即Z分数的总和),以表示在团体中的相对位置(即甲和乙在团体中的位置相等),但要注意这个应用价值的目的是算和来看团体的相对位置,有两个要点:
第一,它是看所有学生总分的每个人的相对位置,它考虑的只是每个人的总分的相对位置,它没有去管每一门之间的相对位置(这个相对位置在各自科目的数据分布里)。
第二,这里的不同质,首先语文、英语、数学是三个不同的科目,不同质不是说这三个科目不同质,而是说这三个科目的难易水平导致的成绩是不同质的,但注意它们都是教育考试,本身的性质就决定了成绩是可以加一起算的,总的Z分数适用于去选拔的,体现了Z分数的可加性优点。对比上个例题,体重的Z分数+身高的Z分数就没意义,因为这两个是独立属性,加在一起没有用,而成绩加在一起是有用的,所以要分清同质不同质的含义。我们再回到成绩,如果再加个理综成绩比较,语文数学英语满分都是150分,理综满分是300分,通过Z分数的转化,等于是把各科的权重拉到了一个水平上,体现了Z分数的稳定性优点,也就是Z分数的稳定性含义,即不同性质的分数(各科的Z分数)在总分数(各科的Z分数总和)中的权重一样,原理是如果语文、英语、理综难度适中,但数学极难,这样就导致了数学自己的原始分数的标准差和其他科目相距很远,等于无形中增大了数学的权重的不足,所以通过Z分数转换,每门成绩的Z分数的标准差都是1,虽然每门的平均成绩的标杆不一样,但就是因为每门成绩有各自的标杆,各自的原始分数都是按照这个标杆算出的Z分数,所以它们可以相加,比如语文和数学的满分值都是100,语文平均分是30分,数学平均分是90分,但由于转换Z分数都是拿各自的平均分除以各自的标准差,所以得到的各自的Z分数是可以相加的,但注意相加的大前提得是有意义,体重+身高相加是没意义的。

希望通过阿猫的实例说明,能够帮助大家更清晰的理解标准差和Z分数的原理以及应用的价值。

















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









