





Attention U-Net
原文:Attention U-Net:Learning Where to Look for the Pancreas [Cited by 440]
论文链接: https://arxiv.org/abs/1804.03999
pytorch official code: https://github.com/ozan-oktay/Attention-Gated-Networks
笔记时间:2020.12.5
写在前面
方法部分感觉写的有点乱,如果有写不清楚的欢迎指出。我改~
这篇文章应该是比较早的把软attention的思想引入到医学图像当中的。
注意力
注意力分为Hard Attention和 Soft Attention
硬注意力:一次选择一个图像的一个区域作为注意力,设成1,其他设为0。他是不能微分的,无法进行标准的反向传播,因此需要蒙特卡洛采样来计算各个反向传播阶段的精度。 考虑到精度取决于采样的完成程度,因此需要其他技术(例如强化学习)。
软注意力:加权图像的每个像素。 高相关性区域乘以较大的权重,而低相关性区域标记为较小的权重。权重范围是(0-1)。他是可微的,可以正常进行反向传播。

观察上图,这是一个图像生成标题的任务。上面是soft 下面是hard,我们可以看到,soft attention的权重是每次被放置在整张图像上,注意力关注的部分(越白)的数值越接近1,越黑越接近0
unet需要attention的原因
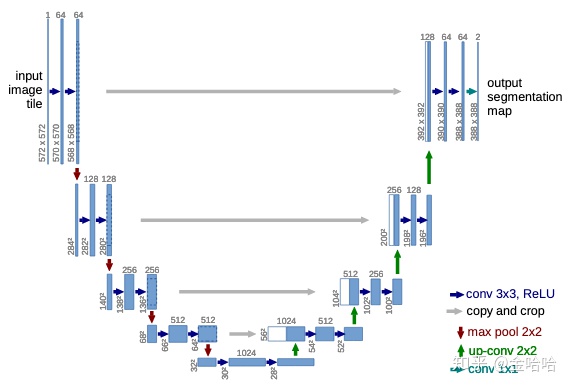
在传统的unet中,为了避免在decoder时丢失大量的空间精确细节信息,使用了skip的手法,直接将encoder中提取的map直接concat到decoder相对应的层。但是,提取的low-level feature有很多的冗余信息(刚开始提取的特征不是很好)。
软注意力的使用,可以有效抑制无关区域中的激活,减少冗余的部分的skip。
Abstract
开题点睛,创新点在于提出了一种注意力门attention gate (AG)模型。用该模型进行训练时,能过抑制模型学习与任务无关的部分,同时加重学习与任务有关的特征。(集中注意力到有用的地方,提取有用的东西,甩掉没用的东西)
AG即插即用,可以直接集成到网络模型当中。
Introduction
在医学分割中,当目标器官形状和大小在不同患者间差异较大时。还是需要多级级联cnn。胆识级联模型中所有模型都会重复的提取相似的低级特征。
如果使用文章所提的attention gate的方法,就可以代替,级联网络的使用。能够注意与学习任务有关的特征。
Methodogy
文章中用了不少数学公式来讲方法,并且时3D形式的。这里结合2D的代码来看看是怎么实现这个注意力门的。
代码参考:https://github.com/LeeJunHyun/Image_Segmentation
def forward(self,x):
# encoding path
x1 = self.Conv1(x) #1*3*512*512 ->conv(3,64)->conv(64,64)-> 1*64*512*512
x2 = self.Maxpool(x1) #1*64*512*512 -> 1*64*256*256
x2 = self.Conv2(x2) #1*64*256*256 ->conv(64,128)->conv(128,128)-> 1*128*256*256
x3 = self.Maxpool(x2) #1*128*256*256 -> 1*128*128*128
x3 = self.Conv3(x3) #1*128*128*128 ->conv(128,256)->conv(256,256)-> 1*256*128*128
x4 = self.Maxpool(x3)#1*256*128*128 -> 1*256*64*64
x4 = self.Conv4(x4) #1*256*64*64 ->conv(256,512)->conv(512,512)-> 1*512*64*64
x5 = self.Maxpool(x4)#1*512*64*64 -> 1*512*32*32
x5 = self.Conv5(x5) #1*512*32*32->conv(512,1024)->conv(1024,1024)-> 1*1024*32*32
# decoding + concat path
d5 = self.Up5(x5) #1*1024*32*32 ->Upsample-> 1*1024*64*64 -> conv(1024,512) ->1*512*64*64
x4 = self.Att5(g=d5,x=x4) #2(1*512*64*64) -> 1*1*64*64 ->1*512*64*64
d5 = torch.cat((x4,d5),dim=1) #1*1024*64*64
d5 = self.Up_conv5(d5) #1*1024*64*64 ->conv(1024,512)->conv(512,512)-> 1*512*64*64
d4 = self.Up4(d5)
x3 = self.Att4(g=d4,x=x3)
d4 = torch.cat((x3,d4),dim=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
x2 = self.Att3(g=d3,x=x2)
d3 = torch.cat((x2,d3),dim=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
x1 = self.Att2(g=d2,x=x1)
d2 = torch.cat((x1,d2),dim=1)
d2 = self.Up_conv2(d2)
d1 = self.Conv_1x1(d2)
return d1
上面的代码时forward的整体框架,unet的框架就不多做介绍,直接看attention的实现。对于一张输入为1x3x512x512(1是batchsize,3是通道)的2D图,执行到x5的时候(经过五次下采样)已经是最小的feature map了(1x1024x32x32)。对其进行上采样得到d5(1x512x64x64)。
对d5和x4执行Att5(g=d5,x=x4)
self.Att5 = Attention_block(F_g=512,F_l=512,F_int=256)
class Attention_block(nn.Module):
def __init__(self,F_g,F_l,F_int):
super(Attention_block,self).__init__()
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_int, kernel_size=1,stride=1,padding=0,bias=True),
nn.BatchNorm2d(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2d(F_l, F_int, kernel_size=1,stride=1,padding=0,bias=True),
nn.BatchNorm2d(F_int)
)
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1, kernel_size=1,stride=1,padding=0,bias=True),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
self.relu = nn.ReLU(inplace=True)
def forward(self,g,x):
g1 = self.W_g(g) #1x512x64x64->conv(512,256)/B.N.->1x256x64x64
x1 = self.W_x(x) #1x512x64x64->conv(512,256)/B.N.->1x256x64x64
psi = self.relu(g1+x1)#1x256x64x64di
psi = self.psi(psi)#得到权重矩阵 1x256x64x64 -> 1x1x64x64 ->sigmoid 结果到(0,1)
return x*psi #与low-level feature相乘,将权重矩阵赋值进去
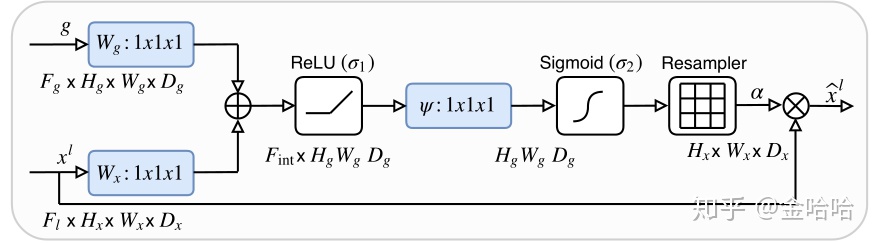
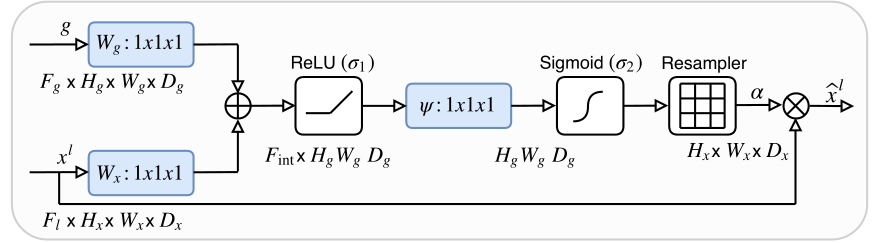
x4是从上往下下采样得到的图。d5是x4下一层map上采样的图。要对d5和x4执行Att5(g=d5,x=x4)。
图中的xl对应代码中的x4,g代表代码中的d5。(想象一下unet的图,xl就是左边的东西,g是右边的对应大小的东西)
g(1x512x64x64)/ x4(1x512x64x64)
注意力模块执行步骤:
- 对g做1*1卷积得到 1x256x64x64
- 对xl做1*1卷积得到 1x256x64x64
- 讲1,2步结果相加(为什么要加起来呢?为了突出特征,如果在两个图中某个点两者都有,加起来,会更为突出)
- 对第3步结果relu
- 对第4步结果做conv(256,1)卷积,将256通道降到1通道。得到1x1x64x64的图
- 对第5步结果进行sigmoid,使得值落在(0,1)区间,值越大,越是重点。(这个得到的就是注意力权重)
- 这里因为图的大小一样,所以不需要resampler。
- 最后和xl相乘,把注意力权重赋到low-level feature中。
attention出来的结果在和上采样的结果(x4)进行concat(这里就和unet一样了。区别就是unet是skip的是直接过来的low-level feature,而我这里concat的是low-level feature是先经过注意力机制赋予权重(0-1)的map)

在上图中。在3、6、10和150个epoch时,其中红色突出显示较高的注意力。随着训练的进行,网络学会了专注于期望的区域。
参考
https://towardsdatascience.com/a-detailed-explanation-of-the-attention-u-net-b371a5590831














 4687
4687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









