






首先附上我下载的计算公式(论文里未写出)

首先
有无对象损失函数计算方法
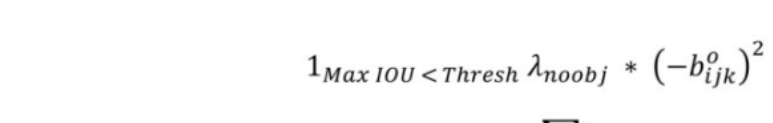
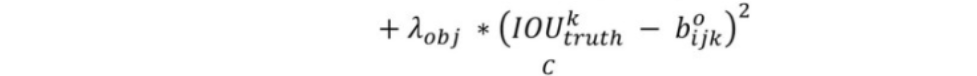
其中
# no_object_scale = 1
# (1 - object_detections)保留阈值小于0.6的预测框
# 1 - detectors_mask保留与trueboxes不匹配的anchors
# pred_confidence,这部分有无对象的置信度
no_object_weights = (no_object_scale * (1 - object_detections) *
(1 - detectors_mask))
no_objects_loss = no_object_weights * K.square(-pred_confidence)
# pred_confidence,无对象的置信度,希望它越小越好,符合损失函数
if rescore_confidence:
objects_loss = (object_scale * detectors_mask *
K.square(best_ious - pred_confidence))
else:
objects_loss = (object_scale * detectors_mask *
K.square(1 - pred_confidence))
confidence_loss = objects_loss + no_objects_loss
# 1 - pred_confidence,希望它越小越好(pred_confidence越大越好),符合损失函数YOLOv2中,总共有845个anchor_boxes。在未与true_boxes匹配的anchor_boxes中,与true_boxes的max IOU小于0.6预测无对象,需要计算no_objects_loss其损失。而objects_loss则是与true_boxes匹配的anchor_boxes的预测误差。与YOLOv1不同的是修正系数的改变,YOLOv1中no_objects_loss和objects_loss分别是0.5和1,而YOLOv2中则是1和5。其中 objects_loss = (object_scale * detectors_mask * K.square(best_ious - pred_confidence))和公式表述相类似。
类别损失函数计算方法
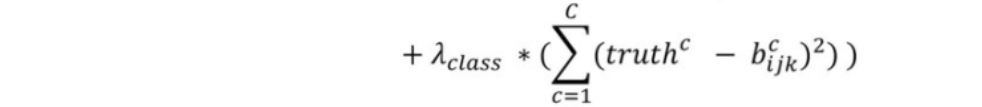
均方误差:(1-卷积层预测类别概率)的平方;
这里:matching_classes和detectors_mask 是preprocess_true_boxes函数(allanzelener/YAD2K)计算获得,也就是trueboxes和anchors的预处理得到的结果(每个trueboxes都会匹配对应的anchors,并将给anchors打标签)。
matching_classes = K.cast(matching_true_boxes[..., 4], 'int32')
matching_classes = K.one_hot(matching_classes, num_classes)
classification_loss = (class_scale * detectors_mask *
K.square(matching_classes - pred_class_prob))坐标损失函数计算方法
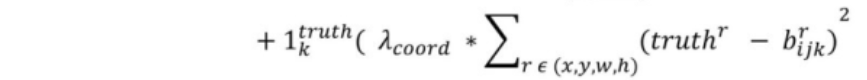
这里较YOLOv1的改动较大:
1)计算x,y的误差由相对于整个图像(416x416)的offset坐标误差的均方改变为相对于gird cell的offset坐标误差的均方。并且将YOLOv1w,h取根号处理改为对YOLOv2中长宽放缩因子取log。
2)并将修正系数由5改为了1 。
相同点:YOLOv1的想法一样,对于相等的误差值,降低对大物体误差的惩罚,加大对小物体误差的惩罚。
解释下括号里面参数的含义:
预测值:神经网络预测的(tx,ty,tw,th)中(tx,ty)是取sigmoid函数得到的处于(0,1)的值,(tw,th)保持不变;显然这四个参数是需要神经网络训练的。
真值:将trueboxes同匹配的anchors进行运算求得,(tx,ty,tw,th)中(tx,ty)为trueboxes在13x13尺度下中心相对gridcell的偏移值,(tw,th)是与对true_boxes匹配的anchor_boxes的长宽的比值取log函数。
# Coordinate loss for matching detection boxes.
matching_boxes = matching_true_boxes[..., 0:4]
coordinates_loss = (coordinates_scale * detectors_mask *
K.square(matching_boxes - pred_boxes))
"""
matching_true_boxes: 这里的shape是[13,13,5,5],四个维度。
第一个维度:true_boxes的中心位于第几行(y方向上属于第几个gird cel)
第二个维度:true_boxes的中心位于第几列(x方向上属于第几个gird cel)
第三个维度:第几个anchor box
第四个维度:[x,y,w,h,class]。这里的x,y表示offset,是基于对应的gird cell的坐标值,w,h是取了log函数的,class是属于第几类。
x: box[0] - j,
y: box[1] - i,
w: np.log(box[2] / anchors[best_anchor][0]),
h: np.log(box[3] / anchors[best_anchor][1]),
class: box_class。
"""
"""
神经网络卷积层输出结果中将tx和ty经过sigmoid函数处理过的;
tw,th: 与对true_boxes匹配的anchor_boxes的长宽的比值取log函数,
pred_boxes = K.concatenate(
(K.sigmoid(feats[..., 0:2]), feats[..., 2:4]), axis=-1)
'shape:[1,13,13,5,4],[sigmoid(tx),sigmoid(ty),tw,th']
"""
附上:YOLOv1的损失函数(第一项坐标之间是减号)
















 4370
4370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









