





前言
目前市面上常用的人脸识别训练框架是insightface,虽然作为刷榜神器的insightface很不错,但是静态图调试起来太累(动态图养成的病)。
https://github.com/deepinsight/insightfacegithub.com我曾经也想过用mxnet的gluon接口把insightface封装起来,但是gluon的多卡训练速度实在让人不敢恭维,现存占用也是超级多。大家可以测试下gluon的接口,虽然现在改良很多,但是依然不是很理想。
dmlc/gluon-cvgithub.com
本着对pytorch忠实fans的原则,在github上搜索了一款pytorch的人脸训练框架。使用下来,使用下来发现这个开源工具速度也是不利索。
ZhaoJ9014/face.evoLVe.PyTorchgithub.com后来发现原因是在多卡训练时候使用的是DP模块,拆分超大FC使用的就是普通module模块。具体分析如下:
1、DP模块在训练时候需要不停的把梯度同步到0卡上,造成0卡的显存占用过大,整体batch上不去(DP模块的拆分做负载均衡可以解决)。
2、梯度同步没用使用nccl这个工具,使得GPU的利用率不够高(历史的教训告诉我使用硬件厂商提供的工具永远是最快的!!!!)。
Face_benchmark
https://github.com/p517332051/face_benchmarkgithub.com使用过pytroch的DDP模块的同学都知道,在多卡环境下那个GPU利用真是杠杠的,让GPU时刻处于百米竞速状态(不过很烧电,如果你是阿里云那你应该会变相省下一点钱)。常见的检测框架maskrcnn_benchmark、Detectron2、mmdetection,这三个框架就是DDP模块的标杆,我觉得目前训练速度最快的就是这个三个深度学习工具包了。
所以我的目标也很明显就是将face.evoLVe.Pytorch中的DP模块换成DDP模块。难点主要是怎把超大规模的FC层中的权重拆分并把它封装在DDP模块上,具体怎么实现可以看我的源代码是怎么写的。
数据训练准备
举个例子,比如msra这个文件夹内有数据,存储方式是
your_path/data/msra/xiaoming/*.jpg
your_path/data/msra/xiaogang/*.jpg
……..
your_path/data/msra/laowang/*.jpg
然后使用your_path/face_benchmark/tools/data_process.py 将下面变量设置为
data_root=r'your_path/data/msra'
file_list = r'your_path/data/msra/msra_face_112*112.txt'最后在your_path/data/msra这个目录下生成一个msra_face_112*112.txt的txt文件,用来记录msra每个ID的label。
然后在your_path/maskrcnn_benchmark/config/paths_catalog.py这个代码添加路径。数据路径添加和maskrcnn_benchmark一样。
"msra_face": {
"img_dir": r"you_path/data/msra",#msra数据集
"ann_file": r"you_path/data/msra/msra_face_112*112.txt",#存储msra每个ID的label
"im_info": [112, 112] #你对齐后的图片大小
},训练启动脚本
python tools/Muti_GPUS_Train.py --ngpus_per_node=8 --npgpu_per_proc=1 tools/train_face_netDivFC.py --skip-test --config-file configs/face_reg/face_net_msra_celeb.yaml DATALOADER.NUM_WORKERS 16 OUTPUT_DIR--ngpus_per_node=8 表示的机器有8个GPU。
--npgpu_per_proc=1 表示你使用1个DDP,使用8个GPU拆分FC层进行训练。
例子:
—ngpus_per_node=4 表示的机器有8个GPU。
—npgpu_per_proc=2 表示你使用2个DDP,8个GPU分成两份,分别给DDP在4个GPU下拆分FC。
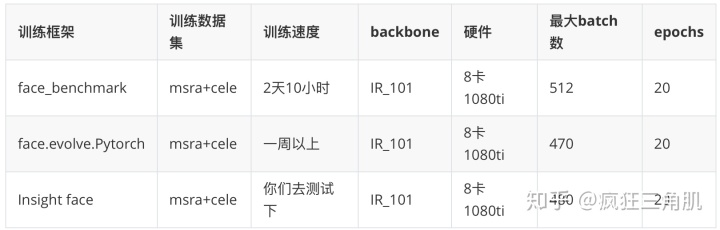
在20个epochs下:
//==============2020年3月16日 美联储基准利率降到0==================//














 2165
2165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









