







利用Scrapy爬虫的基本思路:
- 创建工程:
scrapy startproject project_name #自定义项目名通过Anaconda prompt或CMD输入指令,会创建如下目录结构:
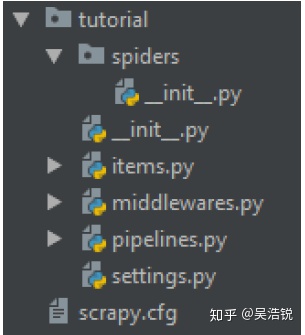
2.定义Item, 构造爬取的对象:
item_name_1 = scrapy.Field()
item_name_2 = scrapy.Field()
item_name_3 = scrapy.Field()
...3.编写主体Spider:
- 使用BeautifulSoup解析网页内容。
- 调用自定义的Item。
#切换到项目文件路径下执行以下代码:
scrapy genspider spider_name url4.编写配置和Pipeline,用于处理爬取的结果。
- 目的:处理解析的Item, 如结果保存为CSV文件
- 在settings.py中配置优先级(优先级的数值越小,优先级越高)。

- 添加open_spider(),close_spider()、process__item()函数。
5.执行爬虫
scrapy crawl aqi_spider分析思路:
获取爬取网页的url(包括一级网址、二级网址) >>> 依据二级网址获得城市指数 >>> 依据一级网址热门城市的城市名称、城市链接(根据城市链接【二级网址】获得城市的指数数据)>>> 写入json文件
项目分析:
对网址http://www.pm25.in/ 进行分析,获得热门城市的名称和链接(二级网址),然后依据二级网址获得该城市的各种指数,以下对各种指数【AQI、PM2.5/1h、PM10/1h、CO/1h、NO2/1h、O3/1h、O3/8h、SO2/1h】进行说明:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2435
2435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









