





作者:程序诗人来源:https://www.cnblogs.com/scy251147/p/9193075.html在互联网设计架构过程中,日志异步落库,俨然已经是高并发环节中不可缺少的一环。为什么说是高并发环节中不可缺少的呢? 原因在于,如果直接用mq进行日志落库的时候,低并发下,生产端生产数据,然后由消费端异步落库,是没有什么问题的,而且性能也都是异常的好,估计tp99应该都在1ms以内。
但是一旦并发增长起来,慢慢的你就发现生产端的tp99一直在增长,从1ms,变为2ms,4ms,直至send timeout。尤其在大促的时候,我司的系统就经历过这个情况,当时mq的发送耗时超过200ms,甚至一度有不少timeout产生。
考虑到这种情况在高并发的情况下才出现,所以今天我们就来探索更加可靠的方法来进行异步日志落库,保证所使用的方式不会因为过高的并发而出现接口ops持续下降甚至到不可用的情况。
方案一: 基于log4j的异步appender实现
此种方案,依赖于log4j。在log4j的异步appender中,通过mq进行生产消费入库。相当于在接口和mq之间建立了一个缓冲区,使得接口和mq的依赖分离,从而不让mq的操作影响接口的ops。
此种方案由于使用了异步方式,且由于异步的discard policy策略,当大量数据过来,缓冲区满了之后,会抛弃部分数据。此种方案适用于能够容忍数据丢失的业务场景,不适用于对数据完整有严格要求的业务场景。
来看看具体的实现方式:
首先,我们需要自定义一个Appender,继承自log4j的AppenderSkeleton类,实现方式如下:
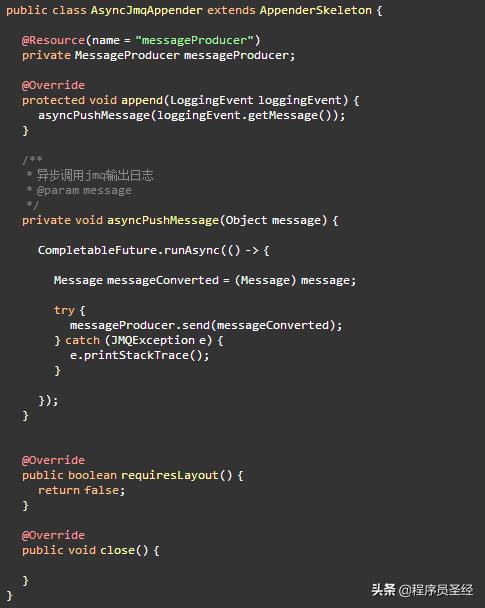
然后在log4j.xml中,为此类进行配置:
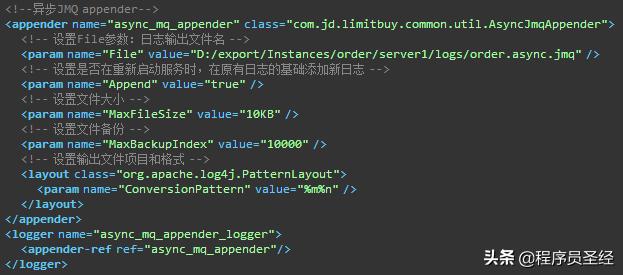
最后就可以按照如下的方式进行正常使用了:
private static Logger logger = LoggerFactory.getLogger("filelog_appender_logger");注意: 此处需要注意log4j的一个性能问题。在log4j的conversionPattern中,匹配符最好不要出现 C% L%通配符,压测实践表明,这两个通配符会导致log4j打日志的效率降低10倍。
方案一很简便,且剥离了接口直接依赖mq导致的性能问题。但是无法解决数据丢失的问题(但是我们其实可以在本地搞个策略落盘来不及处理的数据,可以大大的减少数据丢失的几率)。但是很多的业务场景,是需要数据不丢失的,所以这就衍生出我们的另一套方案来。
方案二:增量消费log4j日志
此种方式,是开启worker在后台增量消费log4j的日志信息,和接口完全脱离。此种方式相比方案一,可以保证数据的不丢失,且可以做到完全不影响接口的ops。但是此种方式,由于是后台worker在后台启动进行扫描,会导致落库的数据慢一些,比如一分钟之后才落库完毕。所以适用于对落库数据实时性不高的场景。
具体的实现步骤如下:
首先,将需要进行增量消费的日志统一打到一个文件夹,以天为单位,每天生成一个带时间戳日志文件。由于log4j不支持直接带时间戳的日志文件生成,所以这里需要引入log4j.extras组件,然后配置log4j.xml如下:
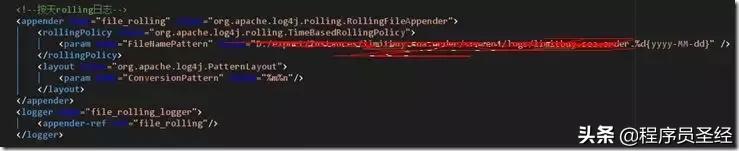
之后在代码中的申明方式如下:
private static Logger businessLogger = LoggerFactory.getLogger("file_rolling_logger");最后在需要记录日志的地方使用方式如下:
businessLogger.error(JsonUtils.toJSONString(myMessage))这样就可以将日志打印到一个单独的文件中,且按照日期,每天生成一个。
然后,当日志文件生成完毕后,我们就可以开启我们的worker进行增量消费了,这里的增量消费方式,我们选择RandomAccessFile这个类来进行,由于其独特的位点读取方式,可以使得我们非常方便的根据位点的位置来消费增量文件,从而避免了逐行读取这种低效率的实现方式。
注意,为每个日志文件都单独创建了一个位点文件,里面存储了对应的文件的位点读取信息。当worker扫描开始的时候,会首先读取位点文件里面的位点信息,然后找到相应的日志文件,从位点信息位置开始进行消费。这就是整个增量消费worker的核心。
具体代码实现如下(代码太长):
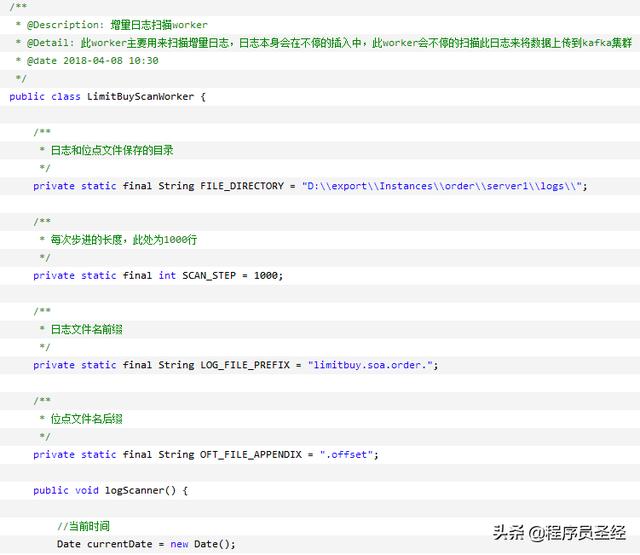

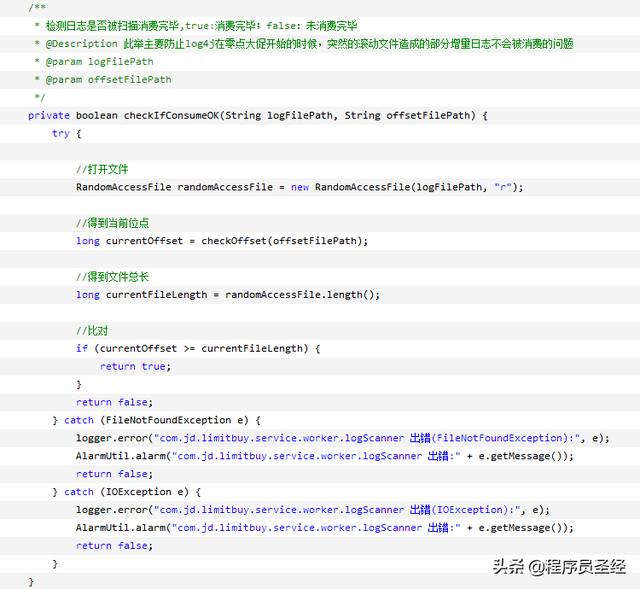

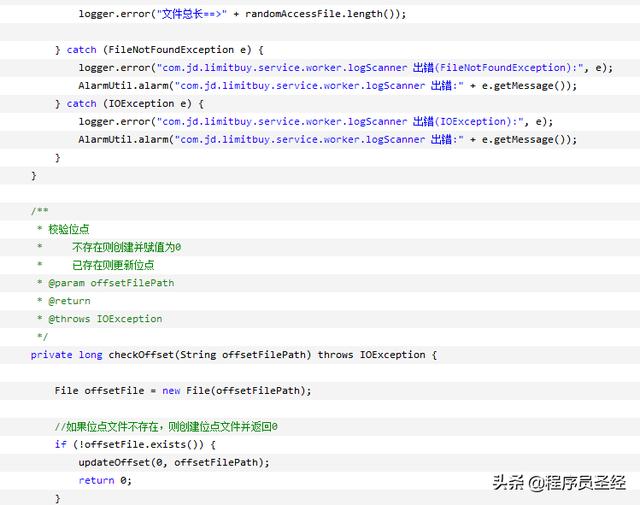
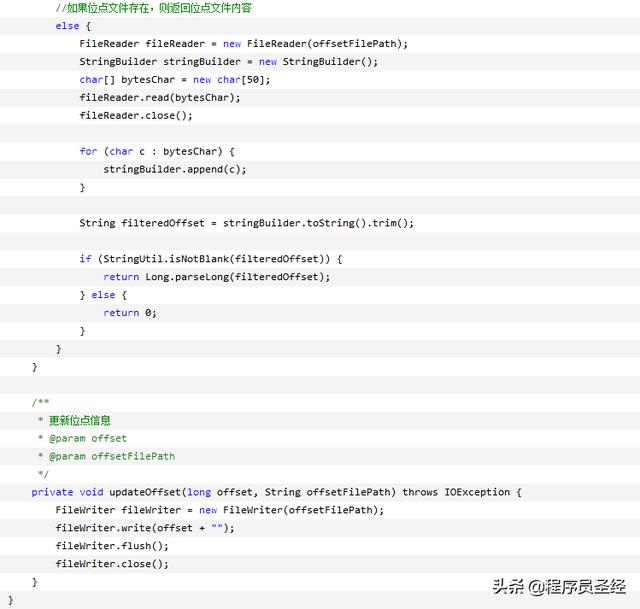
此种方式由于worker扫描是每隔一段时间启动一次进行消费,所以导致数据从产生到入库,可能经历时间超过一分钟以上,但是在一些对数据延迟要求比较高的业务场景,比如库存扣减,是不能容忍的,所以这里我们就引申出第三种做法,基于内存文件队列的异步日志消费。
方案三:基于内存文件队列的异步日志消费
由于方案一和方案二都严重依赖log4j,且方案本身都存在着要么丢数据,要么入库时间长的缺点,所以都并不是那么尽如人意。但是本方案的做法,既解决了数据丢失的问题,又解决了数据入库时间被拉长的尴尬,所以是终极解决之道。而且在大促销过程中,此种方式经历了实战检验,可以大面积的推广使用。
此方案中提到的内存文件队列,是我司自研的一款基于RandomAccessFile和MappedByteBuffer实现的内存文件队列。队列核心使用了ArrayBlockingQueue,并提供了produce方法,进行数据入管道操作,提供了consume方法,进行数据出管道操作。而且后台有一个worker一直启动着,每隔5ms或者遍历了100条数据之后,就将数据落盘一次,以防数据丢失。具体的设计,就这么多,感兴趣的可以根据我提供的信息,自己实践一下。
由于有此中间件的加持,数据生产的时候,只需要入压入管道,然后消费端进行消费即可。未被消费的数据,会进行落盘操作,谨防数据丢失。当大促的时候,大量数据涌来的时候,管道满了的情况下会阻塞接口,数据不会被抛弃。虽然可能会导致接口在那一瞬间无响应,但是由于有落盘操作和消费操作(此操作操控的是JVM堆外内存数据,不受GC的影响,所以不会出现操作暂停的情况,为什么呢?因为用了MappedByteBuffer),此种阻塞并未影响到接口整体的ops。
在实际使用的时候,ArrayBlockingQueue作为核心队列,显然是全局加锁的,后续我们考虑升级为无锁队列,所以将会参考Netty中的有界无锁队列:MpscArrayQueue。预计性能将会再好一些。
上面就是在进行异步日志消费的时候,我所经历的三个阶段,并且一步一步的优化到目前的方式。虽然过程曲折,但是结果令人欢欣鼓舞。















 5235
5235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









