





这是我之前在泡泡机器人上翻译的文章,放在这里做个备份,原文链接:https://www.sohu.com/a/339674840_715754
一、摘要
我们提出了一种基于卷积神经网络(CNN)的深度估计系统,该系统通过对从双目图像对中预测的深度图进行体积融合,从而得到场景的三维重建。我们提出了一种深度改进架构,它可以计算可视图的视差并预测遮挡部分,进而帮助融合系统产生几何一致的重建。我们在提出的新的代价滤波网络中利用3D扩张卷积,与现有滤波架构相比,会产生更好的滤波效果,同时将计算量减少一半。对于特征提取,我们使用Vortex Pooling架构。所提出的方法在KITTI 2012,KITTI 2015和ETH 3D数据集测试中均取得了最优秀的结果。最后,我们证明了我们的系统能够产生高质量的3D场景重建效果,其性能优于当前最先进的重建系统。
1. 新的视差改进网络
我们工作的主要动机是预测立体输入的几何一致视差图,可以直接用于基于TSDF的融合系统,如KinectFusion,用于同步跟踪和绘图。表面法线是KinectFusion类系统中融合权重计算的一个重要因素,我们观察到现有的双目重建系统(如PSMNet)产生的视差图不是几何一致的,对TSDF融合产生负面影响。为了解决这个问题,我们提出了一种新颖的改进网络,它将几何误差,光度误差和未确定的视差作为输入,并产生重新定义的视差(通过残差学习)和遮挡图。
2. 代价滤波中的3D扩张卷积
使用3D代价滤波方法的最先进的双目重建系统(如PSMNet和GC-Net)使用了过多的计算资源。而在我们的系统中,在所有三个维度(即宽度,高度和视差通道)中使用3D扩张卷积给出了更好的结果,并且计算量更少。
3. vortex pooling
我们观察到,与空间金字塔池化(在PSMNet中使用)相比,vortex pooling 提供了更好的结果。我们发现用过滤非基本真实区域的排除掩模微调我们的模型,对于获得视差预测中的锐边和细节非常有用。
二、主要算法
1、整体思路
本论文所提出的算法可以分解为特征提取,代价滤波和视差估计改进三个步骤,而不是使用通用的编码器 - 解码器CNN。算法整体的系统流程如下图所示。
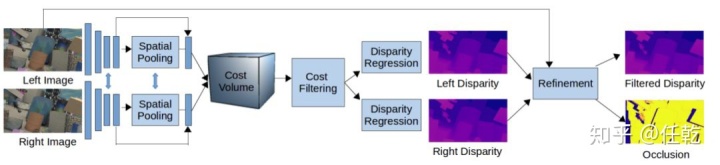
2、特征提取
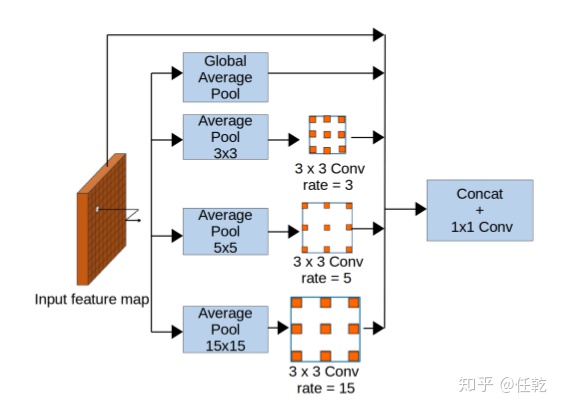
特征提取从一个小的共享权重Siamese网络开始,该网络将输入作为图像并将输入编码为一组特征。为了在特征映射中对局部空间信息进行编码,首先使用大小为2的卷积对输入进行下采样。本方法使用三个滤波器而不是大型的卷积,其中第一个卷积的步幅为2。为了编码更多的上下文信息,在学习的局部特征图上选择Vortex Pooling,Vortex Pooling的结构图如下图所示。除了在空间池化输出上的最后3x3卷积之外,我们的每个卷积之后都是批量标准化和RELU激活。为了使特征信息保持紧凑,在整个特征提取过程中将特征的尺寸保持为32。
3、代价体素滤波
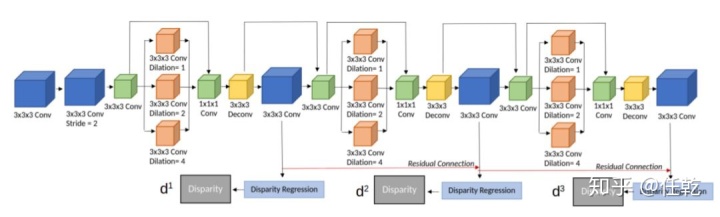
首先通过沿宽度,高度和深度尺寸的卷积处理代价量。然后通过2的步幅进行卷积来降低代价的分辨率,然后并行地进行扩张卷积。扩张卷积滤波器的串联上的卷积用于组合从不同感受野获取的信息。
残差学习已经被证明在视差优化过程中非常有效,因此提出了一系列这样的块来迭代地改进视差预测的质量。将整个过程描述为扩张残差代价滤波,如下图所示。
4、视差估计改进
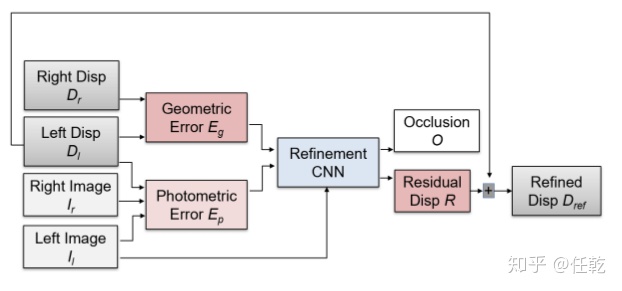
我们首先通过使用一层卷积,然后批量归一化来独立过滤左图像和重建误差以及左视差和几何误差图。随后将这些结果连接起来,进行空洞卷积,从而在不增加网络规模的情况下从更大的上下文中进行采样。我们分别使用速率为1,2,4,8,1和1的扩张。最后,使用没有ReLU或批量归一化的单个卷积来输出遮挡图O和视差残差图R。改进后的网络结构如下图所示。
三、实验
作者在整个多个数据集上测试了所提出的架构,例如SceneFlow,KITTI 2012,KITTI 2015和ETH3D。而且还展示了系统在构建室内场景的3D重建中的实用性。
在SceneFlow数据集上和PSMNet网络的对比效果如下图所示。图中顶行显示差异,底行显示EPE地图。从图中可以看出,作者所提出的网络能够恢复薄和小结构,同时在均匀区域中显示较低的误差。

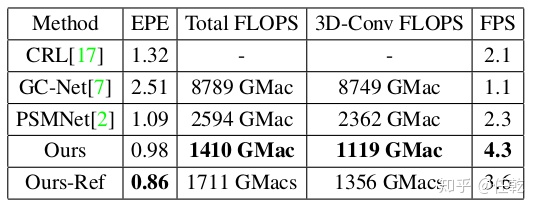
下表显示了有和没有改进网络架构的定量分析。Stereo-DRNet可以在减少计算时间的同时实现显着降低端点误差。而且作者提出的代价滤波方法在计算量显著降低的情况下实现更高的准确性,证明了方法的有效性。
四、结论
本文提出了一种基于双目的3D场景重建方法,该方法使用卷积神经网络结合预测深度图来估计图像对的深度。
同时提出了一种深度改进架构,它帮助融合系统产生几何一致的重建。最后在SceneFlow数据集上的结果显示,取得了state-of-art的效果。















 6179
6179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









