





现在项目上有个需求:对根本原因进行预测。
也就是说,给定根本原因以及其所对应的标签,通过机器学习算法对以后输入的根本原因进行自动化归类(或者说智能提示当前输入的根本原因属于哪个类别的)
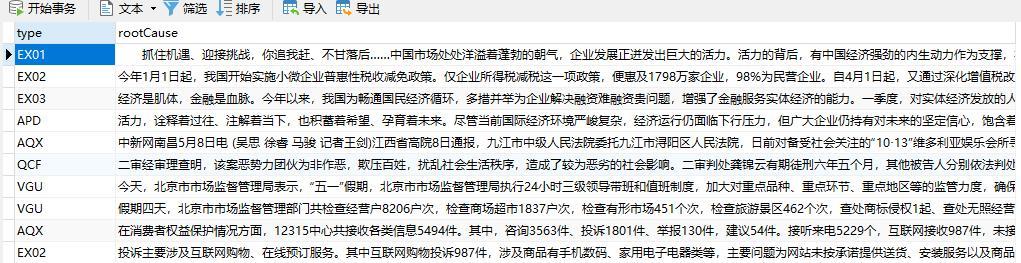
图1.数据库中的格式
我想既然需要用到机器学习,肯定需要将数据清洗。所以第一步我先把根本原因字段进行分词处理,然后再将分好的词对应的类别转换成机器学习所需的格式,进行训练、预测处理。
So 今天先把“根本原因”字段进行分词处理。
说到中文分词肯定用 jieba 了,关于jieba的使用教程以及各种参数的使用这里就不在冗余的叙述了,百度一下你就知道。我在这边就把我分词的过程代码以及环境的搭建分享一下。
环境:Python 3.6 +

我的python版本
然后进入cmd进入命令模式,安装jieba
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba

安装jieba
用了清华的镜像 这样比较快!
接着就是准备文本文件,对于这个数据的获取方式有两种,1.直接读取数据库获得,2.通过数据库导出文本。本次只是简单的测试数据量没有那么大,所以我就直接将数据库中的数据导出了,导出后的文本如下。

输入的文本
接下来准备一个停用词的文本,停用词就是遇到这个词就跳过,如“了”、“的”、“吧嗒”等一些没有意义的词汇和符号。我使用的停用词为哈工大停用词库,找不到的话可以找我。
部分停用词
接下来上python代码
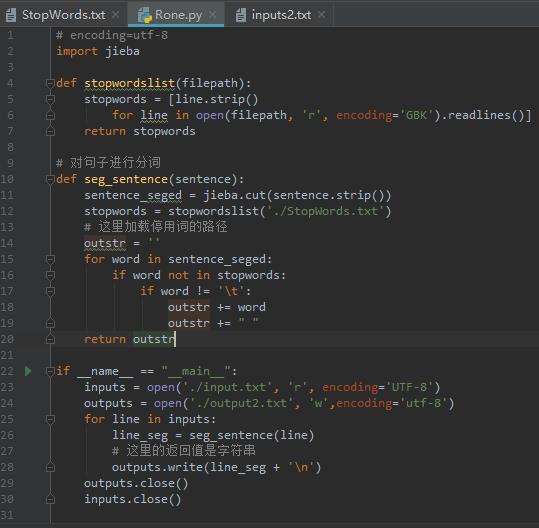
所有代码
确保你输入文本的路径以及停用词的路径放的正确,我这里是将它们放到了同级目录下。
点击运行会得到一个分词后的文本output2.txt,打开它与输入的文本做一个对比

可看出分词效果还不错,但是人名什么的还是在。所以说根据业务需求来确定停用词表还是有必要的。
分词完成后,我该怎么做。。。。。。。。。。。
有没有大佬给指点一二。。。。。。。。。。。。
or
用我原来的思路继续走下去。。。。。。。。。。















 3301
3301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









