







随着多模态基础模型的快速发展,如何准确评估这些模型在不同输入模态下的性能成为了一个重要课题。本文提出了IsoBench,一个基准数据集,旨在通过提供多种同构(isomorphic)表示形式的问题,来测试和评估多模态基础模型在数学、科学、算法和游戏等领域的表现。通过IsoBench发现,尽管人类倾向于偏好视觉表示,但当前的多模态模型在处理文本输入时的性能普遍优于图像输入。此外,本文还介绍了两种提升模型性能的提示技术:IsoCombination和IsoScratchPad,旨在通过结合不同输入表示或在视觉和文本表示之间进行转换来提高模型的推理能力。
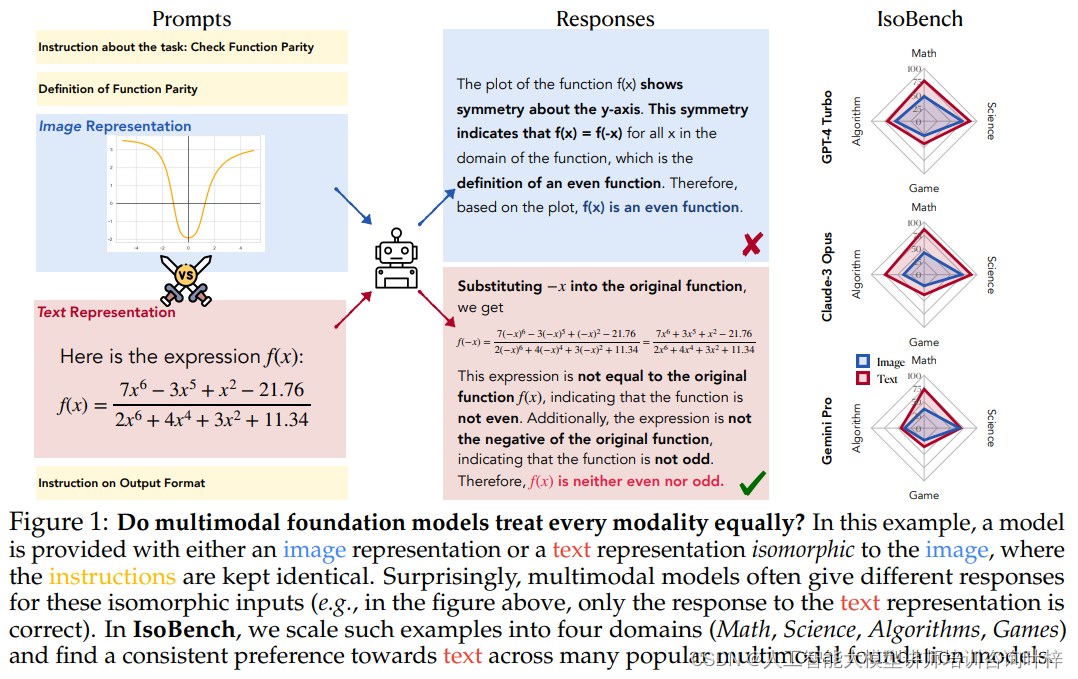
Figure 1探讨了多模态基础模型是否平等地处理每种模态。它展示了一个模型在接收图像表示或与之同构的文本表示时的不同响应。例如,在上面的图中,只有文本表示的响应是正确的IsoBench扩展了这样的示例到四个领域(数学、科学、算法、游戏),发现许多流行的多模态基础模型普遍倾向于文本。
IsoBench
IsoBench作为一个多领域的基准测试数据集,其设计初衷是为了全面评估多模态基础模型在处理各种类型问题时的性能。它包含了超过1630个精心挑选的样本,这些样本广泛覆盖了离散和应用数学、物理、化学以及国际象棋等不同领域。这样的设计使得IsoBench能够为研究者提供一个广泛的测试平台,用以衡量和比较模型在不同认知任务上的表现。
在IsoBench中,每个样本都至少提供了两种形式的表示:一种是视觉表示,另一种或多种是文本表示。视觉表示通常以图像的形式呈现,例如函数的曲线图、化学结构图或国际象棋的棋盘布局。与此相对应,文本表示则以文字形式提供相同的信息,这可能包括函数的数学表达式、化学方程式或棋局的代数表示。重要的是,这些文本表示与视觉表示是同构的,也就是说,它们在逻辑和信息上是等价的,这保证了研究者可以公正地评估模型处理不同模态输入的能力。
IsoBench的设计巧妙之处在于,它允许研究者直接比较模型在接收相同信息但以不同形式表达时的性能差异。这种比较对于理解多模态模型如何处理和整合来自不同模态的信息至关重要。例如,研究者可以观察到模型在解析文本描述的数学问题时是否比直接从图像中提取信息更为准确。同样,在化学领域,模型是否能够从分子结构图中正确地识别出相关信息,与它处理文本描述的能力相比如何,这些都是IsoBench能够回答的问题。
IsoBench的这种设计还有助于揭示模型可能存在的偏好或偏见。例如,如果模型在处理文本输入时的性能普遍优于图像输入,这可能表明当前的多模态模型在视觉信息处理方面存在局限,或者模型的训练过程中对文本数据的依赖性更强。通过这样的分析,研究者可以更深入地了解模型的内部工作机制,并据此对模型进行改进。
IsoBench的构建涉及以下几个步骤:
- 数学:包括连续数学问题的图像、LATEX和代码文本表示。IsoBench数据集的构建是一个精心设计的过程,旨在全面评估多模态基础模型在不同领域的表现。它涵盖了数学问题,这不仅包括了函数的图像表示,还包含了使用LATEX格式和代码形式的文本表示。图像表示通过matplotlib生成,确保了函数的关键属性在视觉上清晰可见。LATEX和代码文本表示则提供了函数的精确数学定义,使得模型可以通过解析这些文本来理解函数的性质。
- 游戏:国际象棋游戏的图形棋盘、代数布局、PGN和FEN文本表示。在游戏领域,尤其是国际象棋,IsoBench通过图形棋盘、代数布局、PGN(便携式游戏符号)和FEN(Forsyth-Edwards符号)等多种形式来表示棋局。图形棋盘以图像格式展示,而代数布局、PGN和FEN则以文本形式提供,这些文本表示形式能够使模型以不同的方式理解和处理棋局信息。
- 算法:图算法问题的图像、LATEX数学表达和故事描述文本表示。对于算法问题,IsoBench采用了图像、LATEX数学表达和故事描述文本这三种表示方式。图像表示利用networkx包以随机风格展示图,而LATEX表示则使用邻接矩阵作为图的数学表示。故事描述文本则将图问题以故事的形式呈现,例如将图连通性问题描述为判断两个城市之间是否可以通过驾驶到达。
- 科学:科学问题的图像和文本表示,后者由人工编写,以确保与图像内容的同构性。在科学问题方面,IsoBench包括了图像和文本两种表示形式。图像表示为每个样本提供了文本问题、选项以及附加的图表,以提供额外的上下文信息。文本表示则是由人工编写的,描述了每个图表的内容,同时避免引入额外的推理或超出图表所展示的信息,确保了与图像内容的同构性。
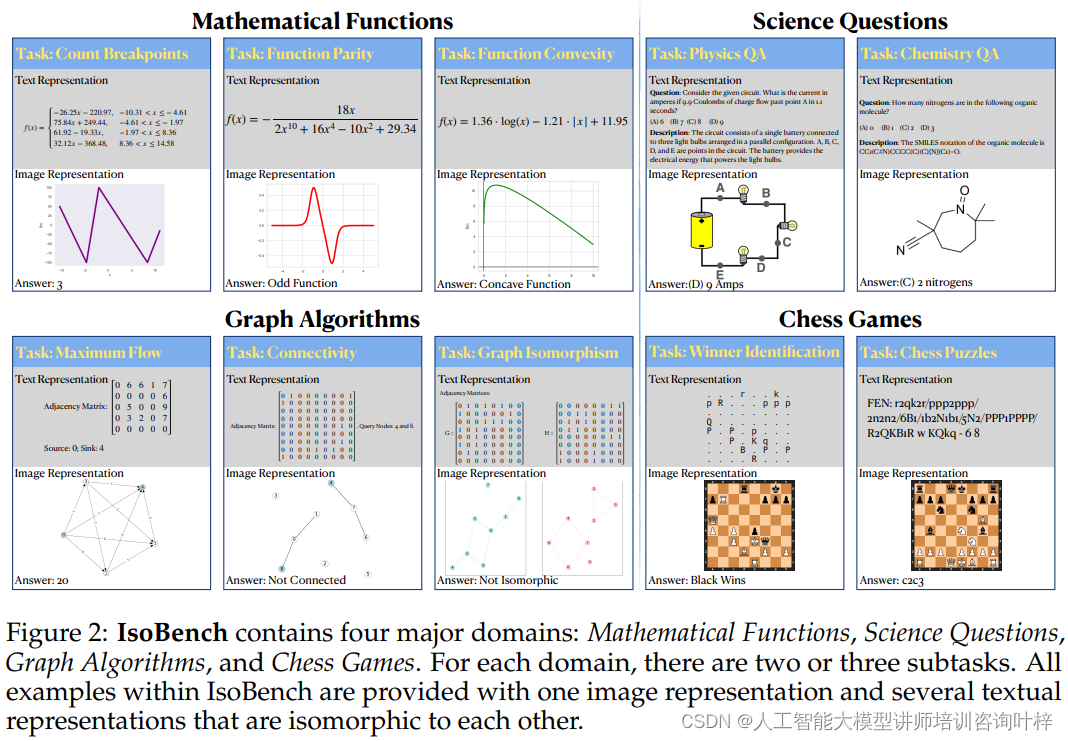
Figure 2介绍了IsoBench包含的四个主要领域:数学函数、科学问题、图算法和棋类游戏。对于每个领域,都有两个或三个子任务。IsoBench中的所有示例都提供了一个图像表示和几个与之同构的文本表示。
性能分析
性能分析的核心目的在于比较模型在接收相同信息的不同表示形式时的性能差异,尤其是视觉表示与文本表示之间的差异。通过对IsoBench数据集中的样本进行测试,研究者发现了一个有趣的现象:尽管人类在认知过程中通常更倾向于视觉信息,显示出所谓的“图片优势效应”,但参与测试的多模态模型却表现出了与人类完全相反的倾向。
这些模型在处理文本提示时的性能明显优于图像提示。例如,在IsoBench的测试中,Claude-3 Opus模型在图像输入下的表现比文本输入低了28.7个百分点,显示出在图像理解方面的明显不足。同样,GPT-4 Turbo和Gemini Pro也展现出了类似的趋势,分别在图像输入下比文本输入低18.7个百分点和14.9个百分点。这一发现指出了当前多模态模型在图像处理能力上的局限性,同时也表明了模型在文本理解方面的相对优势。
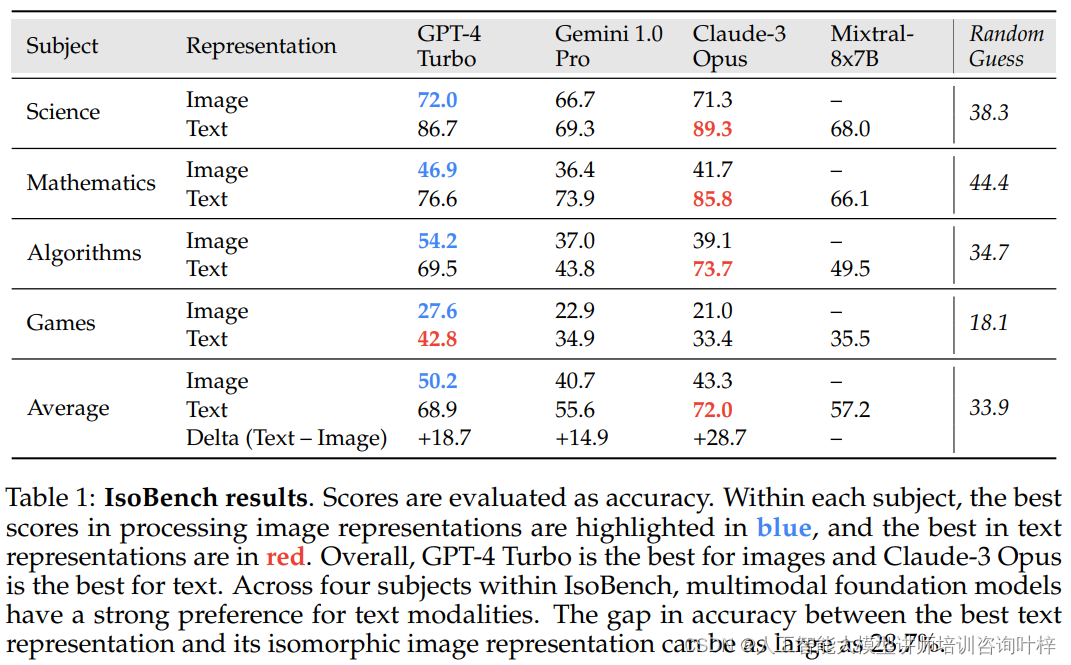
Table 1展示了IsoBench的评估结果。列出了不同的主题(科学、数学、算法、游戏)和模型(如GPT-4 Turbo、Gemini Pro、Claude-3 Opus等),并展示了在处理图像和文本表示时的准确率。图像与文本表示之间的准确率差距可达到28.7%。
这些结果对于理解多模态基础模型的内部工作机制具有重要意义。它们提示研究者,尽管这些模型被称为“多模态”,但它们在处理不同模态信息时可能并没有实现平衡,而是存在一定的偏好。这种偏好可能源于模型训练过程中数据的不平衡,或者是模型架构本身对于文本信息的处理更为优化。
这些发现还为改进多模态模型提供了方向。研究者可以考虑通过调整模型的训练策略或改进模型架构来减少这种性能差异,从而使模型在处理视觉信息时能够达到与文本信息相似的性能水平。例如,可以通过增加图像模态的训练样本或改进图像特征的提取和融合机制来提高模型的视觉理解能力。
IsoCombination and IsoScratchPad
为了应对多模态基础模型在处理不同输入模态时表现出的性能差异,研究者们提出了IsoCombination(IsoCB)和IsoScratchPad(IsoSP)两种创新的方法。这些方法旨在通过不同的策略来提高模型对视觉和文本输入的理解和处理能力,从而缩小它们在性能上的差距。
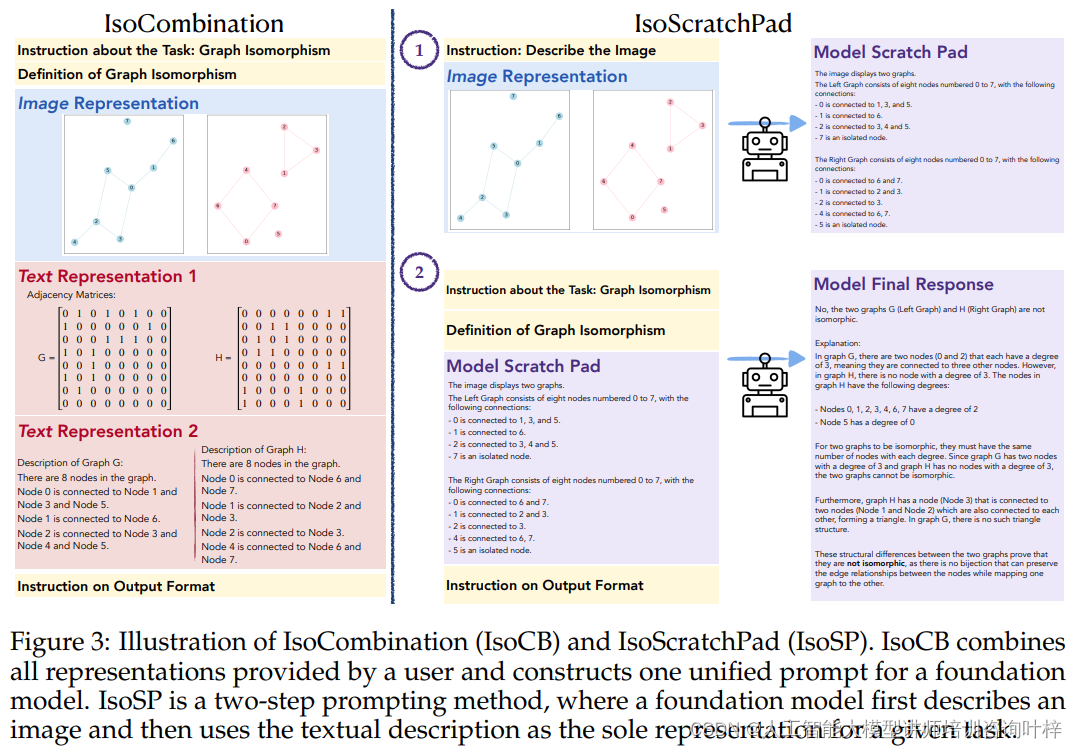
IsoCombination和IsoScratchPad两种方法的说明。IsoCB将所有用户提供的表示结合在一起,为一个基础模型构建一个统一的提示。IsoSP是一个两步提示方法,首先让基础模型描述一个图像,然后使用这个文本描述作为给定任务的唯一表示。
IsoCombination (IsoCB)
IsoCombination(IsoCB)方法的核心思想是将多种同构表示形式同时提供给模型,这样做的目的是让模型能够从不同的信息表达中提取和整合知识,以期望能够获得比单一模态输入更好的性能。例如,在处理图算法问题时,IsoCB方法通过结合图像表示和文本表示(如LATEX或故事描述),使得模型能够更全面地理解问题的本质。实践证明,这种方法能够有效地提高模型的性能,与单一最佳表示相比,性能提升最高可达9.4个百分点。这表明,多模态输入的联合效应能够显著促进模型在某些复杂任务上的表现。
IsoScratchPad (IsoSP)
与IsoCB的直接联合不同,IsoScratchPad(IsoSP)采用的是一种分两步的提示策略。IsoSP首先要求模型接收并处理视觉表示,然后将其转换为文本格式,这一步骤就像是在草稿本上做笔记一样,将视觉信息“翻译”成文本信息。接下来,模型利用这个生成的文本表示来完成特定的任务,如预测输出。这种方法特别适合于那些需要从视觉信息中提取关键细节并进行深入分析的任务。例如,在科学问题领域,IsoSP方法能够显著提高模型的性能,与直接使用图像表示相比,性能提升最多可达14.4个百分点。这证明了通过将视觉信息转换为文本信息,可以更好地激发和利用模型的文本处理能力。
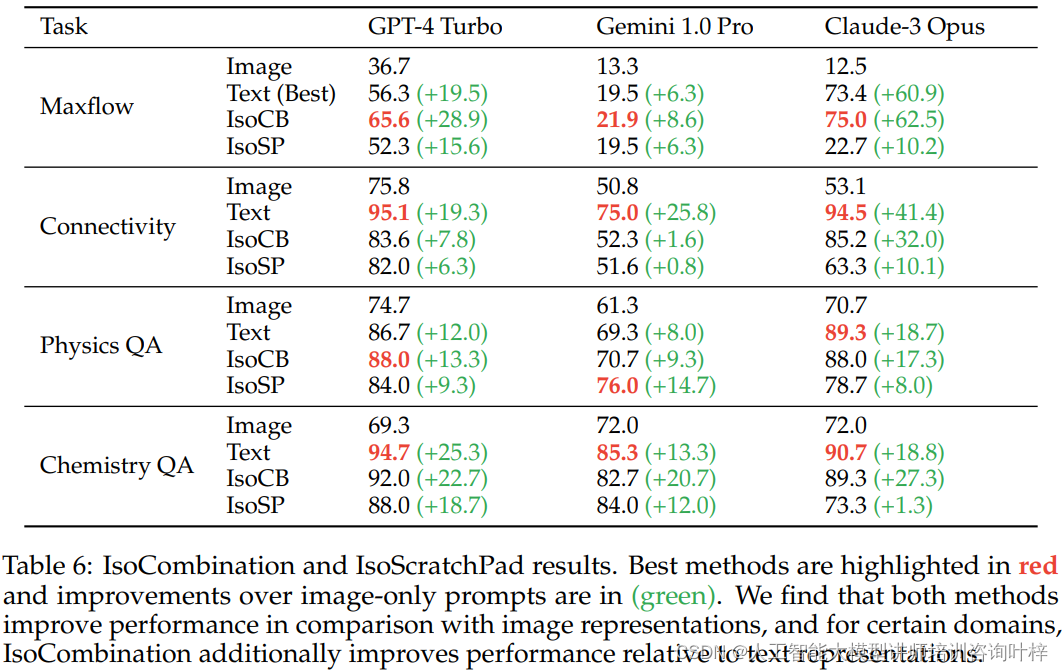
Table 6 提供了IsoCombination(IsoCB)和IsoScratchPad(IsoSP)两种方法的性能分析结果。详细展示了这两种方法在不同领域(如最大流问题、连通性、物理问答、化学问答等)对模型性能提升的影响。在表格中,最佳方法的性能用红色突出显示,而与仅使用图像提示相比的性能提升则用绿色标示。
IsoCombination(IsoCB)方法通过将所有提供的同构表示结合起来,构建一个统一的提示输入给模型。这种方法利用了不同表示形式之间的互补性,以期望模型能够更全面地理解问题。根据Table 6中的结果,IsoCB在多个任务上相对于仅使用图像提示的性能有了显著提升。例如,在处理最大流问题时,IsoCB将性能从36.7%提升到了65.6%,显示出了28.9个百分点的显著提高。
IsoScratchPad(IsoSP)方法则采用了一个两步提示策略。首先,模型接收包含视觉元素的提示,并将其转换为文本描述;然后,使用这个文本描述作为唯一的输入来完成任务。IsoSP方法的优势在于,它允许模型利用其在文本处理上的强项,同时通过自身的描述过程更深入地理解视觉信息。根据Table 6中的数据,IsoSP同样在多个领域相对于图像提示表现出了性能提升,例如在化学问答任务中,IsoSP的性能从69.3%提升到了88.0%,提高了18.7个百分点。
值得注意的是,对于某些特定领域,IsoCombination(IsoCB)不仅改善了图像提示的性能,还进一步改善了文本提示的性能。这意味着在某些情况下,结合多种表示形式的IsoCB方法甚至比单一的最佳文本提示表现得更好,这表明IsoCB在促进模型性能方面具有潜在的额外优势。
IsoCB和IsoSP这两种方法的提出,不仅展示了通过创新的提示技术和输入策略来提高多模态模型性能的可能性,也为未来多模态人工智能的发展提供了新的思路。通过这些方法的应用和进一步的优化,可以期待多模态基础模型在处理多样化输入时将变得更加均衡和高效。这对于推动多模态人工智能技术在更广泛领域的应用具有重要意义。IsoBench的建立不仅为理解多模态模型的能力提供了一个测试平台,也为未来多模态人工智能的发展提供了重要的参考和指导。
论文链接:https://arxiv.org/abs/2404.01266
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









