






 本文介绍了如何使用XGBoost进行足球运动员身价的预测,从初步的模型构建到特征工程的深入探讨,包括添加年龄属性、特征选择方法如f_regression,以及处理缺失值的策略。通过特征工程优化,模型排名显著提升。
本文介绍了如何使用XGBoost进行足球运动员身价的预测,从初步的模型构建到特征工程的深入探讨,包括添加年龄属性、特征选择方法如f_regression,以及处理缺失值的策略。通过特征工程优化,模型排名显著提升。
任务类型:回归
背景介绍: 每个足球运动员在转会市场都有各自的价码。本次数据练习的目的是根据球员的各项信息和能力值来预测该球员的市场价值。
数据来源:数据竞赛:足球运动员身价估计-SofaSofa

目前竞赛的排行榜如下:

(一)初始的XGBoost模型
属性非常多,初始的XGBoost模型选用4个属性
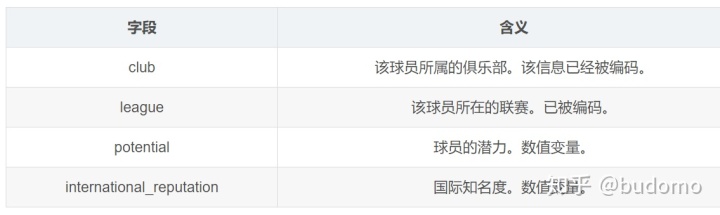
巧合的是刚好这些字段都没有缺失值。不用预处理
代码:
# 球员身价预测
import pandas as pd
import matplotlib.pyplot as plt
import xgboost as xgb
import numpy as np
from xgboost import plot_importance
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
def loadDataset(filePath):
df = pd.read_csv(filepath_or_buffer=filePath)
return df
# 只选了了4个特征建立模型
def featureSet(data):
data_num = len(data)
XList = []
for row in range(0, data_num):
tmp_list = []
tmp_list.append(data.iloc[row]['club'])
tmp_list.append(data.iloc[row]['league'])
tmp_list.append(data.iloc[row]['potential'])
tmp_list.append(data.iloc[row]['international_reputation'])
XList.append(tmp_list)
yList = data.y.values
return np.array(XList), yList
def trainandTest_mae(X_train, y_train, X_test,y_test):
# XGBoost训练过程
model = xgb.XGBRegressor(max_depth=5, learning_rate=0.1, n_estimators=160, silent=False, objective='reg:gamma')
model.fit(X_train, y_train)
# 对测试集进行预测
ans = model.predict(X_test)
#误差mae
mae=mean_absolute_error(y_test, ans)
print("mae:",mae)
# 显示重要特征
plot_importance(model)
plt.show()
# 主程序代码:
trainFilePath & 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1683
1683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









