





除了前面章节介绍的方法为,还有一种常用的工具可以分析不同阈值的分类器行为——受试者工作特征曲线(operation characteristics curve),检查ROC曲线。
ROC曲线与准确率-召回率类似,该曲线考虑了给定分类器的所有可能阈值,但他显示的是假正例率(false positive rate, FPR)和真正例率(TPR)。(真正例率只是召回率的一个名称,而假正例率是假正例占所有反类样本的比例。即:FPR = FP/(FP + TN),用roc_curve函数来计算ROC曲线。
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_test, svc.decision_function(x_test))
plt.plot(fpr, tpr, label="Roc Curve")
plt.xlabel("FPR")
plt.ylabel("TPR(recall")
#找到最接近于0的阈值
close_zero = np.argmin(abs(thresholds))
plt.plot(fpr[close_zero], tpr[close_zero], 'o', markersize=10, label="threshold zero",
fillstyle="none", c='k', mew=2)
plt.legend(loc=4)
运行后,其结果如下图:
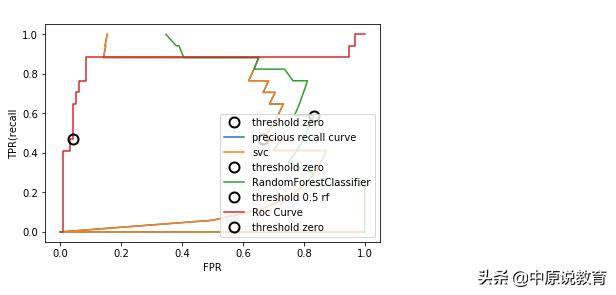
SVM的ROC曲线
对于ROC曲线,理想的曲线要靠近左上角(召回率高同时假正例率低)。从曲线结果可以看出,与默认阈值0相比,我们可以得到更高的召回率,而FPR只增加了少许,最接近左上角的点可能会比默认选择更好(工作点),同样需要注意的是:不要在测试集上选择阈值,而是应该在单独的验证集上选择阈值。
随机森林和SVM的ROC曲线对比,具体代码如下:
from sklearn.metrics import roc_curve
fpr_rf, tpr_rf, thresholds_rf = roc_curve(y_test, svc.predict_proba(x_test)[:, 1])
plt.plot(fpr, tpr, label="Roc Curve SVC")
plt.plot(fpr_rf, tpr_rf, label="Roc Curve RF")
plt.xlabel("FPR")
plt.ylabel("TPR(recall")
#找到最接近于0的阈值
close_zero = np.argmin(abs(thresholds))
plt.plot(fpr[close_zero], tpr[close_zero], 'o', markersize=10, label="threshold zero SVC",
fillstyle="none", c='k', mew=2)
close_default_rf = np.argmin(np.abs(threshold_rf - 0.5))
plt.plot(precision_rf[close_default_rf], recall_rf[close_default_rf], 'o', markersize=10, label="threshold 0.5 RF",
fillstyle="none", c='k', mew=2)
plt.legend(loc=4)
运行后其结果如下图:
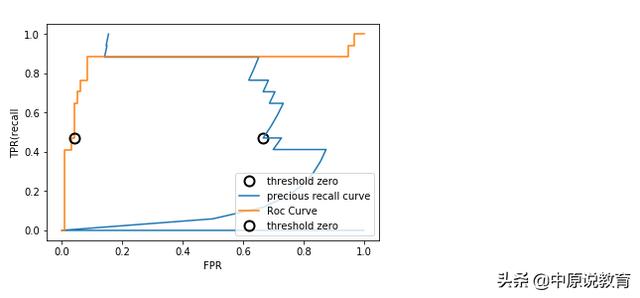
比较随机森林和SVM曲线
同理,和准确率-召回率一样,我们可以利用一个数字来总结ROC曲线,即曲线下的面积(通常称为AUC(area under the curve),这里的曲线指的就是ROC曲线),可以利用roc_auc_score来计算ROC曲线下的面积:
from sklearn.metrics import roc_auc_score
rf_auc = roc_auc_score(y_test, rf.predict_proba(x_test)[:, 1])
svc_auc = roc_auc_score(y_test, svc.decision_function(x_test))
print("AUC for random forest: {:.3f}".format(rf_auc))
print("AUC for SVC: {:.3f}".format(svc_auc))
运行后其结果为:
AUC for random forest: 0.948
AUC for SVC: 0.857
从上述运行结果可知,这里随机森林的表现仍然比SVM的好。对于不平衡的分类问题来说,AUC是一个比精度好得多的指标,AUC可以被解释为评估正例样本的排名(ranking),等价于从正类样本中随机挑选一个点,由分类器给出的分数比从反类样本中随机挑选一个点的分数更高的概率。
因此,AUC最高为1,这说明所有正雷电的分数高于所有反类点。对于不平衡问题,使用AUC模型选择通常比使用精度更有意义。
我们接下来回顾并改进一下9和非9的例子:
from sklearn.metrics import roc_auc_score
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve
digits = load_digits()
y = digits.target == 9
x_train, x_test, y_train, y_test = train_test_split(digits.data, y, random_state=0)
plt.figure()
for gamma in [1, 0.05, 0.01]:
svc = SVC(gamma=gamma).fit(x_train, y_train)
accuracy = roc_auc_score(y_test, svc.decision_function(x_test))
auc = roc_curve(y_test, svc.decision_function(x_test))
fpr, tpr, _ = roc_curve(y_test, svc.decision_function(x_test))
print("gamma = {} accuracy = {} AUC={}".format(gamma, accuracy, auc))
plt.plot(fpr, tpr, label="gamma={:.3f}".format(gamma))
plt.xlabel("FPR value")
plt.ylabel("TPR value")
plt.xlim(-0.01, 1)
plt.ylim(0, 1.02)
plt.legend(loc="best")
运行后,其结果如下图:
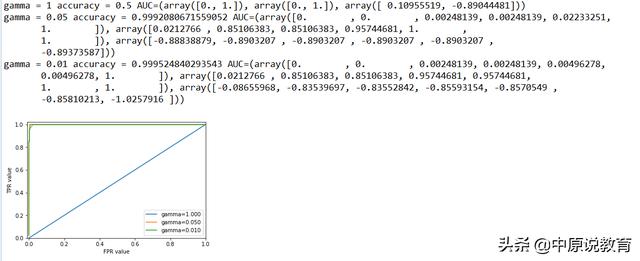
对比不同的gamma值的SVM的ROC曲线
对于三种不同的gamma设置,精度在gamma=1时最小,当gamma<=0.05的时候,精度有所增加,但是变化不大,但是AUC则变化较大,对于gamma=1.0时,AUC没有任何学习效果,相当于仍然处于随机水平,而随着gamma减小到0.05以后,起学习效果,其AUC值接近于1了,得到了较好的效果。
这意味着根据决策函数,所有正类的排名要高于所有反类。也就是利用正确的阈值,我们可以得到接近于完美的分类。因此,我们建议在不平很数据上评估模型时使用AUC,需要注意的是,AUC没有默认阈值,所以为了从高AUC模型中得到有用的分类结果,我们可能需要调节决策阈值。















 1043
1043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









