





(以下实验均在MNIST中实现)
一、CNN与CNN改进的对比
众所周知,对于CNN卷积神经网络而言,随着卷积层数的增加,其模型的准确度也会增加。那模型层数和准确度是无限地成正比例关系吗?显然不是的,众多实验已经证实,随着网络卷积层增加,准确度增加将逐渐趋缓。当模型卷积层增加到一定程度时,准确度几乎停滞甚至还会降低。为什么会产生这种原因?
我们回想CNN的全称:卷积神经网络,他最初是在解决传统的BP神经网络面临的参数爆炸而产生的。卷积核的引入大大减少了网络每次需要更新的参数。但是,CNN神经网络和传统的BP神经网络一样,是一个典型的前馈神经网络。前馈神经网络参数的更新,需要一个梯度。这个梯度我们通过反向传播时得到的传播误差求导得到。假设网络某一层的误差为
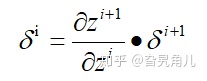
其中z是误差的差值。当
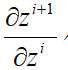
小于1的时候,随着层数的增加,其误差也会迅速衰减,这也就意味着,梯度消失了。
为了解决这个问题,在网络需要反向求导时,我们设法将浅层的梯度传递到深层去。这个时候,残差神经网络就出现了。
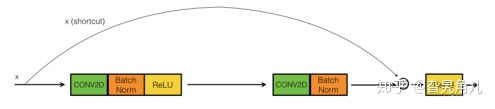
在求取当前层的梯度时,也将其前面层的梯度加入。这样在一定程度上就增大了当前层梯度,或者说,减缓了当前层梯度的衰减。
为此,我们通多一系列实验来进行检测。
首先对于CNN来说,我们设计一个四层卷积神经网络:
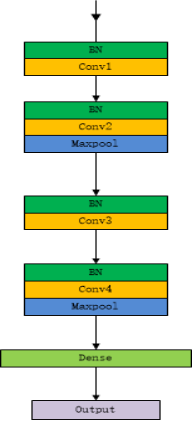
考虑到实验的便捷性,我们仅设计每层有5个卷积核,卷积核的大小设为2,每次的步长设为1。
为与CNN网络进行对比,我们同样设计一个四层的残差卷积网络,每层5个卷积核,卷积核的大小为2,每次的移动步长设1。
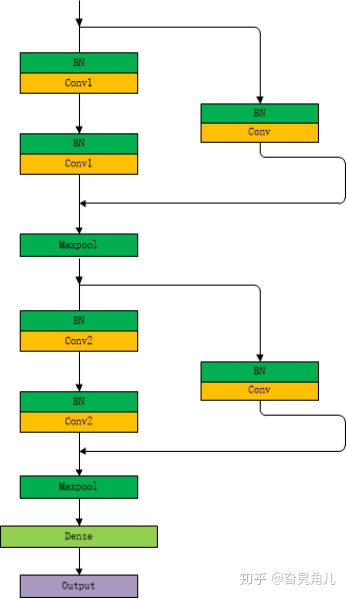
同时,我们设置Batch-Size设为150,并在100次循环中,对比两个模型的准确度和loss的变化。

如图所示,两个神经网络在进行100次运算后,网络的Loss值有着明显的不同。改进后的网络的Loss的降低速度更为迅速,且其最终的Loss也明显低于传统的CNN网络。在这其中,传统CNN的Loss最低为0.0410,而改进后的CNN的Loss则达到了0.0329。
另外我们继续考察训练完毕后其网络的准确性。如图所示:
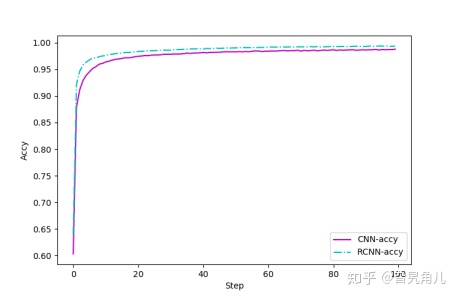
同样的,改进后的CNN相较于传统的CNN网络获得了更好的预测准确度。改进后的CNN在更短的时间内获得了更高的精度。在训练集中,传统CNN获得了0.9915的准确度,而改进后的CNN获得了0.9937的准确度。同样的,在测试集合中,传统CNN获得了0.9881的准确度,而改进后的CNN获得了0.9905的准确度。
实际上,通过两个实验我们可能感觉到二者的表现似乎不相上下,但是不要忘了,这两个的网络仅有4层,而且每层只有5个卷积核。如果模型的深度加深到数十层,并且卷积核的数目相应增加的话,两者的差距应该是相当惊人的。
当然,所有的事情都是具有两面性的。改进后的CNN,其模型更加复杂,相同情况下,为计算机的计算能力带来了更大的压力。
为了对比,我们将最初的DNN网络引入。直白来说,BNN网络就是将传统的BP神经网络进行了加深。
BP神经网络由一个输入层,一个隐含层,一个输出层构成。为便于理解,我们可以将其看作一个傅里叶变换:将隐藏层的神经元看作一个个正弦函数,全连接权重相当于正弦函数的权重。傅里叶变换告诉我们,足够多的正弦函数能够拟合任何的曲线。因此我们有理由确定,足够多的神经元可以拟合任何的结果。
为此,我们首先设置了一个四层的深度BP神经网络,也就是DNN。
我们分别测试在隐藏层神经元个数为512,1024,2048情况下的准确度,并得到如下结果:
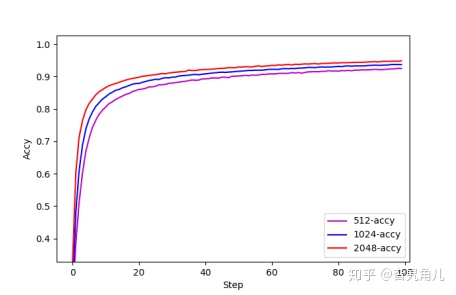
们逐渐增加神经元个数和隐藏层深度就能不断提高网络的准确度。但是,DNN神经网络是一个全连接神经网络。假设输入层的特征维度为 n,与之相连的隐含层神经元个数为N,则此层的权重系数个数就为n*N。以此类推,如果一个3通道的大小为515*512*3的图片,搭建一个拥有4层隐含层,每层1024个神经元的DNN网络,仅首层需要更新的参数就达到512*512*3*1024约为8亿个。这无异于是一个维数灾难。
况且,对于一个经典的DNN前馈式神经网络而言,随着隐含层的增加,还将面临着严重的梯度消失等一系列问题。
在此次实验的最后,我们选取了每层2018个神经元,共计4层的DNN网络,与前面提到的CNN和改进的CNN进行对比,得到如下图片:

DNN无论从收敛速度,还是最终的准确度,都无法和CNN以及改进的CNN相比。
#残差网络
#卷积网络
def cnn_model():
r = "relu"
ks = 2
st = 1
a = 0.005
model = Sequential()
model.add(normalization.BatchNormalization(input_shape=(28,28,1),beta_initializer='zero', gamma_initializer='one',name = "nor1"))
model.add(Conv2D(5,kernel_size = ks,strides = st,activation=r,kernel_initializer='random_uniform',padding="same",name = "Cov1"))
model.add(normalization.BatchNormalization(beta_init='zero', gamma_init='one',name = "nor2"))
model.add(Conv2D(5,kernel_size = ks,strides = st,activation=r,kernel_initializer='random_uniform',padding="same",name = "Cov2"))
model.add(MaxPooling2D(pool_size=2,name = "Max2"))
model.add(normalization.BatchNormalization(beta_init='zero', gamma_init='one',name = "nor3"))
model.add(Conv2D(5,kernel_size = ks,strides = st,activation=r,kernel_initializer='random_uniform',padding="same",name = "Cov3"))
model.add(normalization.BatchNormalization(beta_init='zero', gamma_init='one',name = "nor4"))
model.add(Conv2D(5,kernel_size = ks,strides = st,activation=r,kernel_initializer='random_uniform',padding="same",name = "Cov4"))
model.add(MaxPooling2D(pool_size=2,name = "Max4"))
model.add(Flatten(name = "Fla"))
model.add(Dense(100,kernel_initializer='random_uniform',activation=r,W_regularizer=l2(a),b_regularizer=l2(a),name = "Den1"))
model.add(Dropout(0.2))
model.add(Dense(10,activation="softmax",name = "Den3"))
sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',optimizer=sgd, metrics=['accuracy'])
return model
#BP网络也可以说
r = "relu"
ks = 3
st = 2
a = 0.008
input_img = Input(shape=(28*28,))
input_img_bn = normalization.BatchNormalization(beta_initializer='zero', gamma_initializer='one')(input_img)
dense1 = Dense(128,activation=r)(input_img_bn)
dense1 = Dropout(0.2)(dense1)
dense2 = Dense(256,activation=r)(dense1)
dense2 = Dropout(0.2)(dense2)
dense3 = Dense(512,activation=r)(dense2)
dense3 = Dropout(0.2)(dense3)
dense4 = Dense(512,activation=r)(dense3)
dense4 = Dropout(0.2)(dense4)
predictions = Dense(10, activation='softmax')(dense3)
model = Model(inputs=input_img, outputs=predictions)
print(model.summary())
sgd = SGD(lr=0.001, momentum=0.0, decay=0.0, nesterov=False)
model.compile(optimizer = sgd, loss='categorical_crossentropy',metrics=['accuracy'])














 2225
2225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









