





机器人路径规划(Robot Path Planning,RPP)的主要研究目的是寻找工作空间内的一条从出发点到目标点的运动路径,使机器人可以避开所有障碍物,且路径长度最短。RPP问题的相关研究成果在物流、危险物资传送、大规模集成电路设计等领域中有着广泛的应用[1-5]。在求解RPP问题的相关算法中,栅格法(Grid Method,GM)是一类较常用的环境建模方法[6-8]。一些已存在的RPP算法存在计算参数过多的问题[9-10]。例如:文献[9]提出的算法需要设置5个计算参数,而文献[10]提出的算法需要设置7个计算参数。计算参数是指算法模型的控制参数,不包括迭代次数等执行参数。计算参数过多本质上增加了算法的复杂性,给算法的实际工程应用带来困难。
本文提出一种全新的用于求解RPP问题的(Self-learning Ant Colony Optimization,SlACO),该方法使用一种改进栅格法(Improved Grid Method,IGM)进行环境建模,蚂蚁个体使用8-geometry行进规则。通过机器学习和多目标搜索策略,蚂蚁个体一次搜索可以发现多条可行路径,提高了算法计算效率。特别是该算法只需进行一个计算参数设置,简化了算法的调试过程。
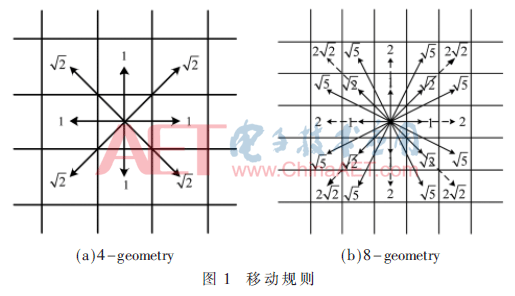
1 λ-geometry行进策略

2 自学习蚁群算法
cell(x,y)表示密度为X×Y的栅格地图中的一个单元格,(x,y)代表单元格的坐标,满足:x∈{1,2,…,X},y∈{1,2,…,Y},S表示机器人初始位置单元格,D代表目标位置单元格,pkt表示种群中第k个蚂蚁个体在t时刻的单元格位置。
2.1 改进栅格法环境建模
改进栅格法(IGM)主要用于SlACO算法的环境建模。IGM在基本栅格法的基础上做出如下改进:
(1)SlACO算法中,目标单元格D被看作食物。D通过食物分裂操作生成搜索目标并存放在集合搜索目标集合SA中。SA具体定义如下:
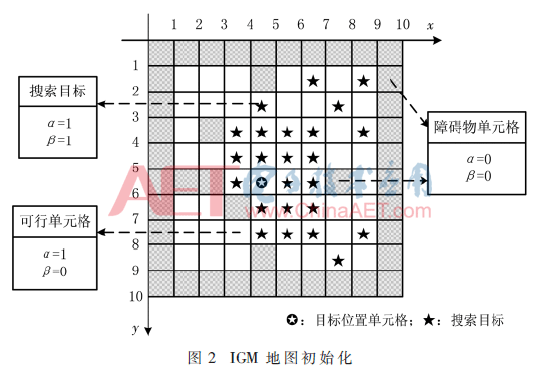
式中,l是搜索目标在集合SA中的下标,L记录了集合SA中搜索目标的总数,tcl表示SA中第l个搜索目标。当λ-geometry被使用时,有2λ个方向产生搜索目标,每个方向上可以产生多个搜索目标。SlACO算法具体执行时,食物分裂操作采用的是16-geometry。在IGM地图中,每个单元格增加两个标记α和β。α=0表示当前单元格为障碍物单元格;α=1表示当前单元格为可行域单元格。据此,IGM地图的单元格可以被形式化描述为cell(x,y) (α,β)。β=1表示当前单元格为搜索目标单元格;β=0表示当前单元格不是搜索目标单元格。通过以上设计,IGM地图中存在以下三类单元格:①障碍物单元格cell(x,y)(0,0);②可行域单元格cell(x,y)(1,0);③搜索目标单元格cell(x,y)(1,1)。
(2)大部分基于栅格法的RPP算法中,机器人每行进一步都要判断是否遇到工作空间的边界或者越界。因此,频繁判断边界是RPP算法程序的一项较大的计算开销。传统的栅格地图中,机器人判断工作空间的边界通常是根据单元格的坐标完成某种特殊处理。IGM在基本栅格地图周围增加了一层障碍物单元格。当机器人移动至工作空间的边界时,只需做常规的障碍物判断,无需做特别的边界处理。此方法虽然增加了少量的存储空间,但可以减少算法执行时的计算开销。
基于以上描述,存放IGM地图的集合GM可以被描述如下:
以一个8×8的栅格地图为例,增加边界单元格后实际密度是10×10,IGM地图的各组成部分如图2所示。
2.2 自学习蚁群算法的主要策略
2.2.1 蚂蚁个体行进策略
SlACO中蚂蚁行进策略如式(3)所示:

2.2.2 贪婪搜索策略
式(3)中,当0<r0<0.3时,antk执行贪婪搜索Greedy(RFk)。Greedy(RFk)表示antk从RFk中选择启发信息最小的单元格作为不同于其他仿生算法,SlACO算法的特点在于:启发信息来源于众多的搜索目标,而非单一的目标单元格,如图3所示。
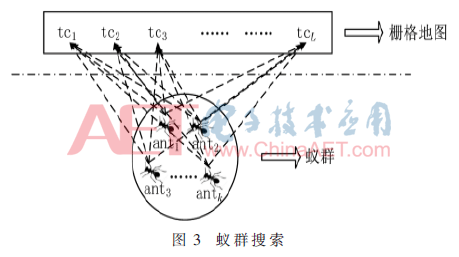
从图3可以看出:蚂蚁群的规模为K,搜索目标的规模为L。参数δ记录了SlACO中的启发信息。启发信息通过计算可达域中单元格与搜索目标之间的欧氏距离得到。由于每个蚂蚁都对应着不同的搜索目标,在不同的时刻蚂蚁个体也具有不同的可达域,因此每个蚂蚁所感知的启发信息也不同,每个蚂蚁会按有不同路线移动,增加了算法解的多样性。Antk蚂蚁在t时刻的启发信息可以通过如下公式计算:

2.2.3 强化搜索策略

强化学习的计算过程为:按信息素浓度由低到高依次对可达域中的可行单元格设置权重,其中信息素浓度最低的权重设置为:θ1=10,第二低的权值为:θ2=20,余下的值通过斐波那契数列计算得出。排序为n的单元格权重θn=θn-1+θn-2。根据单元格权重,得到各自权重空间的取值区间,其中,s1=[1,θ1],s2=[θ1+1,θ2],排序为n的单元格的权重空间为sn=[θn-1+1,θn]。按权重排序,最后一个单元格的权重为θJ,在1~δJ之间取一个随机整数r2=Rand(1,δJ)。某一时刻,如果r2∈sn,则sn单元格被选择作为下一步行进的单元格。
进一步,当antk发现一条新的路径TPk时,TPk包含的单元格的信息素按式(7)更新。
3 算法的整体描述
当栅格地图被初始化后,地图内很多单元格可能被标记为目标单元格(β=1)。t时刻,蚂蚁k可行域可能包含多个搜索目标,意味着多条安全路径被发现。SlACO算法的当前最优路径被集合BestPath记录。算法整体描述如下:
(1)初始化,设算法最大迭代次数为Gmax,种群规模K,设置BestPath←∞用于记录最优路径,设置变量k←1,l←1;
(2)用IGM方法对工作空间建模,得到地图GM,标记初始位置单元格S和目标位置单元格D;
(3)生成L个搜索目标并存放在集合SA中,并在GM中做好标记;
(4)根据式(6),设置每个单元格初始信息素值;
(5)根据式(3),完成第k只蚂蚁向第l个搜索目标向前爬行一步;
(6)判断当前可达域RFk中是否存在搜索目标,如存在,执行步骤(7),否则跳转步骤(9);
(7)根据新发现的路径更新单元格信息素;
(8)比较BestPath与新发现的可行路径,选出其中最优的最为BestPath;
(9)判断当前可达域RFk中是否存在搜索目标l,如存在,则执行步骤(10),否则跳转步骤(5);
(10)执行k←k+1,如果k≤K,则跳转至步骤(5),否则执行k←1,执行步骤(11);
(11)执行l←l+1,如果l≤L,则跳转至步骤(5);否则执行l←1,执行步骤(2);
(12)判断是否满足结束条件,如果满足,则执行步骤(13),否则执行步骤(5);
(13)输出BestPath作为最优路径。
4 仿真实验
本节主要完成SlACO算法应用于RPP问题的实验测试。实验环境为:Windows 7 32位操作系统,Intel CoreTMi5-4300U CPU,4 GB内存,仿真工具为Java语言。
4.1 算法效果仿真实验
为了检验算法的环境适应性和收敛速度,本文做了大量的仿真实验,机器人工作空间为30×30栅格地图,SlACO算法的种群规模参数设置为K=10。实验程序用符号“□”标记了机器人的运动轨迹。在数十次实验中SlACO均能规划出最优或基本最优的路径。SlACO算法规划路径的实验结果如图4所示。
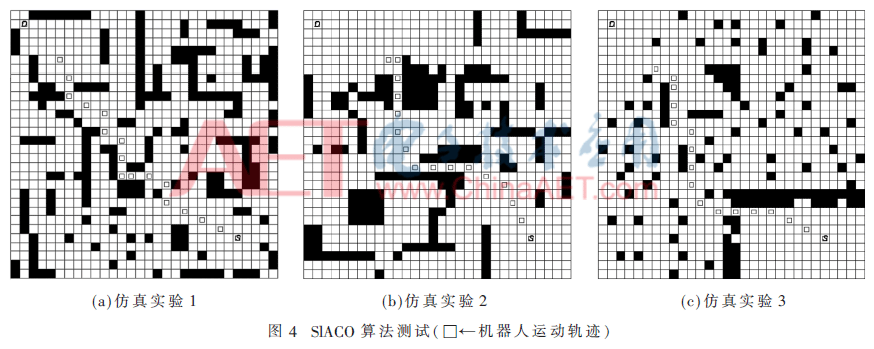
观察图4可以发现:行进轨迹的最后一个单元格与目标单元格D之间距离较长,产生这一仿真结果的原因在于多目标搜索策略使机器人可以在较远的距离发现目标单元格D,进一步缩短了规划路径的距离。由于行进方式采用8-geometry,蚂蚁个体可以1、、2、的步长行进,因此仿真实验中两个行进轨迹之间的距离并不统一,但规划路线相较于4-geometry更为平滑。
4.2 与先进算法比较
不失一般性,针对图4中的3个栅格地图,本节对SlACO、文献[9]提出的激励机制的改进蚁群算法(Incentive Mechanism Based Improved Ant Colony Optimization,IM-ACO)算法和文献[10]提出的改进蛙跳算法(Improved Shuffled Frog Leaping,ISFL)算法进行了性能比较。IM-ACO和ISFL算法的参数设置参考文献[9]和文献[10]。图4中的每个栅格地图被连续运行20次,每次迭代最大次数为50次。表1展示了算法求得的平均路径长度并使用SPSS软件对实验数据进行了秩和检验(Wilcoxon Signed-rank Test)得到秩和测试p值。表1中的“+”表示两组实验数据具有统计学差异。
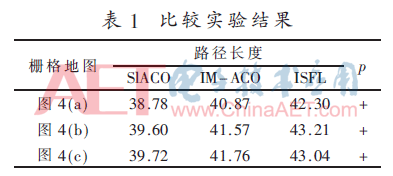
表1显示,3个栅格地图中SlACO算法规划出的路径更优。
相较于大部分已存在的RPP算法,SlACO算法的优势如下:
(1)SlACO实现单计算参数控制,可控性较好;
(2)SlACO采用的8-geometry策略,蚂蚁个体可以1、、2、的步长行进,而大部分RPP算法只可以用1、的步长行进;
(3)自学习搜索策略可以使蚂蚁沿当前最优路径寻迹搜索,对当前最优路径进一步优化,得到更优的路径;
(4)多目标搜索可以保证SlACO算法解的多样性,蚂蚁个体一次搜索可以发现多条路径;
(5)多目标搜索可以使蚂蚁个体在较远距离发现目标单元格,提高了算法的计算效率,使得搜索的路径更短。
综上所述,SlACO算法可以应用于复杂二维空间的RPP问题,而且性能稳定。
5 结论
本文介绍一种用于求解机器人路径导航问题的自学习蚁群算法,算法综合考虑了路径规划过程中的计算效率和所生成的可行路径的平滑性。8-geometry行进规则的使用保证了最终规划路线的平滑性,自学习搜索保证了算法的执行效率。相较于已存在的蚁群算法,SlACO算法中蚂蚁个体的搜索域更大,因此增加了部分计算开销;但其对搜索目标的一次行进过程可以发现多条可行路径,可以使算法的计算效率大幅增加,因此这部分计算开销可以抵消。由于SlACO算法性能较依赖搜索目标的数量,因此,如果目标单元格附近障碍物较少,那么SLACO算法的性能通常表现得更好。从实验结果来看:SlACO算法能够处理复杂工作空间的机器人路径规划问题,实验结果较为理想。
参考文献
[1] 陈明建,林伟,曾碧.基于滚动窗口的机器人自主构图路径规划[J].计算机工程,2017,43(2):286-292.
[2] 殷路,尹怡欣.基于动态人工势场法的路径规划仿真研究[J].系统仿真学报,2009,21(11):3325-3341.
[3] 刘毅,车进,朱小波,等.空地机器人协同导航方法与实验研究[J].电子技术应用,2018,44(10):144-148.
[4] 尹新城,胡勇,牛会敏.未知环境中机器人避障路径规划研究[J].科学技术与工程,2016,16(33):221-226.
[5] 唐焱,肖蓬勃,李发琴,等.避障最优路径系统研究[J].电子技术应用,2017,43(11):128-135.
[6] ERGEZER H,LEBLEBICIOGLU K.Path planning for UAVs for maximum information collection[J].IEEE Transactions on Aerospace and Electronic Systems,2013,49(1):502-520.
[7] PAMOSOAJI A K,HONG K S.A Path-planning algorithm using vector potential functions in triangular regions[J].IEEE Transactions on Systems,Man,and Cybernetics:Systems,2013,43(4):832-842.
[8] WU N Q,ZHOU M C.Shortest routing of bidirectional automated guided vehicles avoiding deadlock and blocking[J].IEEE/ASME Transactions on Mechatronics,2007,12(2):63-72.
[9] 田延飞,黄立文,李爽.激励机制改进蚁群优化算法用于全局路径规划[J].科学技术与工程,2017,17(20):282-287.
[10] 徐晓晴,朱庆保.基于蛙跳算法的新型机器人路径规划算法[J].小型微型计算机系统,2014,35(7):1631-1635.
[11] 朱庆保.复杂环境下的机器人路径规划蚂蚁算法[J].自动化学报,2006,32(4):586-593.
作者信息:
程 乐1,2,徐义晗1,卞曰瑭3
(1.淮安信息职业技术学院 计算机与通信工程学院,江苏 淮安223003;
2.河海大学 计算机与信息学院,江苏 南京210098;3.南京师范大学 商学院,江苏 南京210023)















 570
570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









