






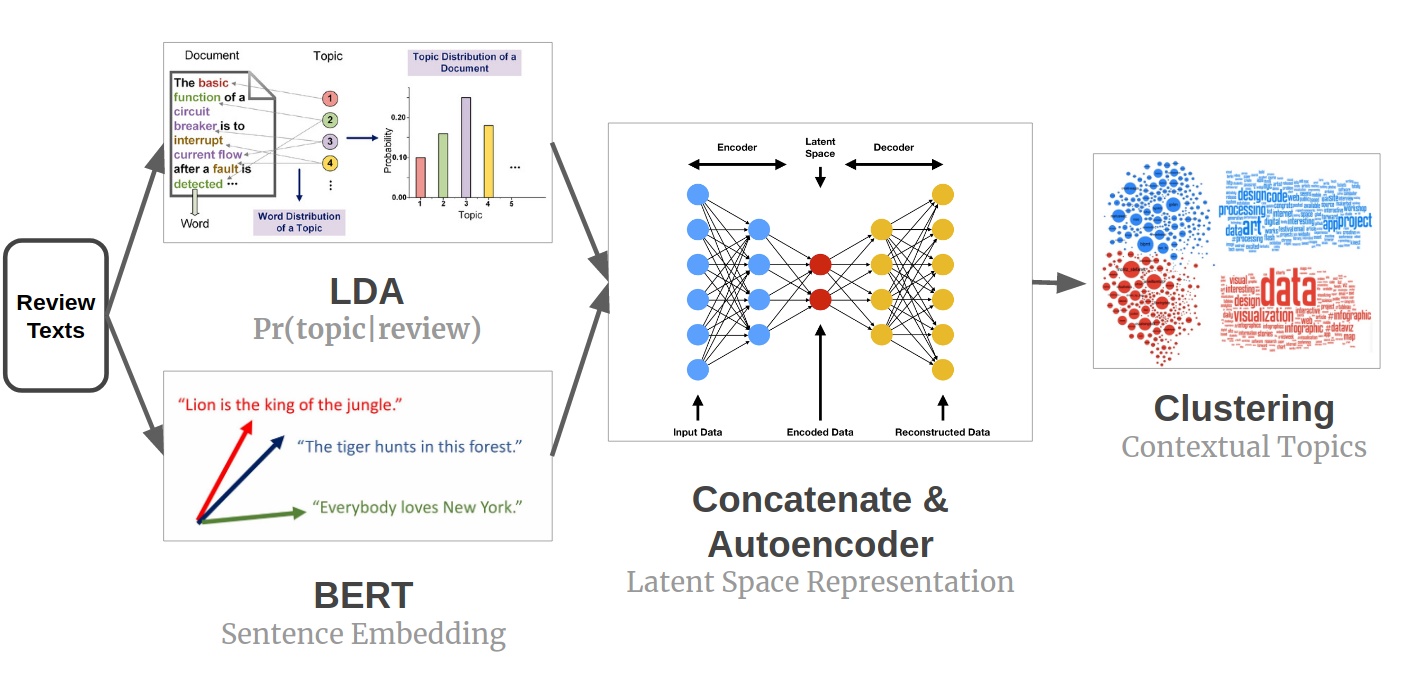
【译】上下文主题识别——从Steam评论中识别到有意义主题
作者:Steve Shao
原文:Contextual Topic Identification
翻译:litf
内容:基于Steam 评论数据集,分别比较LDA、TF-IDF+Clustering、BERT+Clustering和BERT+LDA+Clustering 4种模型识别主题的效果,评估采用主题模型的coherence和聚类的轮廓系数。实验证明:在该数据集,上下文主题识别采用BERT + LDA + Clustering是最好的。
原文链接:
https://blog.insightdatascience.com/contextual-topic-identification-4291d256a032blog.insightdatascience.com
Steam —— 电子游戏数字发行服务
Steam是最大的在线视频游戏销售平台。 虽然它有一个非常精心设计的客户评审系统,评审只能分为“积极”和“消极” ,这是没有很多信息。
产品评论是客户做出购买决策的一个极其重要的工具。 然而,由于我们处理的数据比较稀疏,每个产品的评论都很有限,因此很难从中获得有用的信息。 在这个博客中,我将描述如何使用上下文主题识别来解决这个问题,利用机器学习方法来识别语义相似的组和相似的类别标签。
数据集
我使用了Kaggle 上的《Steam评论数据集》 ,文件格式是csv。 它涵盖了 Steam 上46款畅销游戏的38万条游戏评论。 在将原始文本数据提供给模型之前,需要对其进行仔细的预处理,因此我使用 RegEx 过滤某些模式以进行标准化,以及使用 SymSpell 进行打字错误校正。
数据Pipeline
对于数据pipeline, 我使用 RegEx 和标准化技巧对原始文本数据进行了预处理。使用探索性数据分析(EDA)来深入了解数据是如何分布和结构化的,看看如何改进预处理。 然后,利用 Python 实现了主题识别模型。 请注意,我们总是可以从模型构建回到 EDA,并使其成为一个迭代过程,这样的话,我们可以获得更多有价值的信息:关于什么方法适合我们具体的数据和任务。 一旦我们训练好了最终的模型,我们可以使用 Docker、 AWS 或类似的云服务将其部署为生产模型。
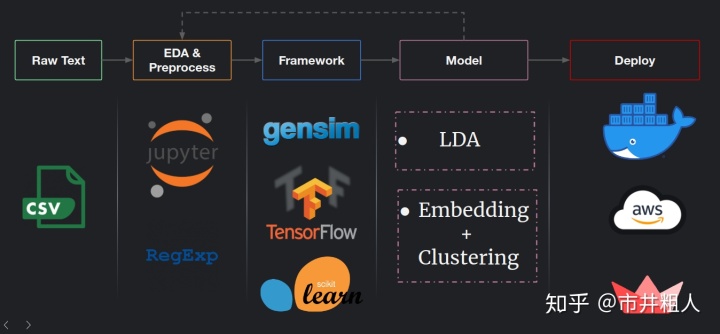
Data Pipeline 从开发到部署
模型
通常,有两种方法来完成主题标识任务。 我们可以采用层次贝叶斯模型,比如隐含狄利克雷分布模型LDA,或者我们可以将目标文档嵌入到某个向量空间中,通过聚类方法在向量空间中识别它们的相似性结构。
对于这项任务,特别是对于 Steam 评论数据,LDA 有其局限性:
- 当没有多少文本信息可以建模的时候,处理短文本是很困难的
- 评论通常不会连贯地讨论单个主题(这使得 LDA 很难确定文档的主要主题)
- 评论的实际意义很大程度上是基于上下文的,因此像 LDA 这样基于单词同现的方法可能会失败
考虑到这些局限性,我们需要一种嵌入句子全部内容的技术,然后可以用相似的主题进行聚类。 因此,嵌入加聚类似乎是这里最直接的方法。 我尝试了不同的方法从评论中获得向量表示,包括: TD-IDF,BERT 句子嵌入,以及我的最终方法:上下文主题嵌入(LDA + BERT)。
TFIDF
对于 TF-IDF 来说,结果并不好,因为我们既不能分离也不能平衡簇类别。 由于 TF-IDF 基于词袋模型(无视语法和单词顺序) ,它丢失了上下文信息,并且受到数据不连贯和非结构化的困扰。
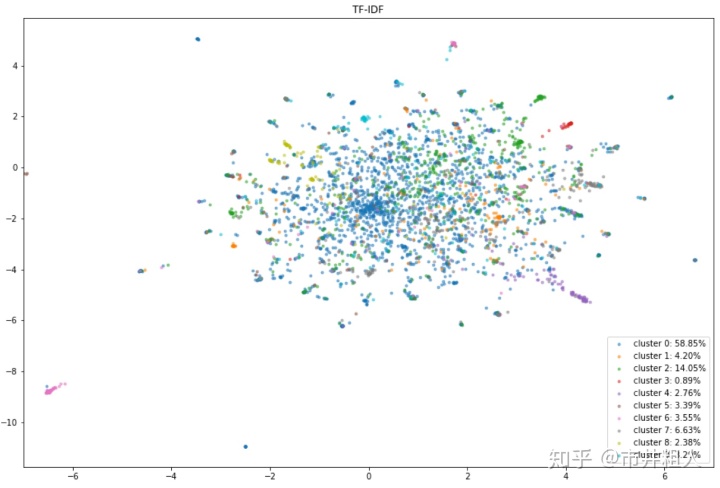
基于 TF-IDF (UMAP 二维可视化)向量的聚类结果
Bert词嵌入
然后,我尝试使用句子嵌入模型(BERT)将评论嵌入到向量空间中,其中向量捕捉句子的上下文意义。 从下面的可视化视图中可以看出,结果还可以,但是如果去掉颜色,仍然很难识别聚类。
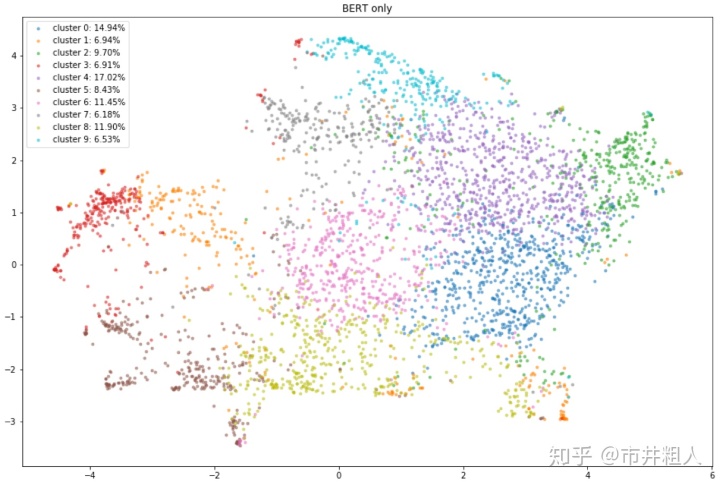
Bert 句子嵌入向量的聚类结果(UMAP 二维可视化)
上下文主题嵌入
词袋模型(LDA 或 TF-IDF)是识别主题的有效手段,它可以在文本内部连贯的情况下发现频繁的词汇。 另一方面,当语篇不连贯时,需要额外的语境信息来全面表达语篇的思想。
那么我们为什么不把这些单词和上下文信息结合起来呢? 通过结合 LDA、 BERT 和聚类,我们可以保留语义信息和创建上下文主题识别。 下面是结果,其中集群是平衡和相当分离的。
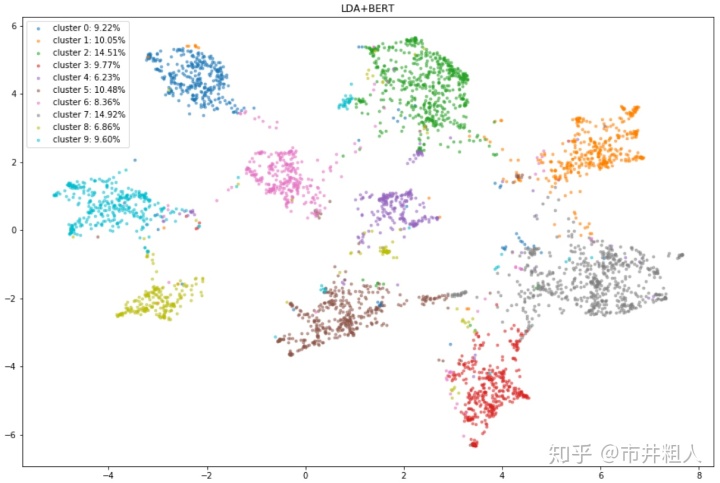
下文主题嵌入向量的聚类结果(UMAP 的二维可视化)
深入模型
那么我是怎么做到的呢? 让我们快速深入了解一下模型设计。 从每个原始评论的文本中,我们可以得到以下信息:
- 基于 LDA 的概率主题分配向量
- 基于 BERT 的句子嵌入向量
然后我将这两个向量连接起来(使用一个加权超参数来平衡每个来源信息的相对重要性)。 由于连接向量位于信息稀疏且相关的高维空间中,因此我使用自动编码器来学习连接向量的低维潜在空间表示。 假设连接向量在高维空间中具有流形形状,从而得到信息更为简洁的低维表示。 实现了基于潜在空间表示的聚类方法,并从聚类中提取上下文主题。
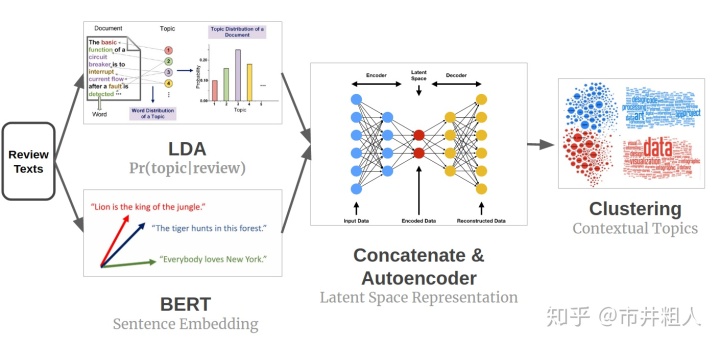
上下文主题识别模型设计
结果
这里有一些模型结果的例子,当对数据集的一部分进行拟合时,当确定主题10的数量时。
簇0
对于簇0,似乎人们关注服务器问题。

簇0:服务器问题
簇2
对于簇2,主要的话题可能是游戏中的 mod,它是许多视频游戏的一部分。
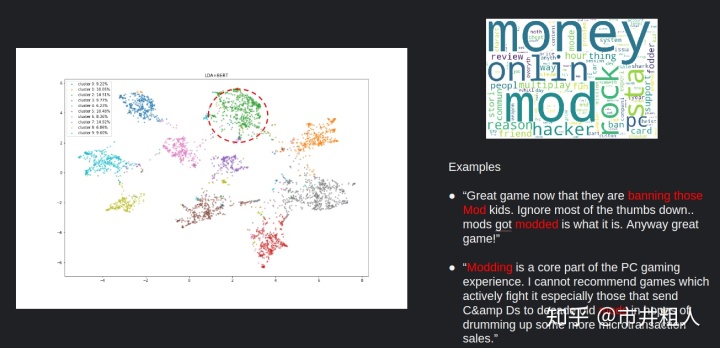
簇2:游戏中的mod
簇3
对于簇3,人们正在讨论黑客问题。

簇3:黑客问题
评估
对于评估,我选择使用主题模型的coherence和聚类效果的轮廓系数。 Coherence Umass,取值 [-14,14] ,衡量主题内高频单词的相似度。CV取值为[0,1],是基于滑动窗口的改进版本。轮廓分数在[-1,1]范围内,用于衡量簇内的一致性。 对于所有这些指标,更大的数字意味着模型做得更好。
我在 Steam 评论数据集上比较了四种不同方法的主题建模结果。 总的来说,上下文主题识别(BERT + LDA + 聚类)是最好的。
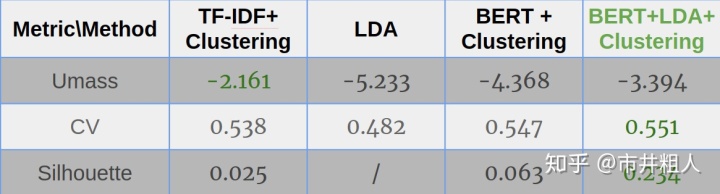
4种主题建模方法的评价指标
下一步
如果有更多时间的话,我想做有几个潜在的改进。
- 首先,我想探索更多关于数据预处理的内容。 虽然我有仔细的规范化设计,仍然有更多的工作要做
- 我还可以根据我的下游任务评估,调整句子嵌入参数
- 另一个潜在的改进是为每个产品建立定制的模型(本例中为视频游戏) ,并从中找到更多有趣的信息
Steve Sha 在2020年担任Insight AI研究员期间建立了一个为期4周的项目,即上下文相关主题识别。
github地址:
https://github.com/Stveshawn/contextual_topic_identification














 675
675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









