





目录 1.常用页面操作 ①冻结窗口 ②筛选 ③选中整行、整列 ④去重 ⑤排序 ⑥快捷键——ctrl+e 2.常用函数(数据透视表) ①VLOOKUP ②INDEX+MATCH ③IF ④COUNTIFS、SUMIFS ⑤字符串拼接(待更新具体操作) ⑥PIVOT TABLE(数据透视表) ⑦LEFT、RIGHT、MID(结合FIND、LEN)
所有内容的整理,均基于以下视频+数据。
同时,涉及到了我之前工作中常用的python(pandas)函数的扩展内容。
有什么错误/问题,大家可以留言交流一下~ O(∩_∩)O
视频link:
数据分析—EXCEL中常用的9个函数(EXCEL建议先学这9个函数)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibiliwww.bilibili.com
数据Link:https://pan.baidu.com/s/1nEdtH76HGgpW77tgDs7FpA 提取码:7p4P
1.常用页面操作
①冻结窗口
- only冻结首行:视图-冻结窗口-冻结首行
- 冻结首行+前n列:视图-拆分(拉灰色的线)-冻结窗口
②筛选
shift+ctrl+L
③选中整行、整列
- 一般:ctrl+shift+↑↓←→
- 整列不要第一行:shift+↓
④去重
数据-删除重复值
⑤排序
- 一般:开始-排序和筛选
- >=2个字段进行排序:开始-排序和筛选-自定义排序
⑥ctrl+e
不用这个功能,则可以用正则表达式。
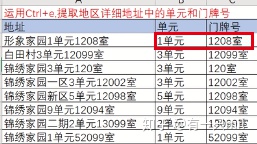
2.常用函数
①VLOOKUP(lookup_value, table_array, col_index_num, [range_lookup])
②INDEX+MATCH
---主要是在需实现VLOOKUP函数的功能,但是VLOOKUP无法实现的情况下使用,如下:
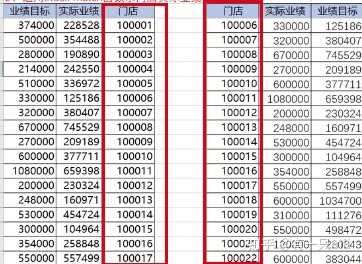
- MATCH(lookup-value,lookup-array,match-type) ——返回指定内容所在的位置:row-num
- INDEX(array,row-num,column-num)
——结合:INDEX(array,MATCH(lookup-value,lookup-array,match-type) )
③IF
举例:
- 一般:=IF(1>2,"判断真","判断假")
- 与其他函数嵌套:=IF(AND(A2>29,B2="A"),"优秀","") ——OR()
- 几个if嵌套+其他函数:
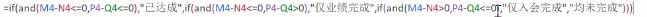
④COUNTIFS、SUMIFS
- 计“量”_=COUNTIFS(条件匹配查询区域1,条件1,条件匹配查询区域2,条件2,以此类推......)
- 计“金额”_=SUMIFS(sum_range, criteria_range1, criteria1, [criteria_range2, criteria2], ...)
----POINT:SUMIFS需要sum_range,COUNTIFS无需。
⑤字符串拼接:
注:因之前工作中ETL的内容涉及较少,所以不是很了解这部分的具体操作。
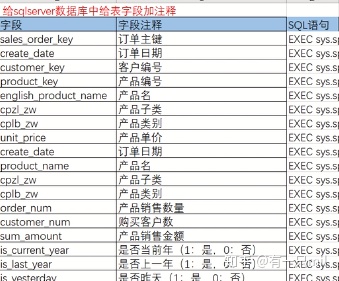
使用场景:给数据库加字典。
给数据库中表字段加注释的SQL语句
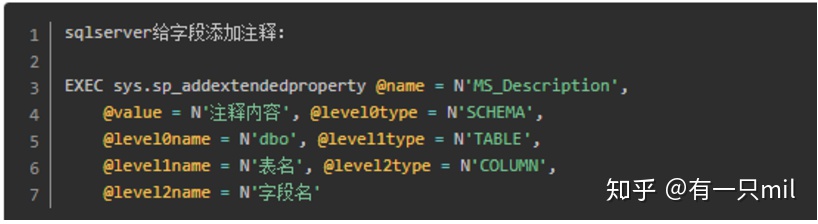

备注:go 是sql server的“间隔”
——python扩展1(pandas ):
Excel比python要复杂一些,python实现字符串拼接的方法:
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True) objs: 需要连接的对象,eg [df1, df2] axis : axis = 0, 表示在水平方向(row)进行连接 axis = 1, 表示在垂直方向(column)进行连接 join : outer, 表示index全部需要; inner,表示只取index重合的部分 join_axes: 传入需要保留的index ignore_index : 忽略需要连接的frame本身的index。当原本的index没有特别意义的时候可以使用 keys : 可以给每个需要连接的df一个label
⑥PIVOT TABLE
插入(Insert)-数据透视表(Pivot Table)

------point:筛选,这个功能可以多试试,powerbi里常用到。
——python扩展2(pandas ):
pd.pivot_table(data , values=None, index=None, columns=None,aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All') ——与EXCEL对比:index(行)、columns(列)、values+aggfunc(值)
⑦LEFT、MID、RIGHT
——可以结合FIND(查找的文本进行定位以确定其位置)+LEN函数,截取内容长度不同的东西:















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









