






gpu 图形处理专用单元 cpu是主机单元 gpu显卡处理器 专门执行复杂数学和几何计算
不同表面有不同光纤效果 必须达到快速计算能力 gpu专门设计为大规模并行吞吐处理设计
用于加速图形显示 ,
吞吐量高 峰值计算能力 4612 GFLOP/S 一秒钟可以计算4612G次浮点数计算
显存带宽高 224GB/S 224GB每秒
高可用性
英伟达GPU架构
多核cpu 若干个核心 每个核心有自己存储 处理器之前访问更大的全局内存
众核gpu 多个核心之间访问全局内存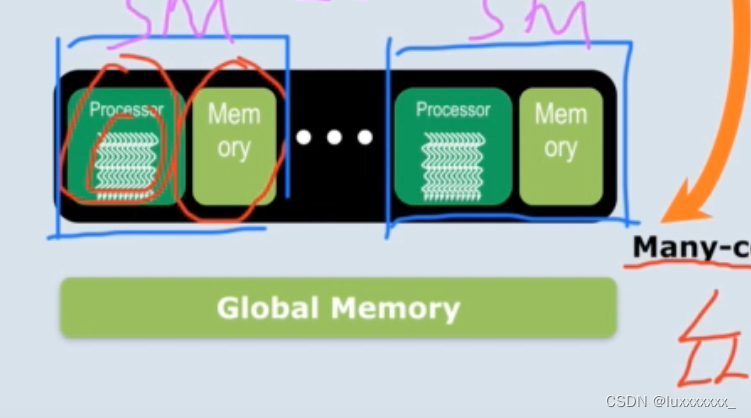
每一个sm是一个完整单元 不同sm之间共享L2缓存

每个sm有32个cuda core 每一个cuda core都有独立计算能力 浮点 int 
每个sm有 16个 load/store 不需要存储器干预进行数据存储 所以有高带宽
4个special func unit 计算esp sin cos
64kb 快速内存 速度快 32个核心共享 进行数据交换
scheduler 指令调度器分发器
tesla fermi kepler maxwell pascal


A100中的SM包含4个Tensor Core,此外还有192KB的L1 Cache/Shared Memory。
每个Tensor Core中含有16K个32位寄存器。
新的异步复制指令将数据直接从全局内存加载到共享内存中,可以选择绕过一级缓存,并且不需要使用中间寄存器文件( RF )















 1599
1599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









