









 本文深入探讨UCI人类活动识别数据集,介绍数据集来源、处理流程,并通过可视化手段展示数据特性,为后续建模打下坚实基础。
本文深入探讨UCI人类活动识别数据集,介绍数据集来源、处理流程,并通过可视化手段展示数据特性,为后续建模打下坚实基础。
【时间序列预测/分类】 全系列60篇由浅入深的博文汇总:传送门
上篇文章介绍了人类活动识别常用的方法、最新进展和面临的挑战。UCI人类活动识别数据集是人类活动识别领域的benchmark数据集(还有一个常用的特征维数和活动种类更多的OPPORTUNITY数据集,会在之后的文章中介绍),本文详细介绍了UCI-HAR数据集,并通过该数据集来探索加载数据集方法、数据可视化流程、问题建模分析以及模型评估思路,为以后的建模实现分类任务打好基础。
文章目录
前言
人类活动识别是将专用硬件设备或智能手机记录的加速度计数据序列分类为已知的明确运动的问题。考虑到每秒产生的大量观测数据、观测数据的时间性质以及缺乏将加速度计数据与已知运动联系起来的明确方法,这是一个具有挑战性的问题。经典的方法包括基于固定大小窗口的时间序列数据和训练机器学习模型(如决策树集合)的人工提取特征的方法。困难在于,特征工程需要有信号处理、数理统计、机器学习等领域的专业知识。近年来,诸如递归神经网络(RNN)和一维卷积神经网络(CNN)等深度学习方法被证明能够在很少或没有数据特征工程的情况下,为具有挑战性的活动识别任务提供最好的表现。本文主要内容如下:
- UCI-HAR 数据集详细介绍。
- 如何加载数据集和处理数据。
- 如何使用折线图、直方图和方框图来更好地理解数据。
- 如何对问题建模,包括框架、数据准备、建模和评估。
1. UCI-HAR 数据集介绍
1.1 简介
UCI 人类活动识别数据集是以智能手机采集的传感器数据为基础的活动识别,创建于2012年,实验团队来自意大利热那亚大学。在2012年的论文《Human Activity Recognition on Smartphones using a Multiclass Hardware-Friendly Support Vector Machine》中,采用机器学习算法建模,提供了该数据集分类性能的baseline。在2013年的论文《A Public Domain Dataset for Human Activity Recognition Using Smartphones》中,对数据集进行了全面描述。数据集可以从UCI机器学习存储库免费下载:👉传送门。
这些数据是从30名年龄在19岁到48岁之间的志愿者身上收集的,这些志愿者将智能手机绑在腰间,进行6项标准活动中的一项,通过开发的手机软件记录运动数据。同时记录每个执行活动的志愿者的视频,后期根据这些视频和传感器数据进行手动标记所属运动类别(类似剪辑视频中的音画同步)。执行的六项活动如下:
1. Walking
2. Walking Upstairs
3. Walking Downstairs
4. Sitting
5. Standing
6. Laying
选择30名年龄在19-48岁之间的志愿者作为研究对象。记录的运动数据是来自智能手机(特别是三星Galaxy S II)的x、y和z加速度计数据(线性加速度)和陀螺仪数据(角速度),采样频率为 50Hz(每秒50个数据点)。每名志愿者进行两次活动序列,第一次在设备位于腰间左侧,第二次测试时,智能手机由用户自己按喜好放置。
1.2 数据收集、处理流程
原始数据不可用。数据集,提供了数据集的预处理版本。预处理步骤包括:
- 使用噪声滤波器对加速度计和陀螺仪进行预处理。
- 将数据分割成2.56秒(128个数据点)的固定窗口,重叠50%。
- 将加速度计数据分为重力(总)和人体运动分量。
我们使用手机加速度计和陀螺仪以50Hz 的采样率收集了三轴线性加速度和角速度信号。使用中值滤波器和截止频率为 20Hz的三阶低通Butter-worth滤波器对这些信号进行了预处理,以降低噪声。 该速率足以捕获人体运动,因为其能量的99%包含在15Hz以下[3]。 使用另一个巴特沃斯低通滤波器将具有重力和人体运动成分的加速度信号分离为人体加速度和重力。 假定重力仅具有低频分量,因此从实验中我们发现,对于恒定重力信号,0.3Hz是最佳转折频率。
将特征工程应用于窗口数据,并提供具有这些经过特征工程的数据。从每个窗口中提取了人类活动识别领域中常用的一些时间和频率特征。结果是一个561元素的特征向量。数据集根据受试者的数据分为训练集(70%)和测试集(30%),例如,训练21名受试者,测试9名受试者。
更多详细信息请查看上文提到的两篇论文。
1.3 难点解惑
论文提出一个问题的框架,通过有分类标签的数据样本进行建模训练,以预测预测新对象上的运动活动。乍一看比较难理解的几个数据:
561:特征工程之后的特征数,关于这些特征的说明,在数据集中的 features.txt和features_info.txt 作了详细说明,因为我们都是使用处理好的九轴传感器数据来建立深度学习模型,此处不再赘述。128:数据集shape的第二个维度 128,看论文就很清楚了,在2.56秒的固定宽度滑动窗口中对时间信号进行采样,有50%的重叠。(2.56sec×50Hz = 128cycles)7352和2947:数据集中将训练集和测试集中的传感器数据按照一个特征一个txt的格式各分成了9个文件,如下图所示。7352和2947是测试集和训练集中每个txt文件shape的第一个维度,表示重采样之后的样本个数。一定要理解好数据集的shape!

1.4 训练集和测试集文件下的文件介绍
训练集和测试集文件下的文件,文件格式相同、数量相同。我们以训练集文件夹下的文件为例说明:
一级目录:
test:测试集数据;
train:训练集数据;
activity_labels.txt:活动的真实标签(6个);
features.txt:特征工程的特征;
features_info.txt:特征工程处理说明;
二级目录:
X_train.txt:未经处理的原始数据,这个不用,可以不关心;y_train.txt:活动类别标签(数字1-6表示),shape为(7352,1);说明:注意这里的标签是从1开始表示第一类,而one-hot编码是从0开始,注意编码的时候要减去1!这个在以后的建模过程中会遇到,先说明一下。subject train.txt:将训练集的每一个样本与志愿者编号(1-30)对应,即给每条样本记录属于哪位志愿者做标识,shape为(7352,1);
三级目录:
body_acc_x_train.txt、body_acc_y_train.txt、body_acc_z_train.txt:三轴的加速度数据;body_gyro_x_train.txt、body_gyro_y_train.txt、body_gyro_z_train.txt:三轴的陀螺仪数据(角速度);total_acc_x_train.txt、total_acc_y_train.txt、total_acc_z_train.txt:三轴的重力加速度数据;
test 文件夹下的文件结构跟 train 文件夹下是相同的,只是shape不一样。本文和以后的几篇文章中,使用的都是这两个文件夹下的数据作为训练数据和测试数据,不使用原始数据和经过特征工程的数据。
2. 加载数据
使用panda中的read_csv()方法将单个文件加载为DataFrame格式,然后通过自定义的函数实现批量加载,通过numpy的不同维度的stack方法,将所有数据集重塑成为训练样本和测试样本的三维数组。
2.1 加载单个文件
def load_file(filepath):
dataframe = pd.read_csv(filepath, header=None, delim_whitespace=True)
return dataframe.values
2.2 加载所有文件
有之前有关时间序列预测任务的经验之后,我们知道对于CNN和LSTM来说,对多变量的训练数据的shape有严格的规定,因此自定义了这个函数,来将原训练数据进行加载,并重塑成CNN和LSTM等网络架构期望的输入shape:[样本、时间步长、特征]。
下文的 load_dataset() 函数实现了此功能。没有使用参考文章中的加载数据方法,那种方法在我第一次阅读代码的时候比较难懂,有些地方写死了,换成自己的数据集就不适用了;因此重写了该函数,简化代码的同时易于理解,方便扩展。下文的代码也是如此,为了简化代码,提高可读性和可扩展性,减少修改源代码,做了许多重写。代码中各函数的功能都做了说明,难理解的地方做了注释。保姆用心良苦a ~
先导入必要的模块:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
代码实现:
def load_dataset(data_rootdir, dirname, group):
'''
该函数实现将训练数据或测试数据文件列表堆叠为三维数组
'''
filename_list = []
filepath_list = []
X = []
# os.walk() 方法是一个简单易用的文件、目录遍历器,可以高效的处理文件、目录。
for rootdir, dirnames, filenames in os.walk(data_rootdir + dirname):
for filename in filenames:
filename_list.append(filename)
filepath_list.append(os.path.join(rootdir, filename))
#print(filename_list)
#print(filepath_list)
# 遍历根目录下的文件,并读取为DataFrame格式;
for filepath in filepath_list:
X.append(load_file(filepath))
X = np.dstack(X) # dstack沿第三个维度叠加,两个二维数组叠加后,前两个维度尺寸不变,第三个维度增加;
y = load_file(data_rootdir+'/y_'+group+'.txt')
print('{}_X.shape:{},{}_y.shape:{}\n'.format(group,X.shape,group,y.shape))
return X, y
查看训练集测试集shape
train_rootdir = 'D:/GraduationCode/01 Datasets/UCI HAR Dataset/train/'
test_rootdir = 'D:/GraduationCode/01 Datasets/UCI HAR Dataset/test/'
data_dirname = '/Inertial Signals/'
trainX, trainy = load_dataset(train_rootdir, data_dirname, 'train')
testX, testy = load_dataset(test_rootdir, data_dirname, 'test')
输出:
train_X.shape:(7352, 128, 9),train_y.shape:(7352, 1)
test_X.shape:(2947, 128, 9),test_y.shape:(2947, 1)
3. 活动类别平衡性分析
可视化数据集第一步是查看活动分类的分布情况。30位志愿者每一位都完成了6项活动。我们需要检查数据是否平衡,使建模更容易,可以自定义一个函数来查看各类别的情况,例如标签文件 train_y.txt,test_y.txt。代码实现:
def class_distribution(data):
'''
该函数实现各分类数据的数量和百分比统计
'''
df = pd.DataFrame(data) # 转化为DataFrame格式
counts = df.groupby(0).size() # axis=0沿行分组;size()方法统计每个组的大小
print(counts)
counts = counts.values
print(counts)
for i in range(len(counts)):
percent = counts[i] / len(df) * 100
print('Class=%d, total=%d, percentage=%.3f%%' % (i+1, counts[i], percent))
print('Train Dataset Class Distribution')
class_distribution(trainy)
print('Test Dataset Class Distribution')
class_distribution(testy)
print('Total Class Distribution')
combined = np.vstack((trainy, testy))
class_distribution(combined)
输出:
Train Dataset Class Distribution
0
1 1226
2 1073
3 986
4 1286
5 1374
6 1407
dtype: int64
[1226 1073 986 1286 1374 1407]
Class=1, total=1226, percentage=16.676%
Class=2, total=1073, percentage=14.595%
Class=3, total=986, percentage=13.411%
Class=4, total=1286, percentage=17.492%
Class=5, total=1374, percentage=18.689%
Class=6, total=1407, percentage=19.138%
Test Dataset Class Distribution
0
1 496
2 471
3 420
4 491
5 532
6 537
dtype: int64
[496 471 420 491 532 537]
Class=1, total=496, percentage=16.831%
Class=2, total=471, percentage=15.982%
Class=3, total=420, percentage=14.252%
Class=4, total=491, percentage=16.661%
Class=5, total=532, percentage=18.052%
Class=6, total=537, percentage=18.222%
Total Class Distribution
0
1 1722
2 1544
3 1406
4 1777
5 1906
6 1944
dtype: int64
[1722 1544 1406 1777 1906 1944]
Class=1, total=1722, percentage=16.720%
Class=2, total=1544, percentage=14.992%
Class=3, total=1406, percentage=13.652%
Class=4, total=1777, percentage=17.254%
Class=5, total=1906, percentage=18.507%
Class=6, total=1944, percentage=18.876%
可以看到每个类的分布非常相似,基本上占数据集的13%到19%之间。测试集和两个数据集的结果看起来非常相似。假设训练集和测试集以及每个主题的类分布是平衡的,那么使用数据集很可能是安全的。
4. 绘制各特征数据折线图
我们正在处理时间序列数据,因此需要查看训练数据的折线图。数据由每个变量的时间序列的窗口窗口宽度为128的滑动窗口截取,窗口有50%的重叠。这意味着,除非消除重叠,否则绘图中会包含一些重复的线图。
4.1 获取训练集/测试集中的志愿者编号
加载train目录中的 subject train.txt 文件,该文件包含训练集中是哪些志愿者的数据,包含志愿者的编号(1-30中的数字)。先使用上文自定义的 load file() 函数加载此文件,然后使用numpy的unique函数来获取这些这些志愿者的唯一索引列表。代码实现:
sub_map = load_file('D:/GraduationCode/01 Datasets/UCI HAR Dataset/train/subject_train.txt')
train_subjects = np.unique(sub_map) # 找到训练集中包含哪些志愿者(返回唯一索引列表)的数据(数据集由30位志愿者收集)
print('sub_map.shape:{}\ntrain_subjects:{}'.format(sub_map.shape,train_subjects))
输出:
sub_map.shape:(7352, 1)
train_subjects:[ 1 3 5 6 7 8 11 14 15 16 17 19 21 22 23 25 26 27 28 29 30]
4.2 截取指定志愿者所属的数据样本
接下来,我们需要一种方法来检索单个志愿者的所有数据样本,例如编号为1的志愿者。通过查找属于给定志愿者的所有行号来完成此操作,并使用这些行号从训练数据集中切分X和y。 这里说明一点,subject train.txt,y_train.txt 以及 body_acc_x_train.txt、body_acc_y_train.txt、body_acc_z_train.txt 等9个文件,这些文件的第一个维度是相同的,都为(7352,)。所以索引也是一一对应的,因此可以根据志愿者文件中的索引来截取训练样本和测试样本的数据。代码实现:
def data_for_subject(X, y, sub_map, sub_id):
'''
该函数实现根据志愿者编号来从数据X和标签y中截取相应的行数据
'''
ix = [i for i in range(len(sub_map)) if sub_map[i]==sub_id]
return X[ix, :, :], y[ix]
4.3 数据样本去重叠
获取某一个志愿者的样本之后,为避免原样本对绘图有影响,需要先消除这种重叠,并将给定变量的窗口压缩成一个可以直接绘制为折线图的序列片段。代码实现:
def to_series(windows):
'''
该函数实现将窗口序列数据转换为列表
'''
series = list()
for window in windows:
# 消除重叠窗口部分
half = int(len(window) / 2) - 1 # 窗口一半的宽度;原数据重叠率为50%
# 切片截取每一行的后半部分数据,正好避开重叠部分(上一行的后半部分和下一行的前半部分是重叠的)
for value in window[-half:]:
series.append(value)
return series
4.4 绘制指定志愿者的训练样本/测试样本折线图
重写获取志愿者编号的方法:
def get_sub_map(sub_filepath):
'''
该函数实现获取训练集或测试集中包含志愿者编号的唯一索引列表
sub_filepath:subject_train.txt/subject_test.txt文件路径;
filename:'train'/'test';
'''
sub_map = load_file('D:/GraduationCode/01 Datasets/UCI HAR Dataset/train/subject_train.txt')
subjects_list = np.unique(sub_map) # 找到训练集中包含哪些志愿者(返回唯一索引列表)的数据(数据集由30位志愿者收集)
return sub_map, subjects_list
查看编号为1的志愿者的数据情况:
subject_train_path = 'D:/GraduationCode/01 Datasets/UCI HAR Dataset/train/subject_train.txt'
train_sub_map, train_subjects = get_sub_map(subject_train_path)
train_sub_id = train_subjects[0] # 志愿者列表中编号为1的志愿者
train_subX, train_suby = data_for_subject(trainX, trainy, train_sub_map, train_sub_id)
print('train_subX.shape:{}\ntrain_suby.shape:{}'.format(train_subX.shape, train_suby.shape))
输出:
train_subX.shape:(347, 128, 9)
train_suby.shape:(347, 1)
可以看到编号为1的志愿者的训练样本shape和训练标签的shape。
绘图函数完整代码:
def plot_subject(X, y):
'''
该函数实现根据志愿者标号绘制其9轴传感器数据和活动变化图
共十个子图
'''
plt.figure(figsize=(12,20), dpi=150)
n, off = X.shape[2] + 1, 0 # X的第三个维度为特征数9(9轴传感器数据)
name_list = ['total acc ', 'body acc ', 'body gyro ']
axis_list = ['x', 'y', 'z']
for name in name_list:
for i, axis in enumerate(axis_list, start=0):
plt.subplot(n, 1, off+1) # 创建n行1列的画布,在off+1位置绘图;
# X[:,:,off] 三维数组切片中,off通过for循环实现递增,
# 一次截取一个特征的所有数据(二维数组),输入到to_series函数进行处理,实现去除重叠部分。
plt.plot(to_series(X[:,:,off]))
plt.title(name + axis, y=0, loc='left', size=18)
plt.ylabel(r'$Value$', size=16)
plt.xlabel(r'$timesteps$', size=16)
off += 1
plt.subplot(n, 1, n)
plt.plot(y)
plt.title('activity', y=0, loc='left', size=18)
plt.ylabel(r'$Class$', size=16)
plt.xlabel(r'$Nums$', size=16)
plt.tight_layout()
plt.show()
绘制编号为1的志愿者数据情况:
plot_subject(train_subX, train_suby)
输出:
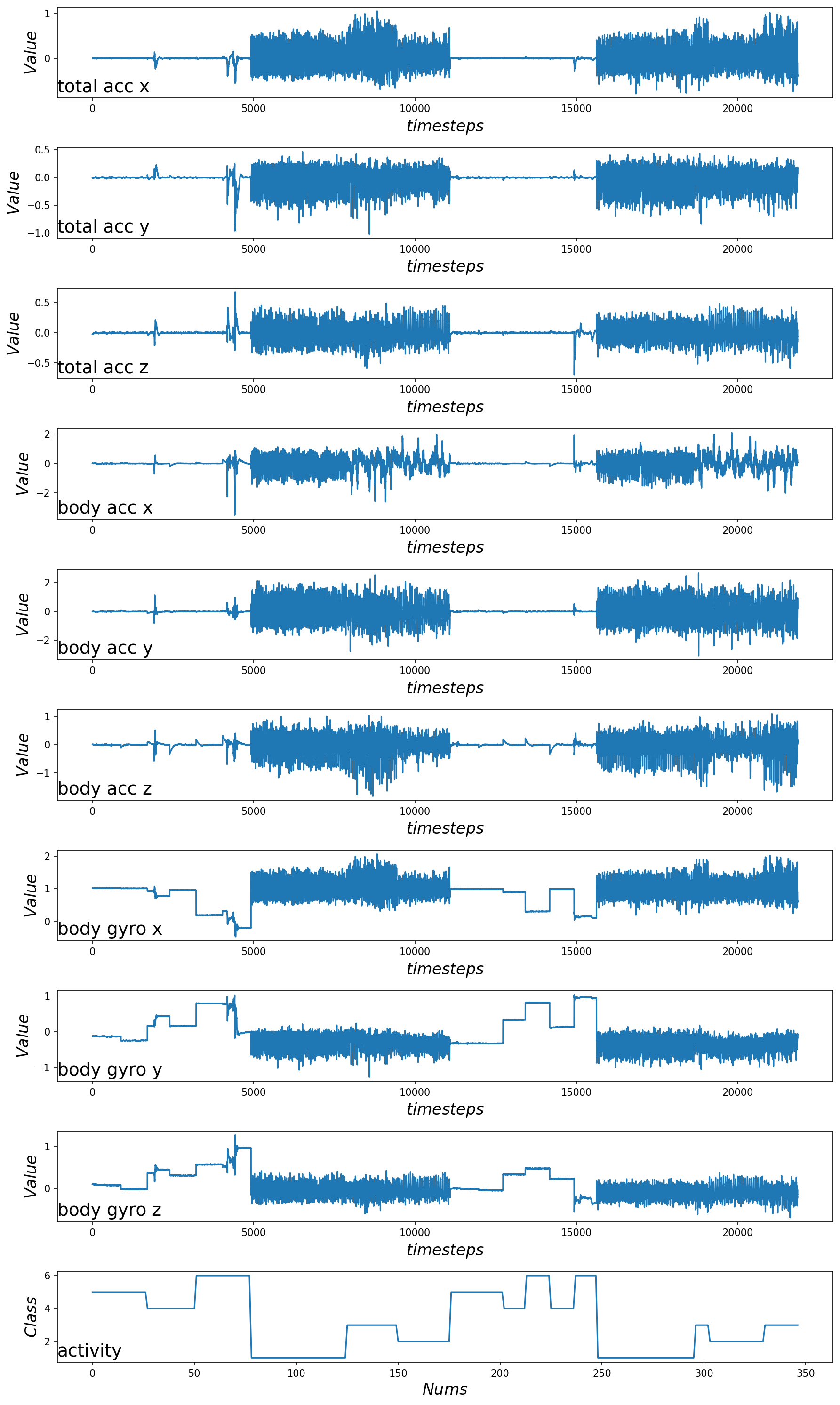
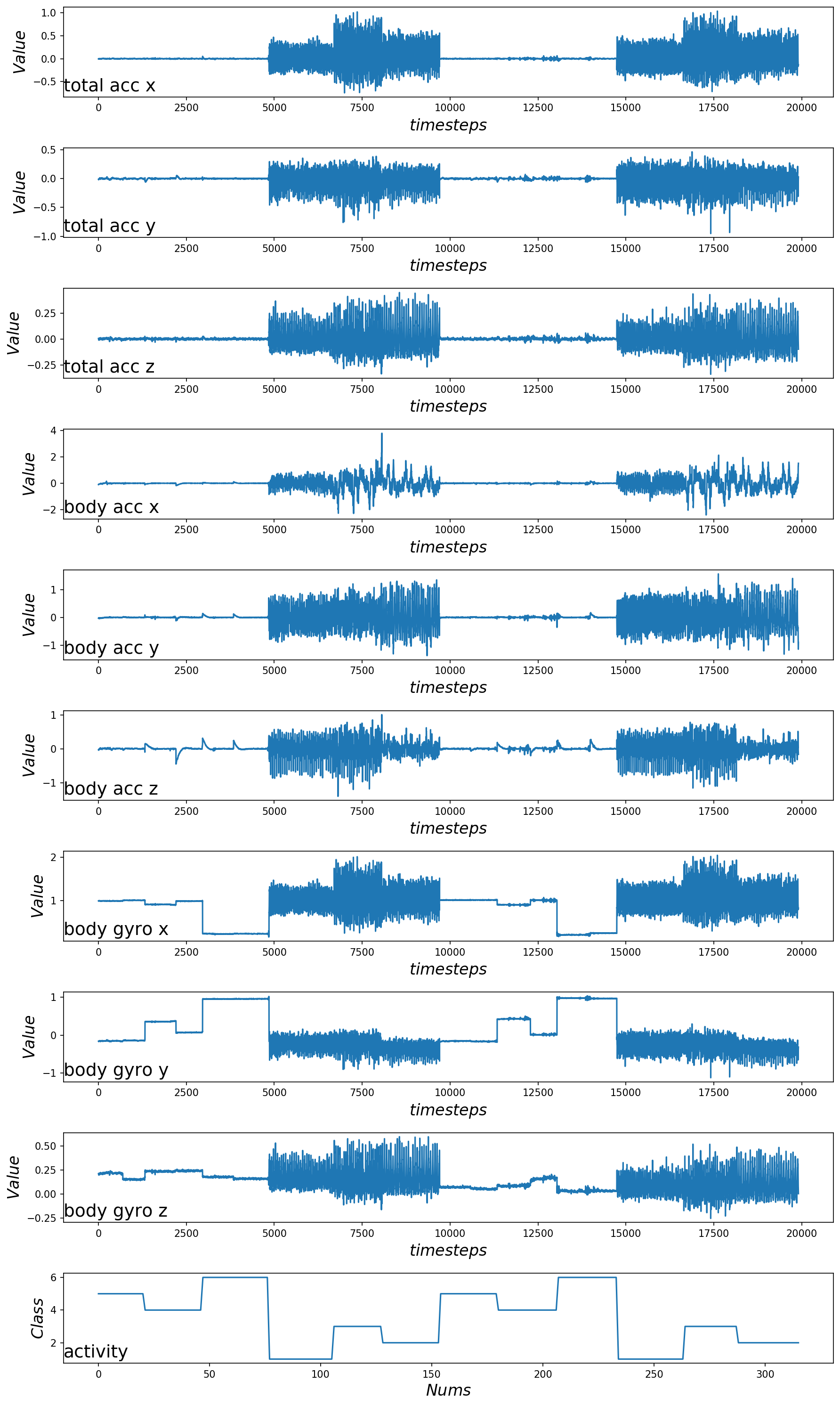
从图中可以看出活动1、2、3(与步行活动相关)相对应的曲线比较密集,活动4、5和6(坐着,站着和躺着)的虚线相对比较平缓,基本上为直线。这很好地证实了已正确加载的数据集的解释。
还可以看出,这个主体执行了两次相同的一般活动序列(回忆前文,两次执行,一次将手机绑在腰间,一次任意放置。),并且某些活动执行了两次以上。这表明,对于给定的主题,我们不应假设可能已经执行了哪些活动或其顺序。我们还可以看到一些固定活动(例如躺下)的曲线的波动相对较大,这些可能是异常值或与活动转换有关。最后,我们看到这九个变量之间有很多共性。很可能只需要这些迹线的一个子集就可以建立预测模型。
查看志愿者编号为11的数据情况
train_sub_id = train_subjects[6] # 列表中的第7位志愿者编号为11
train_subX, train_suby = data_for_subject(trainX, trainy, train_sub_map, train_sub_id)
print('train_subX.shape:{}\ntrain_suby.shape:{}'.format(train_subX.shape, train_suby.shape))
plot_subject(train_subX, train_suby)
输出:
5. 查看每位志愿者的数据分布情况(直方图)
由于问题已经解决,我们对使用某些受试者的运动数据来预测其他受试者的运动感兴趣。这表明跨对象的运动数据必须具有规律性。我们知道数据大概在-1和1之间缩放,每个对象的运动幅度是相似的。我们还希望,假设运动对象执行相同的动作,他们之间的运动数据分布也会相似。可以通过绘制并比较跨对象的运动数据的直方图来进行检查。
一种有用的方法是为每个对象创建一个图并绘制给定数据的所有三个轴(例如,总加速度),然后对多个对象重复此操作。可以将图修改为使用相同的轴并水平对齐,以便可以比较对象之间每个变量的分布。代码实现:
def plot_subject_histograms(X, y, sub_map, sensor_type_id, n_subs=10):
'''
该函数实现绘制指定数量志愿者的三轴传感数据直方图;
sensor_type_id:指定绘制哪三轴,可选取值0,3,6;
n_subs=10:表示默认绘制前十名志愿者的数据;
'''
plt.figure(figsize=(12,20), dpi=150)
subject_ids = np.unique(sub_map[:, 0]) # 获取训练集或者测试集中所有志愿者的编号
for i in range(n_subs):
sub_id = subject_ids[i]
subX, _ = data_for_subject(X, y, sub_map, sub_id) # 根据志愿者编号截取相应的数据
for j in range(3):
ax = plt.subplot(n_subs, 1, i+1)
ax.set_xlim(-1, 1)
ax.hist(to_series(subX[:, :, sensor_type_id+j]), bins=100, density=True, histtype='bar', stacked=True)
plt.title(f'sub_id:{sub_id}', y=0, loc='left', size=18)
plt.tight_layout()
plt.show()
plot_subject_histograms(trainX, trainy, train_sub_map, sensor_type_id=0) #10位志愿者总的加速度数据分布图
plot_subject_histograms(trainX, trainy, train_sub_map, sensor_type_id=3) #...身体加速度
plot_subject_histograms(trainX, trainy, train_sub_map, sensor_type_id=6) #...重力加速度
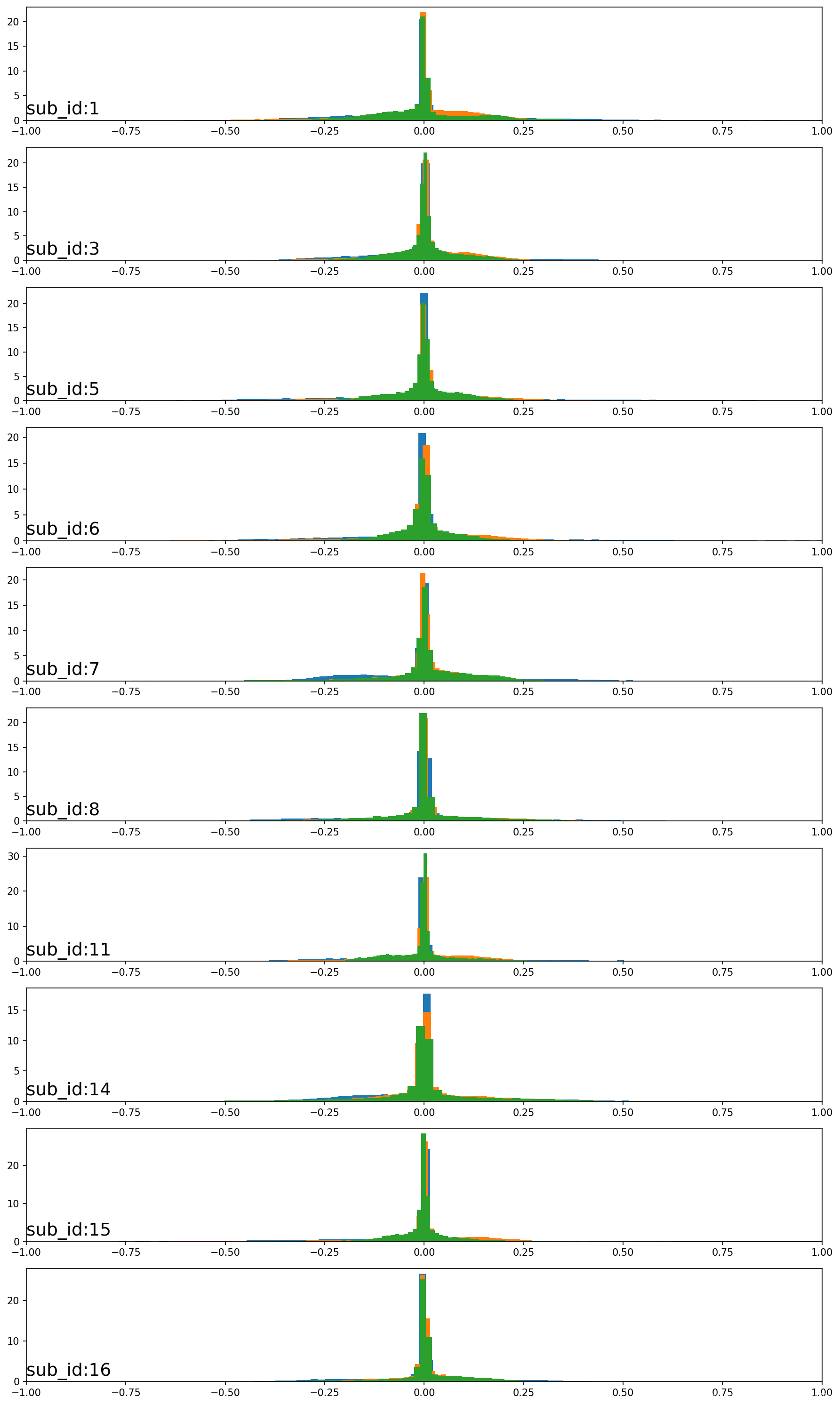
运行该示例将创建三个图形,每个图形都有10个带有三个轴直方图的图。给定图上的三个轴均具有不同的颜色,x,y、z轴的传感器数据分别是蓝色,橙色和绿色。
5.1 加速度直方图
第一张图显示了前10位志愿者的人体加速度直方图。可以看到所有数据在整个轴上聚集在0附近。这表明数据可能居中(均值为零)。志愿者之间的这种强一致性可能有助于建模,并且可能表明志愿者在总加速度数据中的差异可能没有那么大的帮助。
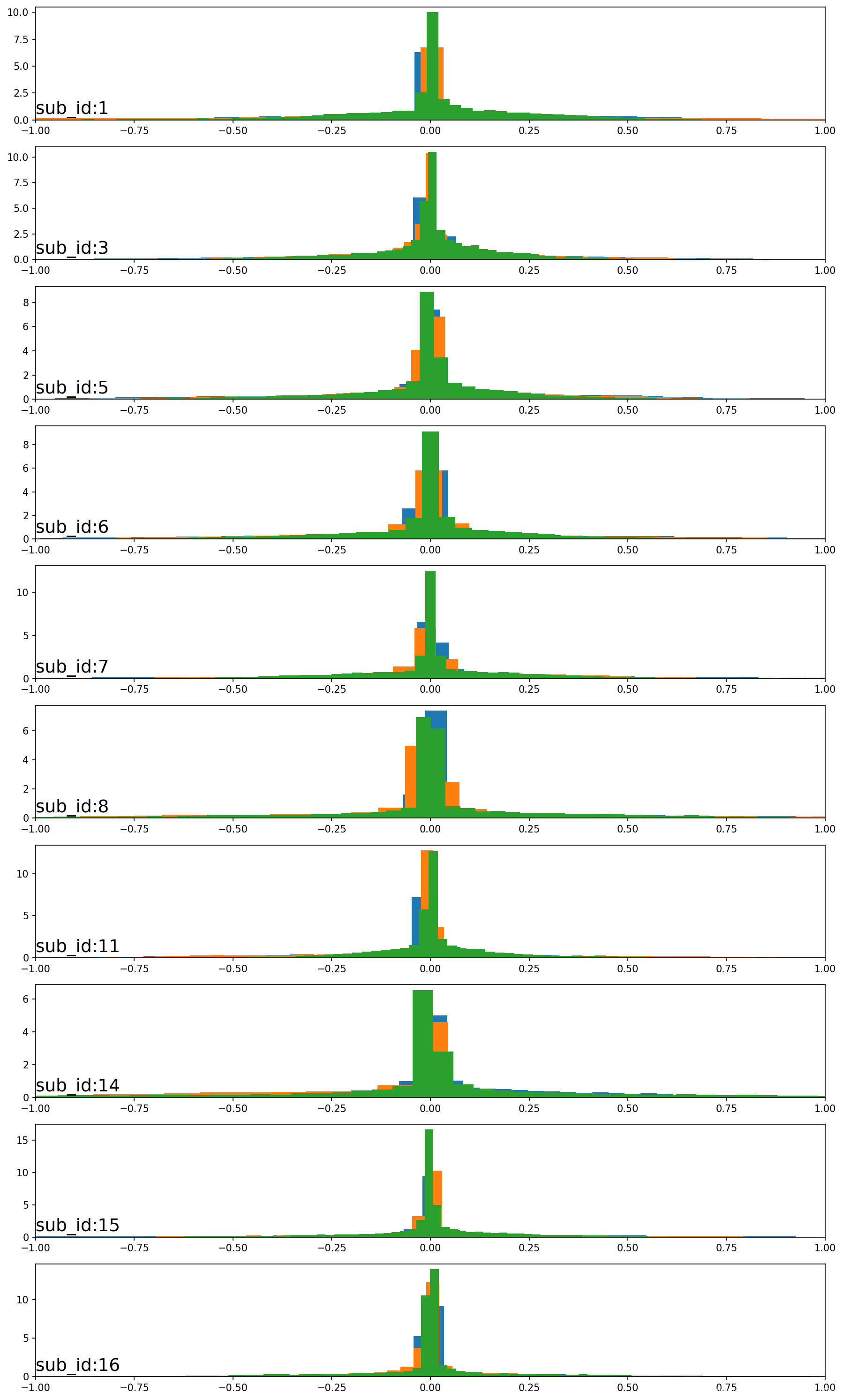
5.2 角速度分布直方图
第二张图显示了前10位志愿者的的陀螺仪数据(三轴角速度)的分布直方图。可以看出以0为中心,并且高斯分布(正态分布)的可能性很高。分布向两侧逐渐变宽,并显示出较宽的尾巴,这对于跨对象的运动数据建模是合适的数据分布情况。
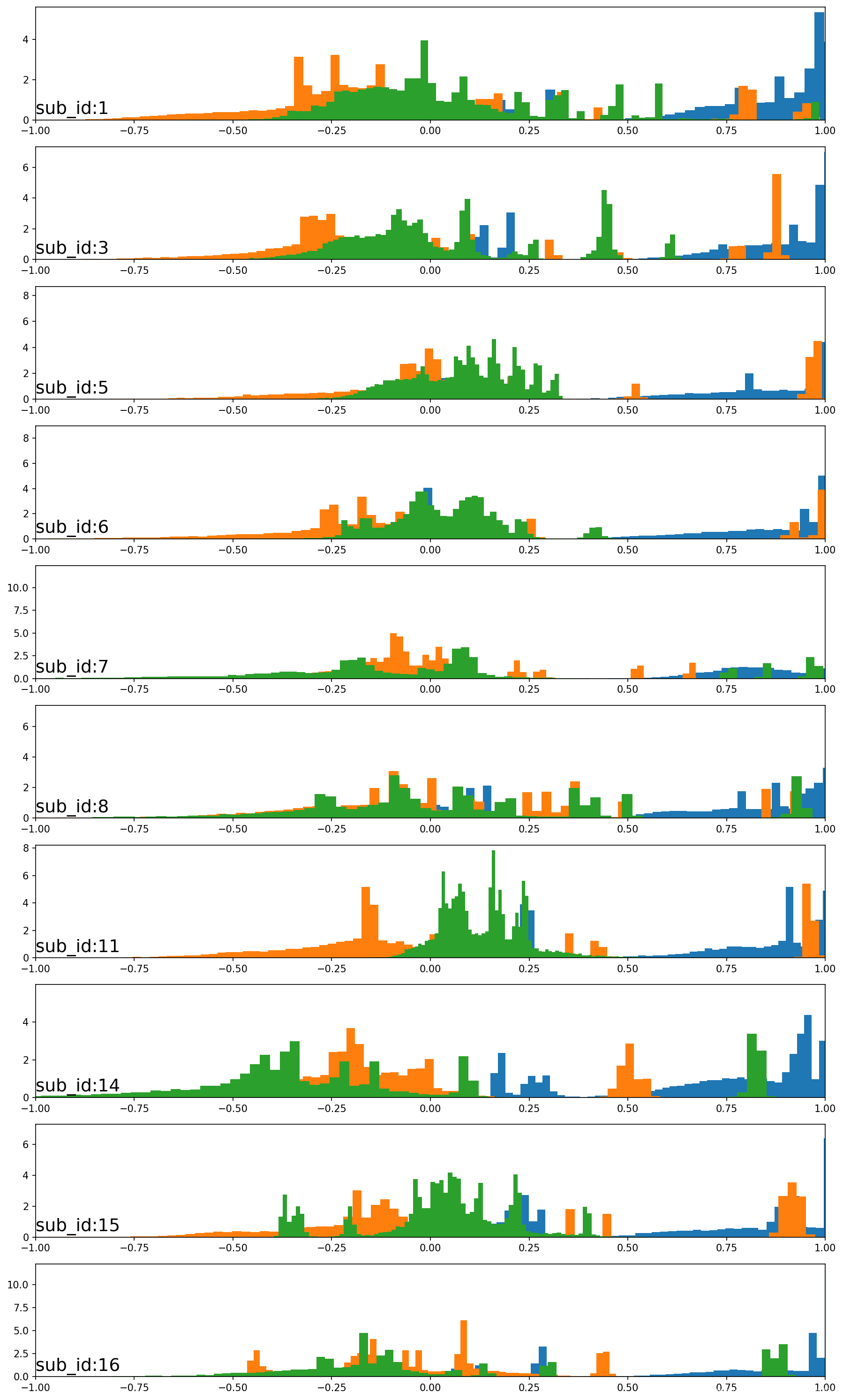
5.3 总的重力加速度直方图
最后一张图显示了前10位志愿者的总加速度。可以看到给定轴的分布确实出现了具有大量单独数据组的高斯分布。有一些分布是对齐的(例如,中间的主要组位于0附近),这表明跨对象的运动数据可能存在某些连续性,至少对于该数据而言是这样的。
6. 每一类(共6类)的分布情况
如果要查看每一类活动的分布情况,一种简单的方式是查看指定志愿者的数据分布情况。希望看到单个志愿者的不同活动的运动数据之间的分布有所不同,可以通过为每个活动创建直方图来查看此情况,并在每个图上使用给定数据类型的三个轴。同样,这些图可以竖直,以按活动比较每个数据轴的分布。首先,将数据按活动类型分组,然后为每个活动创建一个子图,并将数据的每个轴添加到直方图。代码实现:
# 将数据按活动类别分组
def data_by_activity(X, y, activities):
return {a:X[y[:,0]==a, :, :] for a in activities}
绘图:
def plot_activity_histograms(X, y, sensor_type_id):
activity_ids = np.unique(y[:, 0]) # 获取训练集或测试集标签中的类别编号(1-6)
grouped = data_by_activity(X, y, activity_ids)
plt.figure(figsize=(12,20), dpi=150)
activity_list = ['Walking','Walking-upstairs','Walking-downstairs','Sitting','Standing','Laying']
print(activity_ids)
for i, activity in enumerate(activity_list, start=0):
act_id = activity_ids[i]
for j in range(3): # 总的加速度
ax = plt.subplot(len(activity_ids), 1, i+1)
ax.set_xlim(-1,1)
plt.hist(to_series(grouped[act_id][:, :, sensor_type_id + j]), bins=100)
plt.title(activity, y=0, loc='left', size=18)
plt.tight_layout()
plt.show()
plot_activity_histograms(train_subX, train_suby, sensor_type_id=0) # 身体加速度
plot_activity_histograms(train_subX, train_suby, sensor_type_id=3) # 身体角速度
plot_activity_histograms(train_subX, train_suby, sensor_type_id=6) # 重力加速度
运行示例将创建三个图形,其中每个图形都有六个子图,一个对应于训练数据集中第一位志愿者的每个活动的分布情况。总加速度x、y、z轴数据分别是蓝色,橙色和绿色直方图。
第一张图显示了每个活动的身体加速度分布。可以看到,运动中的活动,静止的活动之间的活动分布更为相似。在运动活动中,数据看起来是双峰的;在静止活动中,数据看起来是高斯的或指数的。活动的总加速度与身体加速度分布所看到的模式反映了在上一部分中针对相同的数据类型所看到的结果。总加速度数据也许是区分活动的关键。
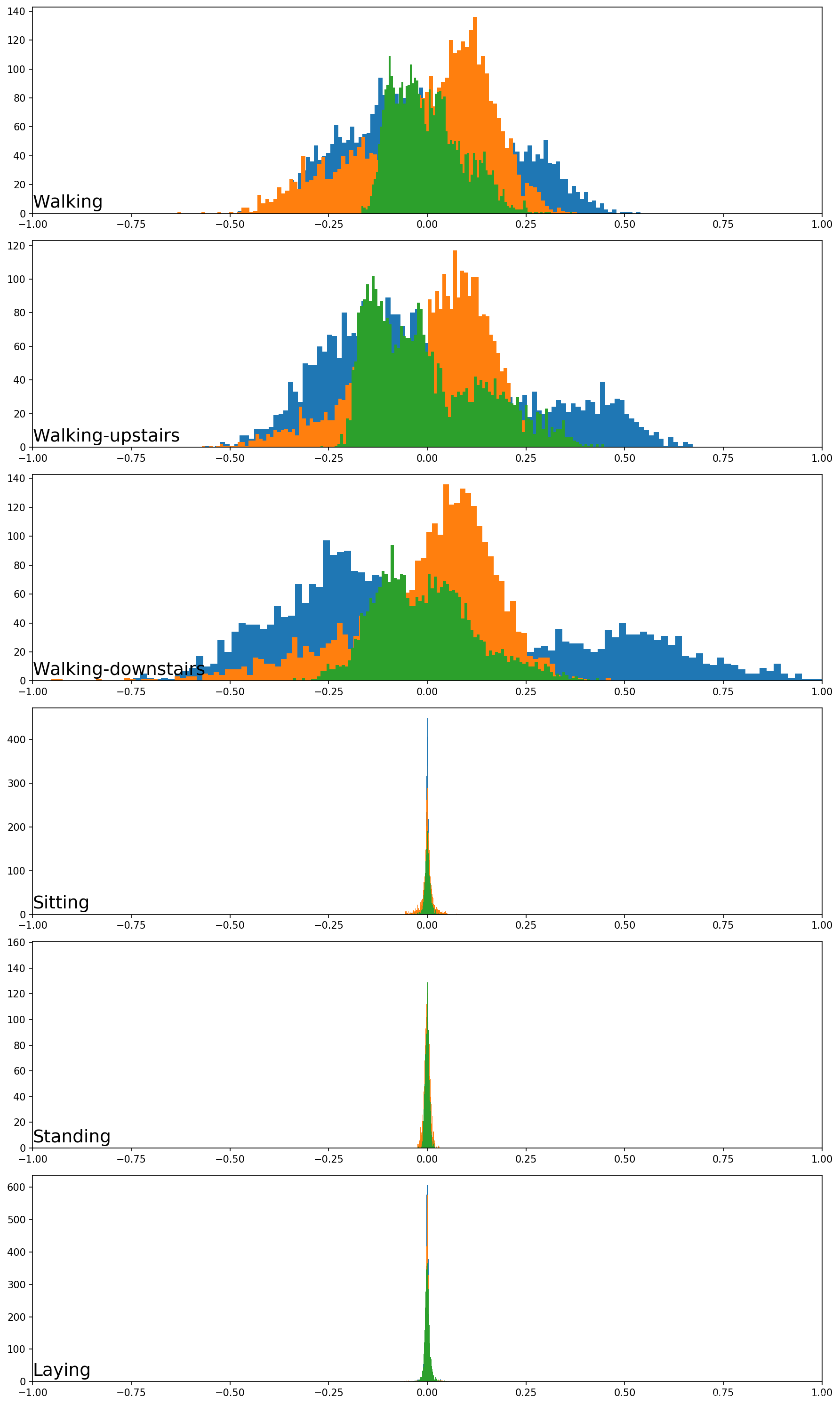
第二张图显示了第7位志愿者的每项活动的陀螺仪数据。可以看到与人体加速度数据具有相似模式的图,尽管对于运动中的活动,可能显示出类似高尾的分布,而不是双峰分布。
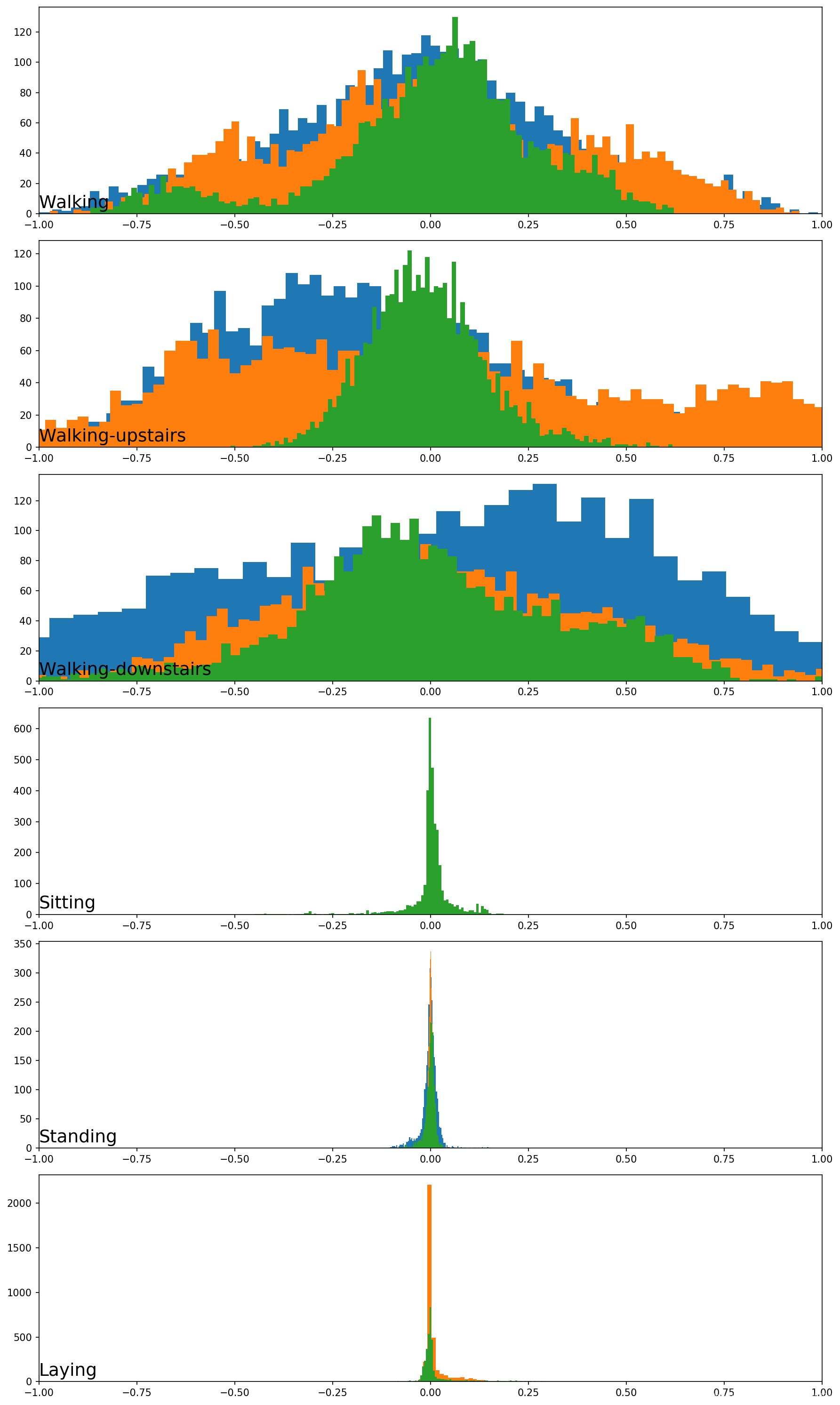
最后一张图中,可以看到每个活动具有不同的数据分布,运动的活动(前三个活动)与静止活动(后三个活动)之间存在明显差异。前三个活动的数据分布看起来是高斯分布,其均值和标准差可能有所不同;后一种活动的分布看起来是多峰的。
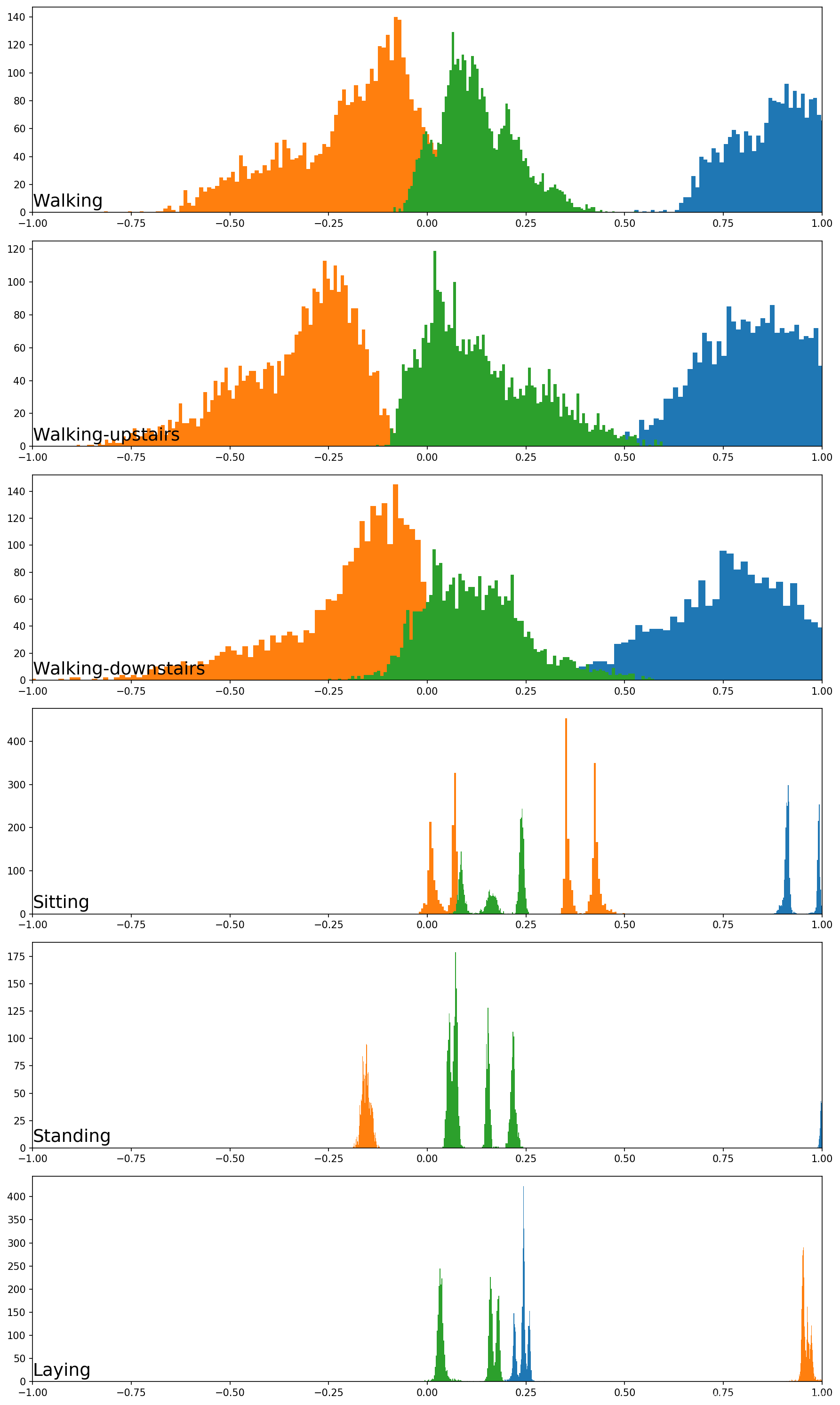
7. 活动持续时间的分布
最后要考虑的领域是受试者在每项活动上花费的时间,这与分类的平衡紧密相关。如果活动(类)总体上在数据集中是平衡的,那么我们期望给定志愿者在不同活动上也是平衡的。 可以通过计算每个受试者在每个活动上花费多长时间(以样本或行为单位)并查看每个活动的持续时间分布来确认这一点。查看此数据的一种简便方法是将分布汇总为箱型图,以中位数(线),中间50%(方框),数据的一般范围(四分位数范围(晶须))和异常值(点)。代码实现:
import random
def random_color(nums):
'''
该函数实现生成指定数量的随机颜色列表
'''
colorArr = ['1','2','3','4','5','6','7','8','9','A','B','C','D','E','F']
color = ''
color_list = []
for i in range(nums):
for i in range(6):
color += colorArr[random.randint(0,14)]
color_list.append('#'+color)
color = ''
return color_list
def get_act_dura_by_sub(X, y, sub_map):
'''
该函数实现找到训练集或者测试集中各类活动的数量
'''
subject_ids = np.unique(sub_map[:,0])
activity_ids = np.unique(y[:,0])
activity_windows = {a:list() for a in activity_ids} # 为每个活动建一个列表
plt.figure(figsize=(12,8), dpi=150)
for sub_id in subject_ids:
_, subj_y = data_for_subject(X, y, sub_map, sub_id)
for a in activity_ids:
activity_windows[a].append(len(subj_y[subj_y[:,0]==a]))
durations = [activity_windows[a] for a in activity_ids] # 将持续时间整理到列表列表中
return durations
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['Microsoft JhengHei']
plt.rcParams['axes.unicode_minus'] = False
def plot_box_act(train_sub_fp, test_sub_fp, labels,
show_colors=True, show_hori_lines=True):
'''
该函数实现绘制训练集和测试集数据的箱型图
'''
sub_map_train = load_file(train_sub_fp)
train_dura = get_act_dura_by_sub(trainX, trainy, sub_map_train)
sub_map_test = load_file(test_sub_fp)
test_dura = get_act_dura_by_sub(testX, testy, sub_map_test)
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(12, 6), dpi=150)
# vert=True:水平; patch_artist=True:填充颜色;showmeans=True:显示均值;notch=True:以凹口形式绘制箱形图;sym= :异常点的形状;
bplot1 = ax1.boxplot(train_dura, vert=True, patch_artist=True, showmeans=True, notch=True, sym='o', labels=labels)
ax1.set_title('训练集数据箱型图', size=18)
bplot2 = ax2.boxplot(test_dura, vert=True, patch_artist=True, showmeans=True, labels=labels)
ax2.set_title('测试集数据箱型图', size=18)
# 填充颜色
if show_colors == True:
colors = random_color(len(labels))
for bplot in (bplot1, bplot2):
for patch, color in zip(bplot['boxes'], colors):
patch.set_facecolor(color)
# 增加水平线
if show_hori_lines == True:
for ax in [ax1, ax2]:
ax.yaxis.grid(True)
ax.set_xlabel('$Activitys$', size=16)
ax.set_ylabel('$Observed values$', size=16)
plt.tight_layout()
plt.show()
调用函数绘图:
train_sub_fp = 'D:/GraduationCode/01 Datasets/UCI HAR Dataset/train/subject_train.txt'
test_sub_fp = 'D:/GraduationCode/01 Datasets/UCI HAR Dataset/test/subject_test.txt'
labels = ['Walking','W-upstairs','W-downstairs','Sitting','Standing','Laying']
plot_box_act(train_sub_fp, test_sub_fp, labels, show_colors=True, show_hori_lines=True)
运行示例将创建六个箱形图,每个活动类别一个。每个箱形图总结了训练数据集中的每个活动花费了多长时间(以行或窗口数为单位)。可以看到,志愿者在固定活动(4、5和6)上花费的时间更多,而在运动活动(1、2和3)上花费的时间少,其中活动3花费时间最少。这些活动之间的差异不大,表明不需要删减时间较长的活动或运动中活动的过度采样。但是,如果活动分类模型表现较差,则需要考虑重采样的方法。
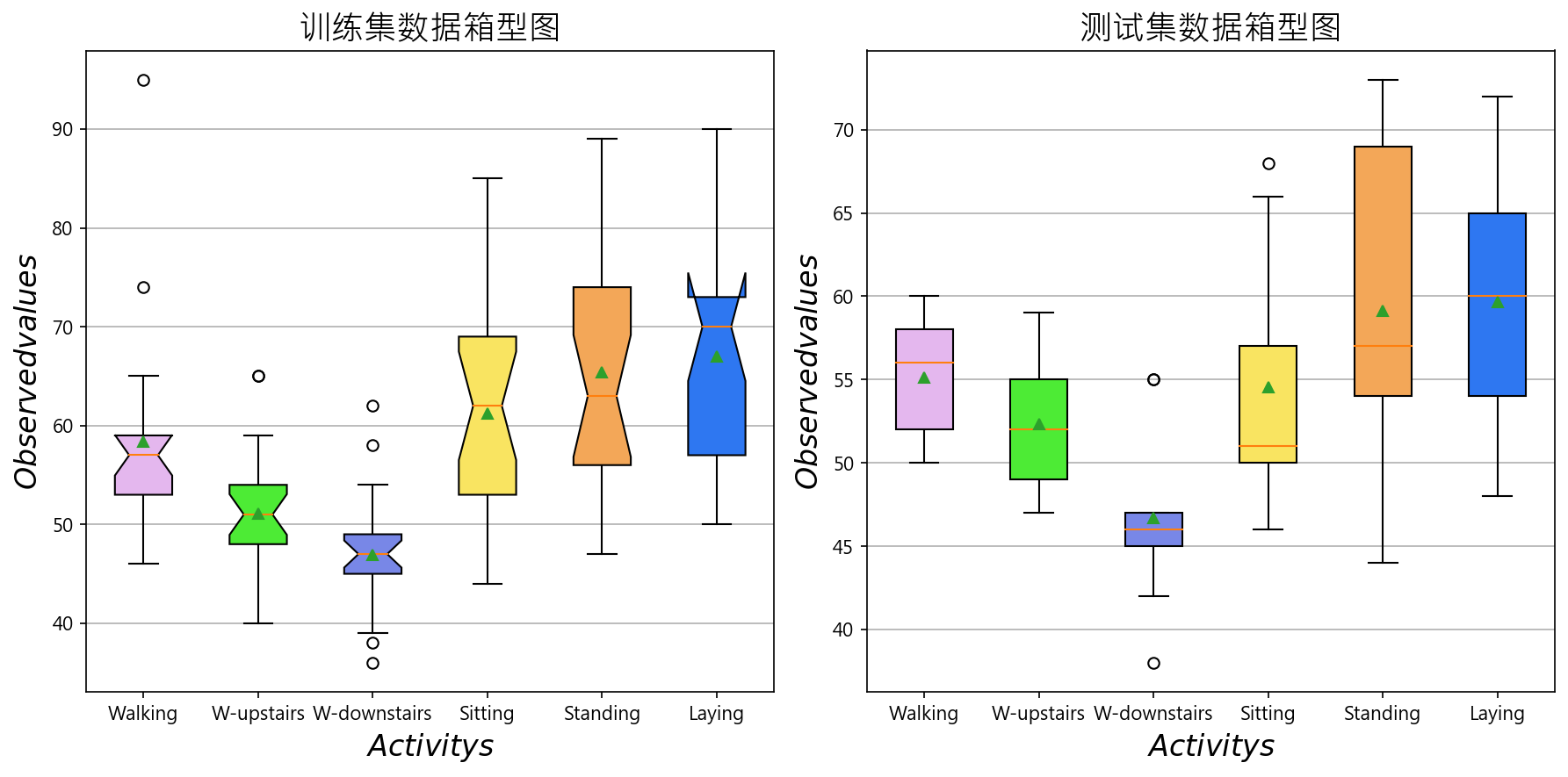
8. 建模分析
8.1 问题框架
第一个重要的考虑因素是预测问题的框架。原始工作的问题框架是根据已知受试者的运动数据和活动类别进行训练,然后再根据给定的运动数据来预测其他志愿者的活动类别。可以总结为:
- 根据运动数据的时间步预测活动类别。
- 根据多个运动数据窗口预测活动类别。
- 预测给定多个运动数据窗口的活动序列。
- 根据预先分段活动的长序列数据预测活动。
- 根据运动数据的时间步预测活动停止或过渡。
- 在给定运动数据窗口的情况下,预测平稳(活动4,5,6)或非平稳活动(活动1,2,3)。
以上思路难易程度不同,针对的任务也不同,提供了探索和理解数据集的多种方法,可以根据自己的业务需求选择合适的问题框架。
8.2 数据准备
在使用原始数据训练模型之前,需要进行一些数据准备。UCI-HAR数据集已经将数据缩放到[-1,1]的取件了。当我们使用自己的数据集的时候,可以尝试以下数据转换:
- 对每一个志愿者(被采集对象)的数据进行归一化(Normalization);
- 对总体数据进行归一化(Normalization);
- 对每一个志愿者(被采集对象)的数据进行标准化(Standardization);
- 对总体数据进行标准化(Standardization);
- 选取不同轴作为特征(有些轴的数据对整体结果影响不大,可以剔除某些轴);
- 数据类型特征选择(int、float32、float64);
- 采样异常点检测与去除;
- 移除过多活动的窗口;
- 对代表性不足的活动窗口进行过采样;
- 将信号数据下采样至 1 4 、 1 2 、 1 、 2 \frac14、\frac12、1、2 41、21、1、2 或其他比例。
8.3 预测建模
人类活动识别是一个时间序列多分类问题。它也可以被构造为二元分类问题和多步时间序列分类问题。论文在数据集上使用经典的机器学习算法(一种改进的支持向量机)进行多分类,从每个数据窗口设计特征。
支持向量机在数据集的特征工程版本上的结果可以提供问题性能的 baseline(基线)。从这一点出发,在这个版本的数据集上对多个线性、非线性和机器学习算法的评估可以提供一个改进的基准。问题的焦点可能是是否使用未经处理的数据集。这里,可以探索模型复杂性以确定最适合该问题的模型;可供探索的一些模型包括:
- 常见的线性、非线性和集成机器学习算法;
- MLP;
- 1D CNN;
- LSTM;
- CNN-LSTM、ConvLSTM;
- DeepConvLSTM;
- LSTM-FCN
9. 模型评估
UCI-HAR 数据集的论文中,将训练集和测试集按照7:3的比例划分。上文我们这种数据分割方法的探索表明,这两组数据都合理地代表了整个数据集。可以尝试对每个志愿的数据采用留一法交叉验证或者k折交叉验证的方法。
使用分类精度和混淆矩阵来评估模型性能,这两种方法都适用于多分类预测问题。具体地说,混淆矩阵有助于确定某些类是否比其他类更容易预测或更具挑战性,例如对于静止活动还是涉及运动的活动。
10. 扩展
之后的文章会介绍经典的机器学习算法、CNN、CNN-LSTM、ConvLSTM、DeepConvLSTM、LSTM-FCN实现时间序列分类任务。
参考:
https://machinelearningmastery.com/how-to-model-human-activity-from-smartphone-data/
python os.walk():https://www.runoob.com/python/os-walk.html
python os.path():https://www.runoob.com/python/python-os-path.html
numpy stack()/vstack()/hstack()/dstack()函数详解:https://blog.csdn.net/weixin_39653948/article/details/104829112
pandas groupby() :https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.groupby.html?highlight=groupby#pandas.DataFrame.groupby
numpy unique:https://numpy.org/devdocs/reference/generated/numpy.unique.html?highlight=unique#numpy.unique
numpy dstack:https://numpy.org/devdocs/reference/generated/numpy.dstack.html
Axis hist:https://matplotlib.org/api/_as_gen/matplotlib.axes.Axes.hist.html?highlight=hist#matplotlib.axes.Axes.hist
Axis boxplot:https://matplotlib.org/api/_as_gen/matplotlib.axes.Axes.boxplot.html?highlight=boxplot#matplotlib.axes.Axes.boxplot
随机生成颜色:https://blog.csdn.net/u014662865/article/details/82016609



















 348
348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











