









论文名称:TabNet: Attentive Interpretable Tabular Learning
论文下载:https://arxiv.org/abs/1908.07442
论文作者:Google Cloud AI
论文年份:AAAI 2021
论文被引:162(2022/04/06)
Abstract
We propose a novel high-performance and interpretable canonical deep tabular data learning architecture, TabNet. TabNet uses sequential attention to choose which features to reason from at each decision step, enabling interpretability and more efficient learning as the learning capacity is used for the most salient features. We demonstrate that TabNet outperforms other variants on a wide range of non-performance-saturated tabular datasets and yields interpretable feature attributions plus insights into its global behavior. Finally, we demonstrate self-supervised learning for tabular data, significantly improving performance when unlabeled data is abundant.
我们提出了一种新颖的高性能和可解释的规范深度表格数据学习架构 TabNet。 TabNet 使用顺序注意力来选择在每个决策步骤中从哪些特征进行推理,从而实现可解释性和更有效的学习,因为学习能力用于最显着的特征。我们证明 TabNet 在各种非性能饱和的表格数据集上优于其他变体,并产生可解释的特征属性以及对其全局行为的洞察。最后,我们展示了表格数据的自监督学习,当未标记数据丰富时显着提高了性能。
Introduction
深度神经网络 (DNN) 在图像 (He et al. 2015)、文本 (Lai et al. 2015) 和音频 (Amodei et al. 2015) 方面取得了显著成功。对于这些,有效地将原始数据编码为有意义的表示的规范架构(Canonical Architectures)推动了快速进展。一种尚未在规范架构中取得如此成功的数据类型是表格数据(tabular data)。
尽管它是现实世界 AI 中最常见的数据类型(因为它由类别型和数字型特征组成)(Chui et al. 2018),但表格数据的深度学习仍然没有得到充分探索,其中包含集成决策树的变体( DTs)仍然主导着大多数应用程序(Kaggle 2019a)。为什么?首先,因为基于 DT 的方法具有某以下优势:
- i)对于具有近似超平面边界的决策流形(decision manifolds)具有代表性,这在表格数据中很常见;
- ii)基本形式具有高度可解释性(例如通过跟踪决策节点),并且它们的集成形式有流行的事后可解释性方法,例如(Lundberg、Erion and Lee 2018)——这是许多实际应用中的一个重要问题;
- iii)训练速度很快。
其次,因为之前提出的 DNN 架构不太适合表格数据:例如堆叠卷积层或多层感知器 (MLP) 被严重过度参数化——缺乏适当的归纳偏置通常会导致它们无法找到表格决策流形的最佳解决方案(Goodfellow, Bengio, and Courville 2016; Shavitt and Segal 2018; Xu et al. 2019)。
为什么深度学习值得探索表格数据?一个明显的动机是预期的性能改进,特别是对于大型数据集(Hestness et al. 2017)。此外,与树学习不同,DNN 能够对表格数据进行基于梯度下降的端到端学习,这有很多好处:
- i)有效地编码多种数据类型,例如图像和表格数据;
- ii) 减轻对特征工程的需求,这是目前基于树的表格数据学习方法的一个关键方面;
- iii) 从流数据中学习,也许最重要的是 (iv) 端到端模型允许表示学习,这支持许多有价值的应用场景,包括数据高效的域适应(Goodfellow, Bengio and Courville 2016)、生成建模(Radford, Metz Chintala 2015)和半监督学习(Dai et al. 2017)。
我们为表格数据提出了一种新的规范 DNN 架构 TabNet。主要贡献总结如下:
- TabNet 无需任何预处理即可输入原始表格数据,并使用基于梯度下降的优化进行训练,从而能够灵活地集成到端到端学习中。
- TabNet 使用顺序注意力来选择在每个决策步骤中从哪些特征进行推理,从而实现可解释性和更好的学习,因为学习能力用于最显著的特征(见图 1)。这种特征选择是实例化的,例如每个输入都可能不同,并且与 (Chen et al. 2018) 或 (Yoon, Jordon, and van der Schaar 2019) 等其他基于实例的(instance-wise)特征选择方法不同,TabNet 采用单一的深度学习架构进行特征选择和推理(reasoning)。
- 上述设计选择带来了两个有价值的属性: (i) TabNet 在用于不同领域分类和回归问题的各种数据集上优于或与其他表格学习模型相当;(ii) TabNet 实现了两种可解释性:可视化特征重要性及其组合方式的局部可解释性,以及量化每个特征对训练模型的贡献的全局可解释性。
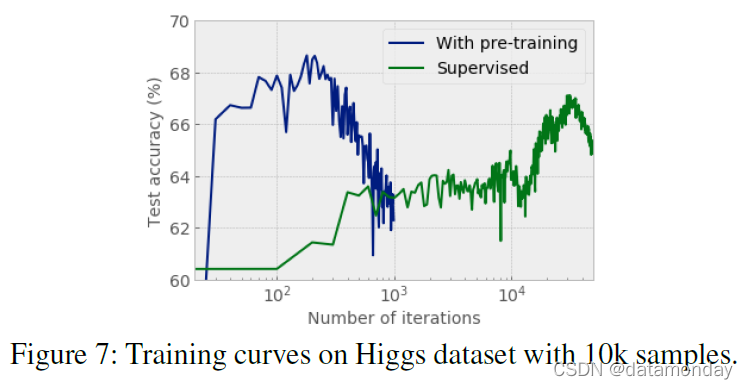
- 最后,对于表格数据,我们首次展示了通过使用无监督预训练来预测掩码特征的显着性能改进(见图 2)。
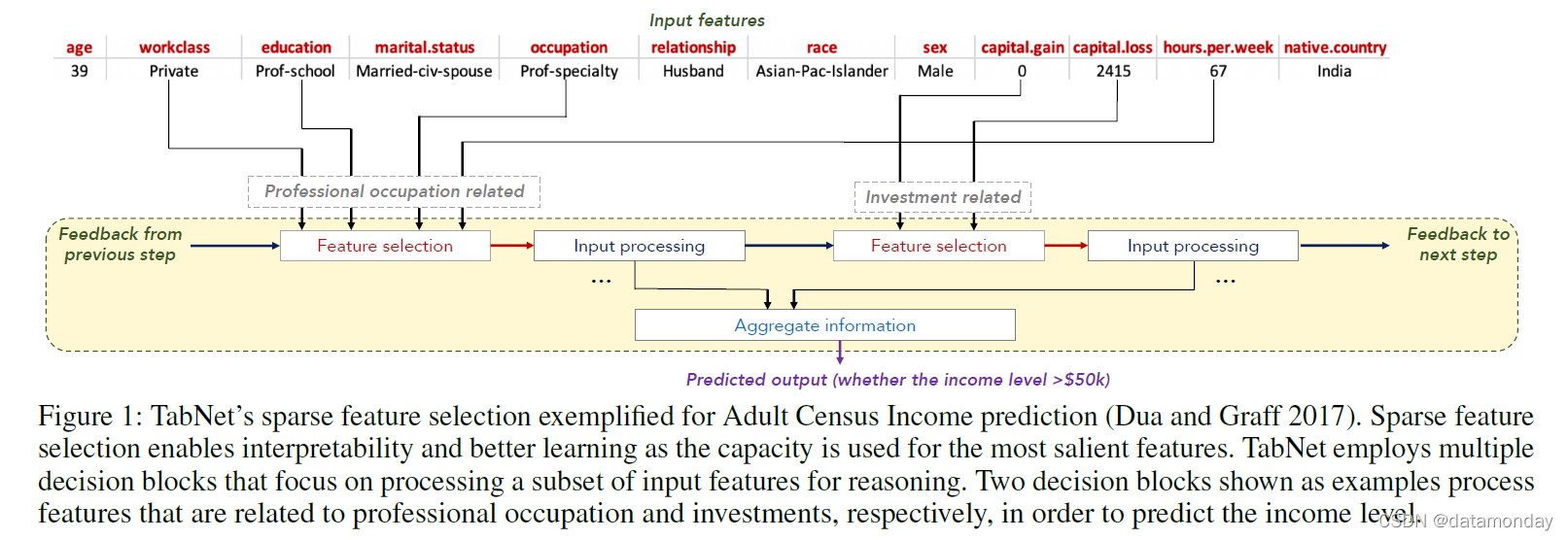
图 1:用于成人人口普查收入预测(Dua 和 Graff 2017)的 TabNet 的稀疏特征选择示例。稀疏特征选择可实现可解释性和更好的学习,因为容量用于最显着的特征。 TabNet 采用多个决策块,专注于处理输入特征的子集以进行推理。作为示例显示的两个决策块分别处理与专业职业和投资相关的特征,以预测收入水平。
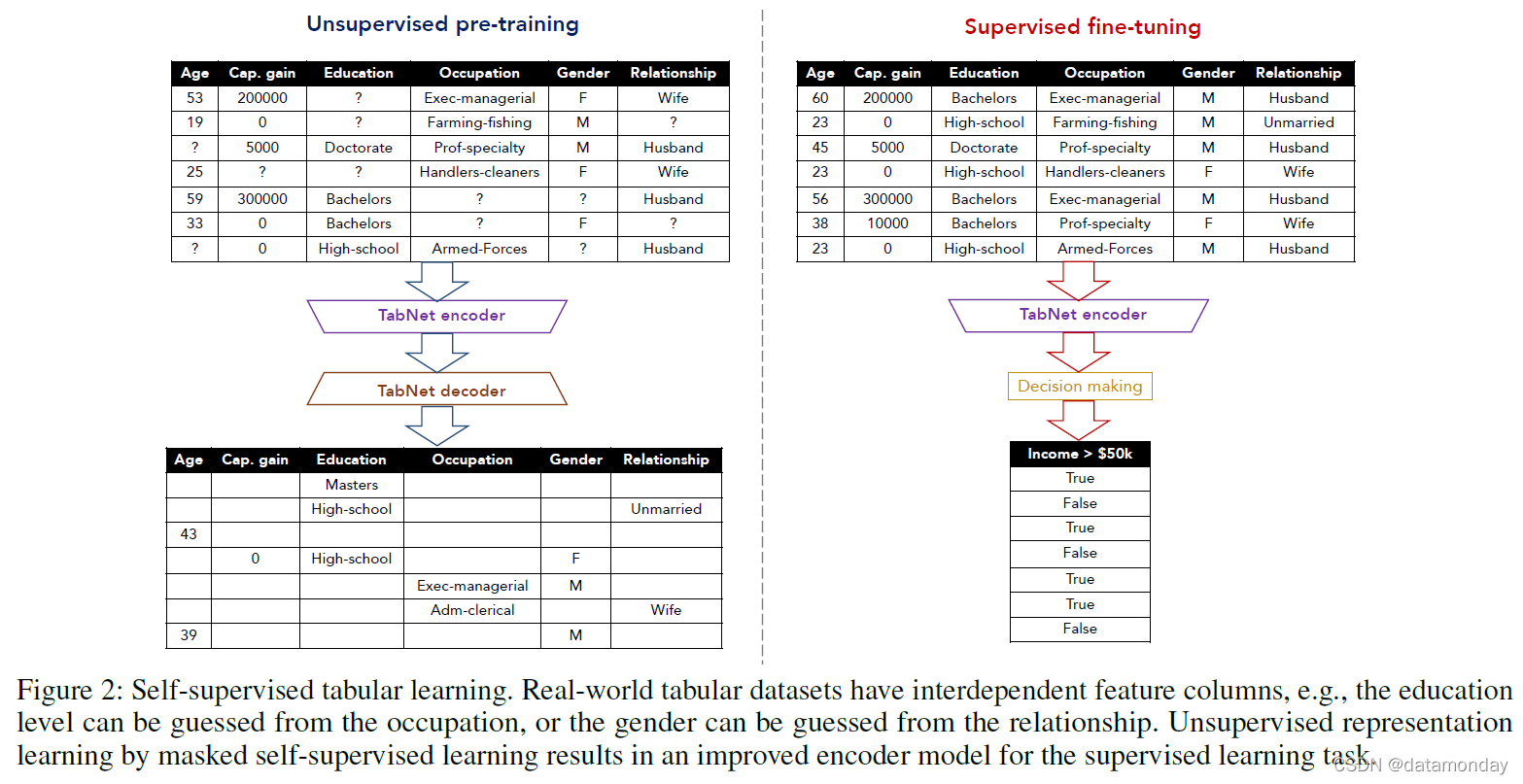
图 2:自监督表格学习。现实世界的表格数据集具有相互依赖的特征列,例如,可以从职业中猜测教育水平,或者可以从关系中猜测性别。通过掩蔽自监督学习进行的无监督表示学习产生了用于监督学习任务的改进编码器模型。
Related Work
特征选择(Feature selection):特征选择广义上是指根据其对预测的有用性明智地选择特征子集。常用的技术,如前向选择和 Lasso 正则化(Guyon and Elisseeff 2003)基于整个训练数据属性特征重要性,被称为全局方法。实例特征选择是指为每个输入单独选择特征,在 (Chen et al. 2018) 中使用解释器模型进行研究,以最大化所选特征和响应变量之间的互信息,(Yoon, Jordon, and van der Schaar 2019)通过使用演员-评论家框架来模仿基线,同时优化选择。与这些不同的是,TabNet 在端到端学习中采用了具有可控稀疏性的软特征选择(soft feature selection with controllable sparsity in end-to-end learning)——单个模型共同执行特征选择和输出映射,从而以紧凑的表示(compact representation)获得卓越的性能。
基于树的学习(Tree-based learning):DT 常用于表格数据学习。它们的突出优势是有效挑选具有最多统计信息增益的全局特征(Grabczewski 和 Jankowski 2005)。为了提高标准 DT 的性能,一种常见的方法是集成(ensemble)以减少方差。在集成方法中,随机森林(Ho 1998)使用具有随机选择特征的随机数据子集来生长许多树。 XGBoost (Chen and Guestrin 2016) 和 LightGBM (Ke et al. 2017) 是最近在大多数数据科学竞赛中占据主导地位的两种集成 DT 方法。我们对各种数据集的实验结果表明,当通过深度学习提高表示能力同时保留其特征选择属性时,基于树的模型可以表现出色。
将 DNN 集成到 DT(Integration of DNNs into DTs):用 DNN 构建块表示 DT,如((Humbird, Peterson, and McClarren 2018)中的表示会产生表示冗余和低效学习。软(神经)DT((Wang, Aggarwal, and Liu 2017; Kontschieder et al. 2015)使用可微决策函数,而不是不可微的轴对齐切分。然而,没有自动特征选择通常会降低性能。(Yang, Morillo, and Hospedales 2018) 提出了一种软分箱函数(soft binning function)来模拟 DNN 中的 DT,方法是低效地枚举所有可能的决策。 (Ke et al. 2019) 通过明确利用表达性特征组合提出了一种 DNN 架构,但是,学习是基于从梯度提升的 DT 中转移知识。 (Tanno et al. 2018) 提出了一种 DNN 架构,通过从原始块自适应地增长,同时表示学习到边缘、路由函数(routing function)和叶节点。 TabNet 与这些不同,因为它通过顺序注意嵌入了具有可控稀疏性的软特征选择。
自监督学习(Self-supervised learning):无监督表示学习改进了监督学习,尤其是在小数据情况下(Raina et al. 2007)。最近在文本(Devlin et al. 2018)和图像(Trinh, Luong, and Le 2019)数据方面的工作已经显示出显著的进步——这得益于对无监督学习目标(掩蔽输入预测)和基于注意力的深度学习的明智选择。
TabNet for Tabular Learning
DT 可以成功地从现实世界的表格数据集中学习。通过特定设计,可以使用传统的 DNN 构建块来实现类似 DT 的输出流形,见图 3。在这样的设计中,单个特征选择是获得超平面形式决策边界的关键,它可以推广到特征的线性组合,其中系数决定每个特征的比例。 TabNet 基于这样的特征,它优于 DT,同时通过精心设计获得优势:(i)使用从数据中学习的稀疏实例特征选择; (ii) 构建一个连续的多步骤架构,其中每个步骤都有助于基于所选特征的决策的一部分; (iii) 通过对所选特征进行非线性处理来提高学习能力; (iv) 通过更高维度和更多步骤模拟集成学习。
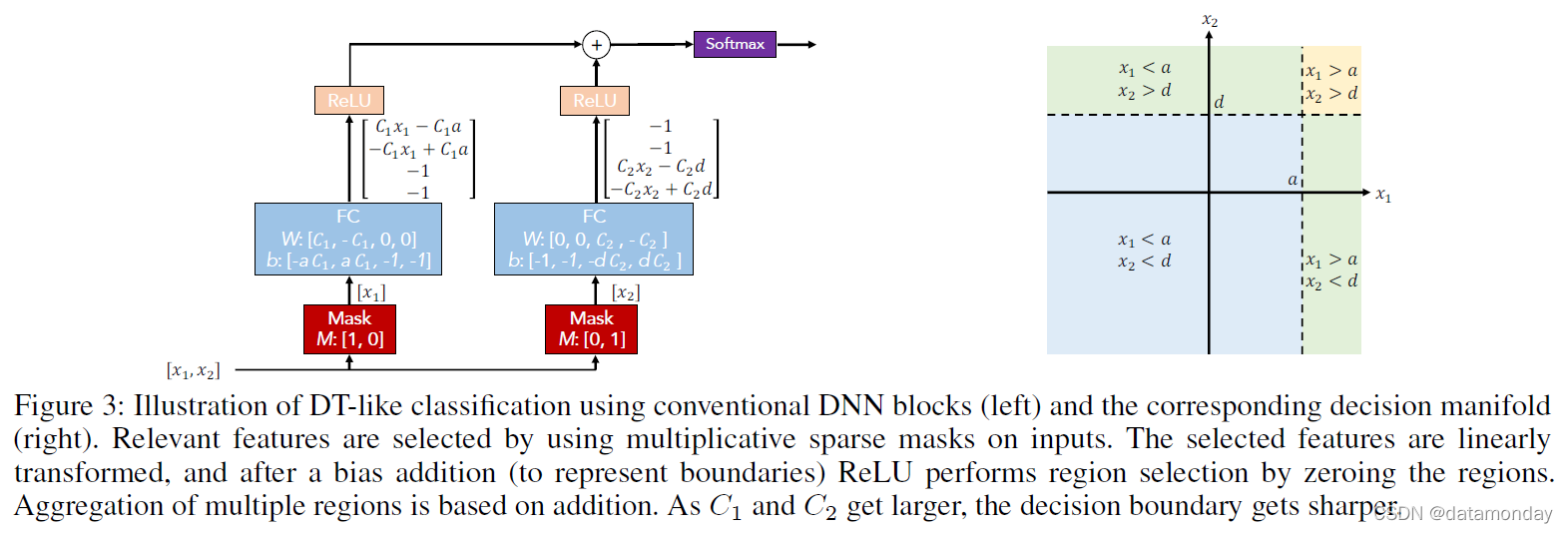
图 3:使用传统 DNN 块(左)和相应的决策流形(右)的类 DT 分类图示。通过在输入上使用乘法稀疏掩码来选择相关特征。选择的特征被线性变换,并且在添加偏差(表示边界)之后,ReLU 通过将区域归零来执行区域选择。多个区域的聚合基于加法。随着 C1 和 C2 变大,决策边界变得越来越清晰。
图 4 显示了用于编码表格数据的 TabNet 架构。我们使用原始数值特征并考虑使用可训练嵌入映射分类特征。我们不考虑任何全局特征归一化,而只是应用批量归一化(BN)。我们将相同的 D 维特征 f ∈ <B×D 传递给每个决策步骤,其中 B 是批量大小。 TabNet 的编码基于具有 Nsteps 决策步骤的顺序多步处理。第 i 步从第 (i-1) 步输入处理后的信息,以决定使用哪些特征,并输出处理后的特征表示以汇总到整体决策中。顺序形式的自上而下注意力的想法受到其在处理视觉和文本数据 (Hudson and Manning 2018) 和强化学习 (Mott et al. 2019) 中的应用的启发,同时在高维中搜索一小部分相关信息输入。
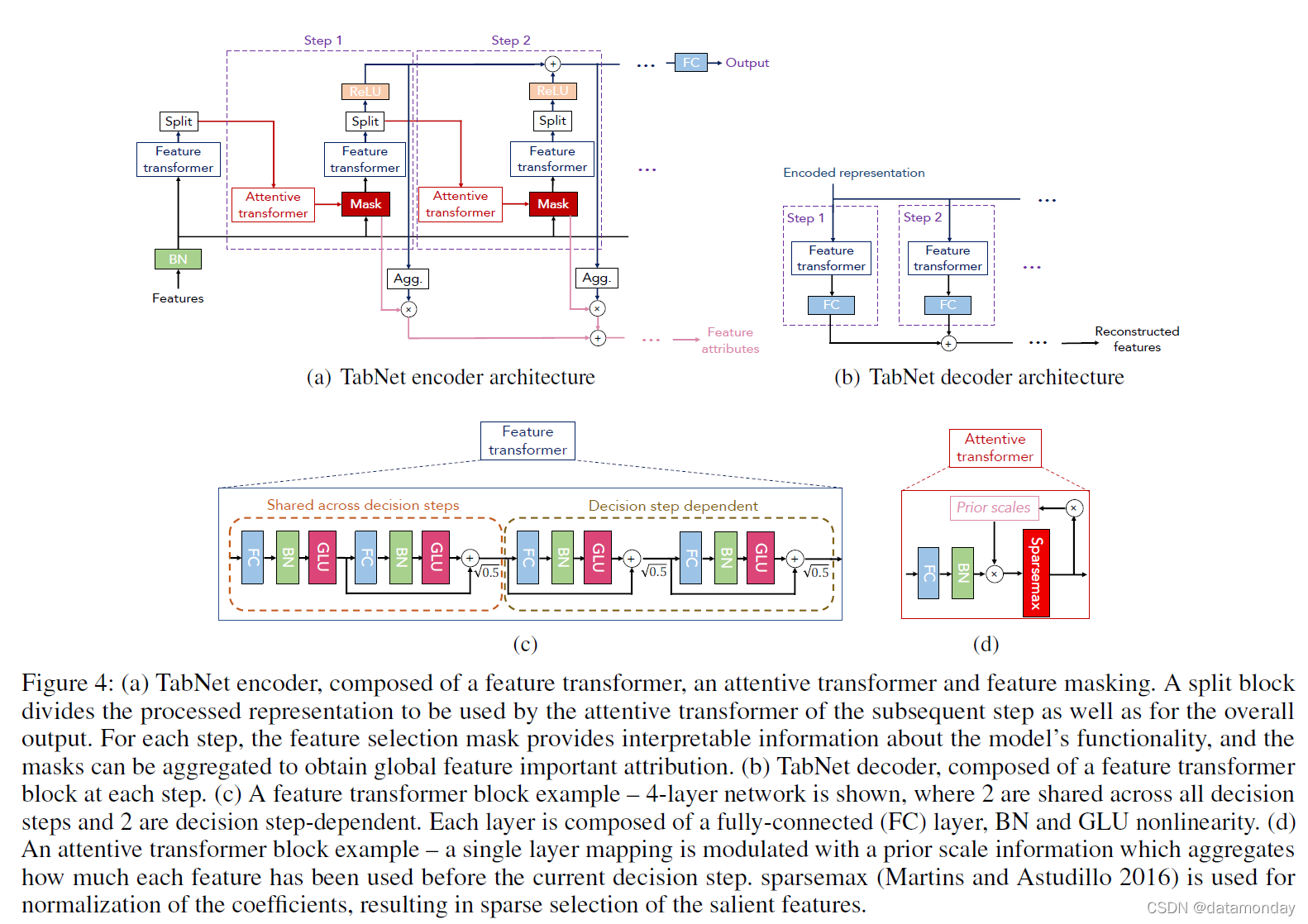
图 4:(a) TabNet 编码器,由特征转换器、注意力转换器和特征掩码组成。拆分块将处理后的表示划分为后续步骤的注意力转换器以及整体输出使用的表示。对于每个步骤,特征选择掩码提供有关模型功能的可解释信息,并且可以聚合掩码以获得全局特征重要属性。 (b) TabNet 解码器,由每一步的特征变换器块组成。 © 一个特征转换器块示例——显示了 4 层网络,其中 2 个在所有决策步骤之间共享,2 个与决策步骤相关。每一层都由一个全连接(FC)层、BN 和 GLU 非线性组成。 (d) 一个注意力transformer块示例——单层映射使用先验比例信息进行调制,该信息汇总了在当前决策步骤之前每个特征使用了多少。 sparsemax (Martins and Astudillo 2016) 用于系数的归一化,实现显著特征的稀疏选择。
特征选择(Feature selection):我们使用可学习的掩码 M [ i ] ∈ R B × D M[i] ∈ R^{B×D} M[i]∈RB×D 来软选择显着特征。通过对最显着特征的稀疏选择,决策步骤的学习能力不会浪费在不相关的特征上,因此模型变得更加参数有效。掩码是乘法的,M[i] · f。我们使用注意力transformer(图 4)来使用上一步中处理过的特征 a[i - 1] 获得掩码: M [ i ] = s p a r s e m a x ( P [ i − 1 ] ⋅ h i ( a [ i − 1 ] ) ) M[i] = sparsemax(P[i - 1] · h_i(a[i − 1])) M[i]=sparsemax(P[i−1]⋅hi(a[i−1]))。 Sparsemax 归一化((Martins and Astudillo 2016)通过将欧几里德投影映射到概率单纯形(simplex)上来鼓励稀疏性,观察到其性能非常好,并且与稀疏特征选择的可解释性目标一致。请注意, ∑ j = 1 D M [ i ] b , j = 1 ∑^D_{j=1} M[i]_{b,j} = 1 ∑j=1DM[i]b,j=1。hi 是一个可训练的函数,如图 4 所示,使用 FC 层,然后是 BN。 P[i] 是先验比例项,表示以前使用了多少特定特征:
P [ i ] = ∏ j = 1 i ( γ − M [ j ] ) P[i] = \prod ^i _{j=1}(γ - M[j]) P[i]=∏j=1i(γ−M[j]),其中 γ 是一个松弛参数——当 γ = 1 时,强制一个特征仅在一个决策步骤中使用,并且随着 γ 的增加,更大的灵活性是提供在多个决策步骤中使用特征。P[0] 被初始化为全 1, 1 B × D 1^{B×D} 1B×D,在掩码特征上没有任何先验。如果某些特征未被使用(如在自监督学习中),则将相应的 P[0] 项设为 0 以帮助模型的学习。为了进一步控制所选特征的稀疏性,我们提出熵形式的稀疏正则化 (Grandvalet and Bengio 2004):
L s p a r s e = ∑ i = 1 N s t e p s ∑ b = 1 B ∑ j = 1 D − M b , j [ i ] l o g ( M b , j [ i ] + ϵ ) N s t e p s ⋅ B L_{sparse} =\sum ^{N_{steps}} _{i=1} \sum ^B _{b=1} \sum ^D _{j=1} \frac{−M_{b,j}[i] log(M_{b,j}[i] + \epsilon)}{ N_{steps}·B} Lsparse=∑i=1Nsteps∑b=1B∑j=1DNsteps⋅B−Mb,j[i]log(Mb,j[i]+ϵ) ,
其中 ϵ \epsilon ϵ 是一个数值稳定性的小数。我们将稀疏正则化添加到整体损失中,系数为 λsparse。稀疏性为大多数特征都是冗余的数据集提供了有利的归纳偏置。
特征处理(Feature processing):我们使用特征变换器(feature transformer)处理过滤后的特征(图 4),然后分割决策步骤输出和后续步骤的信息, [ d [ i ] , a [ i ] ] = f i ( M [ i ] ⋅ f ) [d[i], a[i]] = f_i(M[i ] · f) [d[i],a[i]]=fi(M[i]⋅f),其中 d [ i ] ∈ R B × N d d[i] ∈ R^{B×N_d} d[i]∈RB×Nd 和 a [ i ] ∈ R B × N a a[i] ∈ R^{B×N_a} a[i]∈RB×Na。对于具有高容量的参数高效和鲁棒的学习,feature transformer 应该包括在所有决策步骤之间共享的层(因为相同的特征在不同的决策步骤中输入),以及与决策步骤相关的层。图 4 将实现显示为两个共享层和两个决策步骤相关层的连接。每个 FC 层之后是 BN 和门控线性单元 (GLU) 非线性 (Dauphin et al. 2016),最终通过归一化连接到归一化残差连接。√0.5 的标准化有助于通过确保整个网络的方差不会发生显着变化来稳定学习(Gehring et al. 2017)。为了更快的训练,我们在 BN 中使用大批量。因此,除了应用于输入特征的那个,我们使用 ghost BN (Hoffer, Hubara, and Soudry 2017) 形式,使用虚拟批量大小 BV 和动量 mB。对于输入特征,我们观察到低方差平均的好处,因此避免了 ghost BN。最后,受到图 3 中类似决策树的聚合的启发,我们将整体决策嵌入构造为 d o u t = ∑ i = 1 N s t e p s R e L U ( d [ i ] ) d_{out} = \sum ^{N_{steps}} _{i=1} ReLU(d[i]) dout=∑i=1NstepsReLU(d[i])。我们应用线性映射 W f i n a l d o u t W_{final}d_{out} Wfinaldout 来获得输出映射。
可解释性(Interpretability):TabNet 的特征选择掩码可以揭示每个步骤中选择的特征。如果 M b , j [ i ] = 0 M_{b,j[i]} = 0 Mb,j[i]=0,那么第 b 个样本的第 j 个特征应该对决策没有贡献。如果 fi 是一个线性函数,则系数 M b , j [ i ] M_{b,j[i]} Mb,j[i] 将对应于 f b , j f_{b,j} fb,j 的特征重要性。尽管每个决策步骤都采用非线性处理,但它们的输出稍后会以线性方式组合。除了分析每个步骤之外,我们的目标是量化聚合特征的重要性。组合不同步骤的掩码需要一个系数,该系数可以衡量决策中每个步骤的相对重要性。我们简单地提出 η b [ i ] = ∑ c = 1 N d R e L U ( d b , c [ i ] ) ηb[i] =\sum ^{N_d} _{c=1} ReLU(d_{b,c}[i]) ηb[i]=∑c=1NdReLU(db,c[i]) 来表示第 b 个样本在第 i 个决策步骤的总决策贡献。直观地说,如果 d b , c [ i ] < 0 d_{b,c} [i] < 0 db,c[i]<0,则第 i 个决策步骤的所有特征对整体决策的贡献应该为 0。随着其值的增加,它在整体线性组合中的作用越来越大。在每个决策步骤用 η b [ i ] η_b [i] ηb[i] 缩放决策掩码,我们提出了聚合特征重要性掩码:
M a g g − b , j = ∑ i = 1 N s t e p s η b [ i ] M b , j [ i ] / ∑ j = 1 D ∑ i = 1 N s t e p s η b [ i ] M b , j [ i ] M_{agg−b,j} = \sum ^{N_{steps}} _{i=1} ηb[i]M_{b,j}[i] / \sum ^D _{j=1} \sum ^{N_{steps}} _{i=1} ηb[i]M_{b,j}[i] Magg−b,j=∑i=1Nstepsηb[i]Mb,j[i]/∑j=1D∑i=1Nstepsηb[i]Mb,j[i]
归一化用于确保 ∑ j = 1 D M a g g − b , j = 1 \sum ^D _{j=1} M_{agg−b,j} = 1 ∑j=1DMagg−b,j=1。
表格自监督学习(Tabular self-supervised learning):我们提出了一种解码器架构,用于从 TabNet 编码表示中重建表格特征。解码器由 特征变换器(feature transformer) 组成,然后是每个决策步骤的 FC 层。将输出相加以获得重建的特征。我们提出了从其他特征列中预测缺失特征列的任务。考虑一个二进制掩码
S
∈
{
0
,
1
}
B
×
D
S ∈ \{0, 1\}^{B×D}
S∈{0,1}B×D。 TabNet 编码器输入
(
1
−
S
)
⋅
f
^
(1 - S) · \hat{f}
(1−S)⋅f^,解码器输出重构特征
S
⋅
f
^
S · \hat{f}
S⋅f^。我们在编码器中初始化
P
[
0
]
=
(
1
−
S
)
P[0] = (1 - S)
P[0]=(1−S),以便模型仅强调已知特征,解码器的最后一个 FC 层与
S
S
S 相乘以输出未知特征。我们考虑自监督阶段的重建损失:

使用真实标签的总体标准差进行归一化是有益的,因为特征可能具有不同的范围。在每次迭代中,我们从参数为 p s p_s ps 的伯努利分布中独立地对 S b , j S_{b,j} Sb,j 进行采样。
Experiments
我们在广泛的问题中研究 TabNet,其中包含回归或分类任务,尤其是已发布的基准。对于所有数据集,分类输入被映射到具有可学习嵌入的单维可训练标量(在某些情况下,更高维度的嵌入可能会稍微提高性能,但对单个维度的解释可能会变得具有挑战性),数字列在没有预处理的情况下输入。我们使用标准分类(softmax 交叉熵)和回归(均方误差)损失函数,我们训练直到收敛(专门设计的特征工程,例如变量高度偏态分布的对数变换可能会进一步改善结果,但我们将其排除在本文的范围之外)。 TabNet 模型的超参数在验证集上进行了优化,并在附录中列出。 TabNet 性能对大多数超参数不是很敏感,如附录中的消融研究所示。在附录中,我们还介绍了关于关键超参数选择的各种设计和消融研究。对于我们引用的所有实验,我们使用与原始工作相同的训练、验证和测试数据。 Adam 优化算法(Kingma 和 Ba 2014)和 Glorot 统一初始化用于所有模型的训练。
Instance-wise feature selection
选择显著特征对于高性能至关重要,尤其是对于小型数据集。我们考虑来自 (Chen et al. 2018) 的 6 个表格数据集(由 10k 个训练样本组成)。数据集的构建方式使得只有特征的一个子集决定了输出。
对于 Syn1-Syn3,所有实例的显著特征都是相同的(例如,Syn2 的输出取决于特征 X3-X6),并且全局特征选择,就好像显着特征已知一样,将提供高性能。对于 Syn4-Syn6,显着特征取决于实例(例如,对于 Syn4,输出取决于 X1-X2 或 X3-X6,具体取决于 X11 的值),这使得全局特征选择不是最佳的。表 1 显示 TabNet 优于其他网络(Tree Ensembles(Geurts、Ernst 和 Wehenkel 2006)、LASSO 正则化、L2X(Chen 等人 2018))并且与 INVASE(Yoon、Jordon 和 van der Schaar 2019)不相上下)。对于 Syn1-Syn3,TabNet 的性能接近于全局特征选择——它可以找出哪些特征是全局重要的。对于 Syn4-Syn6,消除了实例冗余特征,TabNet 改进了全局特征选择。所有其他方法都使用具有 43k 参数的预测模型,由于 actorcritic 框架中的其他两个模型,INVASE 的参数总数为 101k。 TabNet 是单一架构,Syn1-Syn3 的大小为 26k,Syn4-Syn6 的大小为 31k。紧凑表示是 TabNet 的宝贵属性之一。
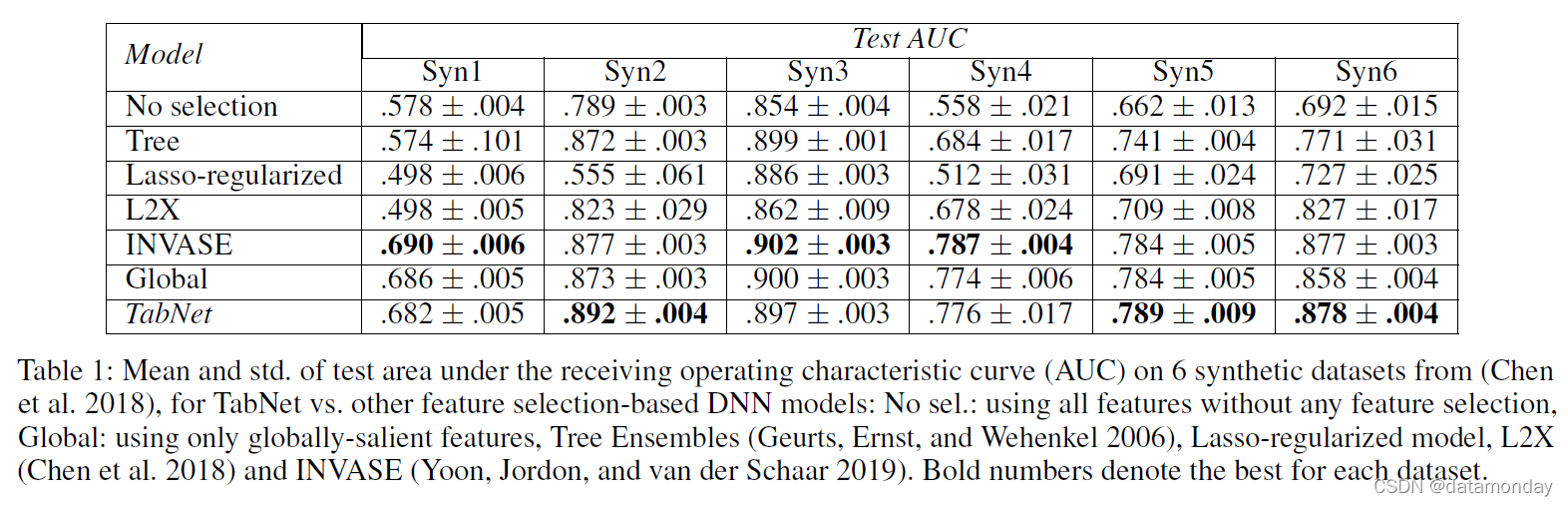
表 1:平均值和标准差。来自 (Chen et al. 2018) 的 6 个合成数据集的接收操作特征曲线 (AUC) 下的测试区域,用于 TabNet 与其他基于特征选择的 DNN 模型:无选择:使用所有特征而无需任何特征选择,全局:仅使用全局显着特征、Tree Ensembles(Geurts、Ernst 和 Wehenkel 2006)、Lasso 正则化模型、L2X(Chen 等人 2018)和 INVASE(Yoon、Jordon 和 van der Schaar 2019)。粗体数字表示每个数据集的最佳值。
Performance on real-world datasets
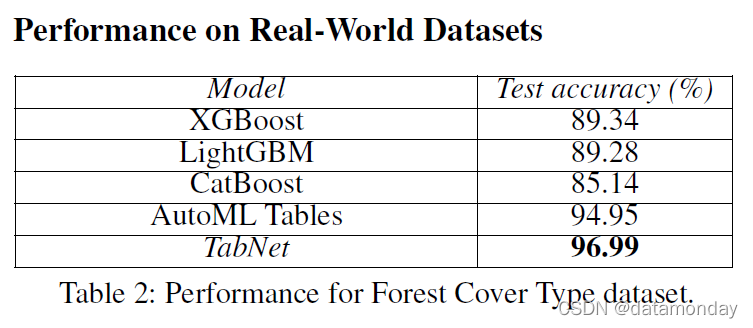
Forest Cover Type(Dua 和 Graff 2017):任务是根据制图变量对森林覆盖类型进行分类。表 2 显示 TabNet 优于基于集成树的方法,这些方法已知可以实现可靠的性能(Mitchell 等人,2018 年)。我们还考虑了 AutoML Tables (AutoML 2019),这是一种基于模型集成的自动搜索框架,包括 DNN、梯度增强 DT、AdaNet (Cortes et al. 2016) 和集成 (AutoML 2019),具有非常彻底的超参数搜索。没有细粒度超参数搜索的单个 TabNet 优于它。
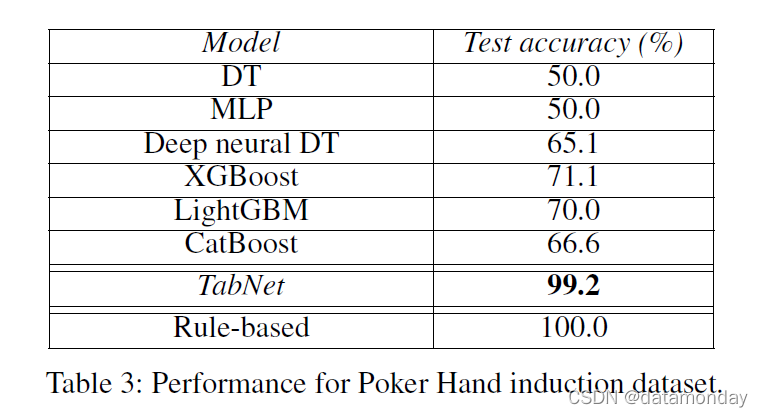
Poker Hand (Dua and Graff 2017):任务是根据牌的原始花色和等级属性对扑克手进行分类。输入输出关系是确定性的,手工制定的规则可以达到 100% 的准确度。 Yet,传统的 DNN、DT,甚至它们的深度神经 DT 的混合变体(Yang、Morillo 和 Hospedales 2018)严重受到数据不平衡的影响,无法学习所需的排序和排序操作(Yang、Morillo 和 Hospedales 2018)。Tuned XGBoost、CatBoost 和 LightGBM 比它们略有改进。 TabNet 优于其他方法,因为它可以通过其深度执行高度非线性处理,而不会由于实例特征选择而过拟合。
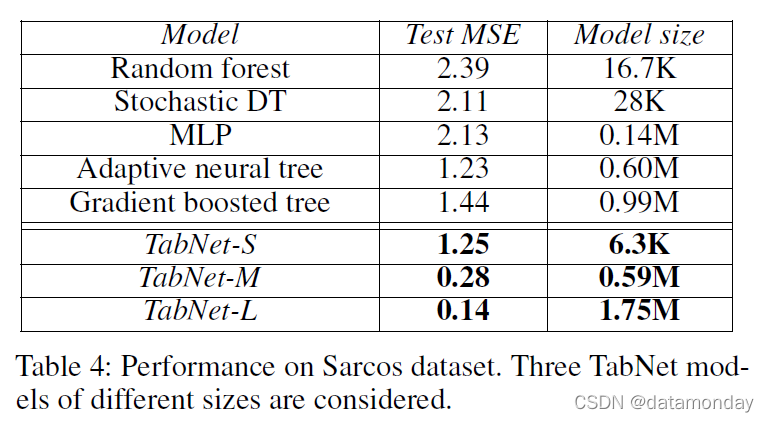
Sarcos (Vijayakumar and Schaal 2000):任务是回归拟人机器人手臂的逆动力学。 (Tanno et al. 2018) 表明,随机森林可以在非常小的模型中获得不错的性能。在非常小的模型尺寸范围内,TabNet 的性能与 (Tanno et al. 2018) 的最佳模型相当,参数多 100 倍。当模型大小不受限制时,TabNet 实现了几乎一个数量级的测试 MSE。
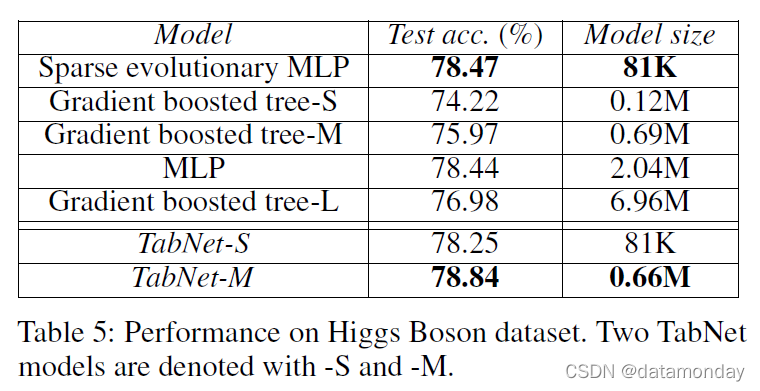
Higgs Boson(Dua and Graff 2017):任务是区分希格斯玻色子过程与背景。由于其更大的规模(10.5M 样本),即使在非常大的集成中,DNN 的性能也优于 DT 变体。 TabNet 以更紧凑的表示优于 MLP。我们还与将非结构化稀疏性集成到训练中的最先进的进化稀疏算法(Mocanu et al. 2018)进行了比较。凭借其紧凑的表示,TabNet 在相同数量的参数下产生与稀疏进化训练几乎相似的性能。与稀疏进化训练不同,TabNet 的稀疏性是结构化的——它不会降低操作强度(Wen et al. 2016)并且可以有效地利用现代多核处理器。
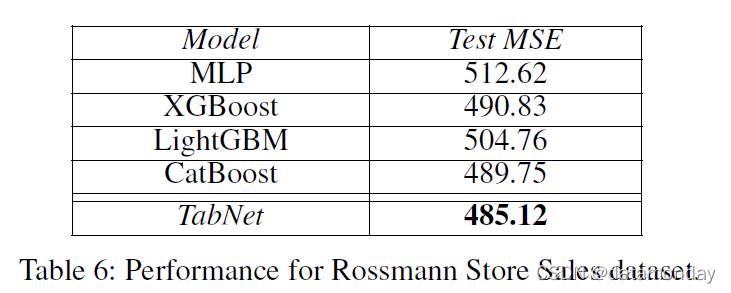
Rossmann Store Sales (Kaggle 2019b):任务是根据静态和时变特征预测商店销售额。我们观察到 TabNet 优于常用方法。时间特征(例如天)具有很高的重要性,并且对于销售动态不同的假期等情况,可以观察到实例特征选择的好处。
Interpretability
合成数据集(Synthetic datasets):图 5 显示了表 1 中合成数据集的聚合特征重要性掩码。Syn2 上的输出仅取决于 X3-X6,我们观察到对于不相关的特征,聚合掩码几乎全为零,而 TabNet 仅关注相关的。对于 Syn4,输出取决于 X1-X2 或 X3-X6,具体取决于 X11 的值。 TabNet 产生准确的实例特征选择——它分配一个掩码以专注于指标 X11,并将几乎全零的权重分配给不相关的特征(两个特征组以外的特征)。

真实世界数据集(Real-world datasets):我们首先考虑蘑菇可食性预测的简单任务(Dua and Graff 2017)。TabNet 在这个数据集上达到了 100% 的测试准确率。众所周知(Dua and Graff 2017)“气味(Odor)”是最具辨别力的特征——仅使用“气味”,模型可以获得 > 98.5% 的测试准确率(Dua 和 Graff 2017)。因此,期望它具有很高的特征重要性。TabNet 为其分配了 43% 的重要性得分比,而其他方法如 LIME(Sundararajan, Taly, and Yan 2017)、Integrated Gradients(Sundararajan, Taly, and Y an 2017)和 DeepLift(Lundberg, Erion, and Lee 2018; Nbviewer 2019)分配少于 30%(Ibrahim et al. 2019)。接下来,我们考虑成人人口普查收入。TabNet 产生的特征重要性排名与众所周知的一致(Ribeiro, Singh, and Guestrin 2016)(见附录)对于相同的问题,图 6 显示了年龄组之间的明显分离,正如“年龄”是最TabNet 的重要特征。

Self-supervised learning
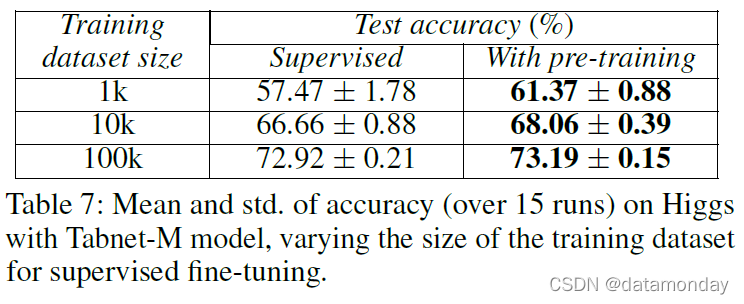
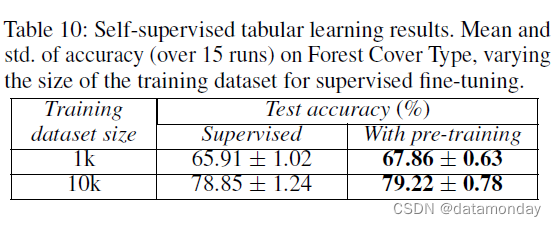
表 7 显示无监督预训练显着提高了监督分类任务的性能,尤其是在未标记数据集远大于标记数据集的情况下。如图 7 所示,无监督预训练的模型收敛速度要快得多。非常快的收敛对于持续学习和领域适应很有用。
Conclusions
我们提出了 TabNet,一种用于表格学习的新型深度学习架构。 TabNet 使用顺序注意机制在每个决策步骤中选择具有语义意义的特征子集进行处理。实例特征选择可实现高效学习,因为模型容量已充分用于最显着的特征,并且还通过选择掩码的可视化产生更具可解释性的决策。我们证明 TabNet 在来自不同领域的表格数据集上优于以前的工作。最后,我们展示了无监督预训练在快速适应和提高性能方面的显着优势。
Performance on KDD datasets
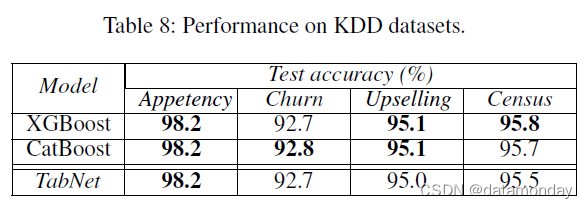
Appetency、Churn 和 Upsales 数据集是用于客户关系管理的分类任务,而 KDD Census Income(Dua and Graff 2017)数据集用于从人口统计和就业相关变量进行收入预测。这些数据集在性能上表现出饱和行为(即使是简单的模型也会产生类似的结果)。表 8 显示 TabNet 实现了与 XGBoost 和 CatBoost 非常相似或稍差的性能,因为它们包含大量的集成,因此众所周知它们是鲁棒的。
Comparison of feature importance ranking of TabNet
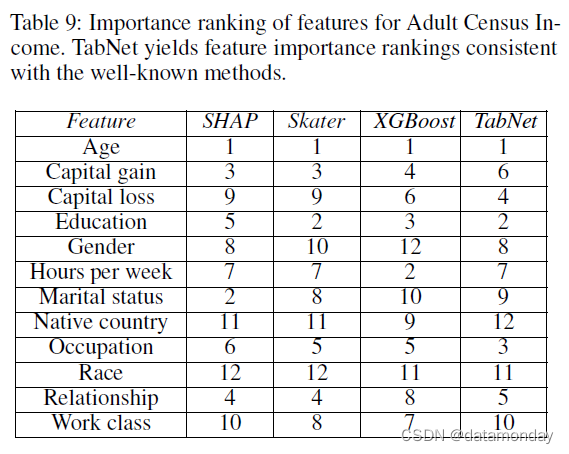
我们观察到最重要的特征(“Age”, “Capital gain/loss”, “Education number”, “Relationship”)和最不重要的特征(“Native country”, “Race”, “Gender”, “Work class”)。
Self-supervised learning on Forest Cover Type Experiment hyperparameters
对于所有数据集,我们使用预定义的超参数搜索空间。 Nd和Na选自{8, 16, 24, 32, 64, 128},Nsteps选自{3, 4, 5, 6, 7, 8, 9, 10},γ选自{1.0, 1.2 , 1.5, 2.0},λsparse 选自 {0, 0.000001, 0.0001, 0.001, 0.01, 0.1},B 选自 {256, 512, 1024, 2048, 4096, 8192, 16384, 32768},BV 选自{256, 512, 1024, 2048, 4096},学习率选自{0.005, 0.01.0.02, 0.025},衰减率选自{0.4, 0.8, 0.9, 0.95},衰减迭代次数选自{0.5k, 2k, 8k, 10k, 20k},mB 选自 {0.6, 0.7, 0.8, 0.9, 0.95, 0.98}。如果模型大小不在所需的截止值之下,我们会减小该值以满足大小约束。对于所有比较模型,我们使用相同数量的搜索步骤运行超参数调整。
Synthetic:所有 TabNet 模型使用 Nd=Na=16,B=3000,BV =100,mB=0.7。对于 Syn1,我们使用 λsparse=0.02,Nsteps=4 和 γ=2.0;对于 Syn2 和 Syn3,我们使用 λsparse=0.01,Nsteps=4 和 γ=2.0;对于 Syn4、Syn5 和 Syn6,我们使用 λsparse=0.005、Nsteps=5 和 γ=1.5。feature transformer 使用两个共享和两个决策步骤相关的 FC 层、ghost BN 和 GLU 块。所有模型都使用 Adam,学习率为 0.02(每 200 次迭代衰减 0.7,指数衰减)进行 4k 次迭代。对于可视化,我们还使用 10M 样本大小的数据集训练 TabNet 模型。对于这种情况,我们选择 Nd = Na = 32, λsparse=0.001, B=10000, BV =100, mB=0.9。 Adam 以 0.02 的学习率(每 2k 次迭代衰减 0.9,指数衰减)进行 15k 次迭代。对于 Syn2 和 Syn3,Nsteps=4 和 γ=2。对于 Syn4 和 Syn6,Nsteps=5 和 γ=1.5。
Forest Cover Type:数据集分区细节,XGBoost、LigthGBM和CatBoost的超参数来自(Mitchell et al. 2018)。我们重新优化 AutoInt 超参数。 TabNet 模型使用 Nd=Na=64, λsparse=0.0001, B=16384, BV =512, mB=0.7, Nsteps=5 和 γ=1.5。特征变换器使用两个共享和两个决策步骤依赖的 FC 层、ghost BN 和 GLU 块。 Adam 以 0.02 的学习率(每 0.5k 次迭代衰减 0.95,指数衰减)进行 130k 次迭代。对于无监督预训练,解码器模型使用 Nd=Na=64,B=16384,BV=512,mB=0.7,Nsteps=10。对于有监督的微调,我们使用批量大小 B=BV,因为训练数据集很小。
Poker Hands:我们从训练数据集中分割 6k 个样本进行验证,在优化超参数后,我们用整个训练数据集重新训练。 DT、MLP 和深度神经 DT 模型遵循与 (Yang, Morillo, and Hospedales 2018) 相同的超参数。我们调整了 XGBoost、LigthGBM 和 CatBoost 的超参数。 TabNet 使用 Nd=Na=16, λsparse=0.000001, B=4096, BV =1024, mB = 0.95, Nsteps=4 和 γ=1.5。feature transformer使用两个共享和两个决策步骤相关的 FC 层、ghost BN 和 GLU 块。 Adam 以 0.01 的学习率(每 500 次迭代衰减 0.95,指数衰减)进行 50k 次迭代。
Sarcos:我们从训练数据集中分割了 4.5k 个样本进行验证,在优化超参数后,我们用整个训练数据集重新训练。所有比较模型都遵循 (Tanno et al. 2018) 的超参数。 TabNet-S 模型使用 Nd=Na=8, λsparse=0.0001, B=4096, BV =256, mB=0.9, Nsteps=3 和 γ=1.2。每个特征变换器块使用一个共享和两个决策步骤相关的 FC 层、ghost BN 和 GLU 块。 Adam 以 0.01 的学习率(每 8k 次迭代衰减 0.95,指数衰减)进行 600k 次迭代。 TabNet-M 模型使用 Nd=Na=64, λsparse=0.0001, B=4096, BV =128, mB=0.8, Nsteps=7 和 γ=1.5。特征变换器使用两个共享和两个决策步骤依赖的 FC 层、ghost BN 和 GLU 块。 Adam 以 0.01 的学习率(每 8k 次迭代衰减 0.95,指数衰减)进行 600k 次迭代。 TabNet-L 模型使用 Nd=Na=128, λsparse=0.0001, B=4096, BV =128, mB=0.8, Nsteps=5 和 γ=1.5。特征变换器使用两个共享和两个决策步骤依赖的 FC 层、ghost BN 和 GLU 块。 Adam 以 0.02 的学习率(每 8k 次迭代衰减 0.9,指数衰减)进行 600k 次迭代。
Higgs:我们从训练数据集中分割了 500k 个样本进行验证,在优化超参数后,我们用整个训练数据集重新训练。 MLP 模型来自 (Mocanu et al. 2018)。对于梯度提升树(Tensorflow 2019),我们调整学习率和深度——梯度提升树-S、-M 和 -L 模型分别使用 50、300 和 3000 棵树。 TabNet-S 模型使用 Nd=24, Na=26, λsparse=0.000001, B=16384, BV =512, mB=0.6, Nsteps=5 和 γ=1.5。feature transformer使用两个共享和两个决策步骤相关的 FC 层、ghost BN 和 GLU 块。 Adam 以 0.02 的学习率(每 20k 次迭代衰减 0.9,指数衰减)进行 870k 次迭代。 TabNet-M 模型使用 Nd=96, Na=32, λsparse=0.000001, B=8192, BV =256, mB=0.9, Nsteps=8 和 γ=2.0。feature transformer使用两个共享和两个决策步骤相关的 FC 层、ghost BN 和 GLU 块。 Adam 以 0.025 的学习率(每 10k 次迭代衰减 0.9,指数衰减)进行 370k 次迭代。对于无监督预训练,解码器模型使用 Nd=Na=128,B=8192,BV=256,mB=0.9,Nsteps=20。对于有监督的微调,我们使用批量大小 B=BV,因为训练数据集很小。
Rossmann:我们使用与 (Catboost 2019) 相同的预处理和数据拆分——2014 年的数据用于训练和验证,而 2015 年用于测试。我们从训练数据集中分割了 100k 个样本进行验证,在优化超参数后,我们用整个训练数据集重新训练。比较模型的性能来自(Catboost 2019)。通过超参数调整获得,MLP 由 5 层 FC(隐藏单元大小为 128)组成,其次是 BN 和 ReLU 非线性,以 512 的批大小和 0.001 的学习率进行训练。 TabNet 模型使用 Nd=Na=32, λsparse=0.001, B=4096, BV =512, mB=0.8, Nsteps=5 和 γ=1.2。feature transformer使用两个共享和两个决策步骤相关的 FC 层、ghost BN 和 GLU 块。 Adam 以 0.002 的学习率(每 2000 次迭代衰减 0.95,指数衰减)进行 15k 次迭代。
KDD:对于 Appetency、Churn 和 Upsales 数据集,我们应用了与 (Prokhorenkova et al. 2018) 类似的预处理和拆分。比较模型的性能来自 (Prokhorenkova et al. 2018)。 TabNet 模型使用 Nd=Na=32, λsparse=0.001, B=8192, BV =256, mB=0.9, Nsteps=7 和 γ=1.2。每个feature transformer块使用两个共享和两个决策步骤相关的 FC 层、ghost BN 和 GLU 块。 Adam 以 0.01 的学习率(每 1000 次迭代衰减 0.9,指数衰减)进行 10k 次迭代。对于人口普查收入,数据集和比较模型规范如下(Oza 2005)。 TabNet 模型使用 Nd=Na=48, λsparse=0.001, B=8192, BV =256, mB=0.9, Nsteps=5 和 γ=1.5。特征变换器使用两个共享和两个决策步骤依赖的 FC 层、ghost BN 和 GLU 块。 Adam 以 0.02 的学习率(每 2000 次迭代衰减 0.7,指数衰减)进行 4k 次迭代。
Mushroom edibility:TabNet 模型使用 Nd=Na=8, λsparse=0.001, B=2048, BV =128, mB=0.9, Nsteps=3 和 γ=1.5。feature transformer使用两个共享和两个决策步骤相关的 FC 层、ghost BN 和 GLU 块。 Adam 以 0.01 的学习率(每 400 次迭代衰减 0.8,指数衰减)进行 10k 次迭代。
Adult Census Income:TabNet 模型使用 Nd=Na=16, λsparse = 0.0001, B=4096, BV =128, mB=0.98, Nsteps=5 和 γ=1.5。特征变换器使用两个共享层和两个决策步骤相关层,ghost BN 和 GLU 块。 Adam 以 0.02 的学习率(每 2.5k 次迭代衰减 0.4,指数衰减)用于 7.7k 次迭代。测试准确率达到 85.7%。
Ablation studies
表 11 显示了消融案例的影响。对于所有情况,迭代次数都在验证集上进行了优化。
获得高性能需要根据数据集的特征适当调整模型容量。减少单元数 Nd、Na 或决策步骤数 Nsteps 是逐渐降低容量而不显着降低性能的有效方法。另一方面,将这些参数增加到超过某个值会导致优化问题并且不会产生性能优势。用更简单的替代方案(例如单个共享层)替换 feature transformer 块仍然可以提供强大的性能,同时产生非常紧凑的模型架构。这表明了特征选择和顺序注意引入的归纳偏置的重要性。为了提高性能,增加 feature transformer 的深度是一种有效的方法。在增加深度的同时,跨决策步骤的feature transformer块之间的参数共享是减小模型大小而不降低性能的有效方法。与完全决策步骤相关块或完全共享块相比,我们确实观察到部分参数共享的好处。与 ReLU 等传统非线性相比,我们还观察到 GLU 的经验优势。
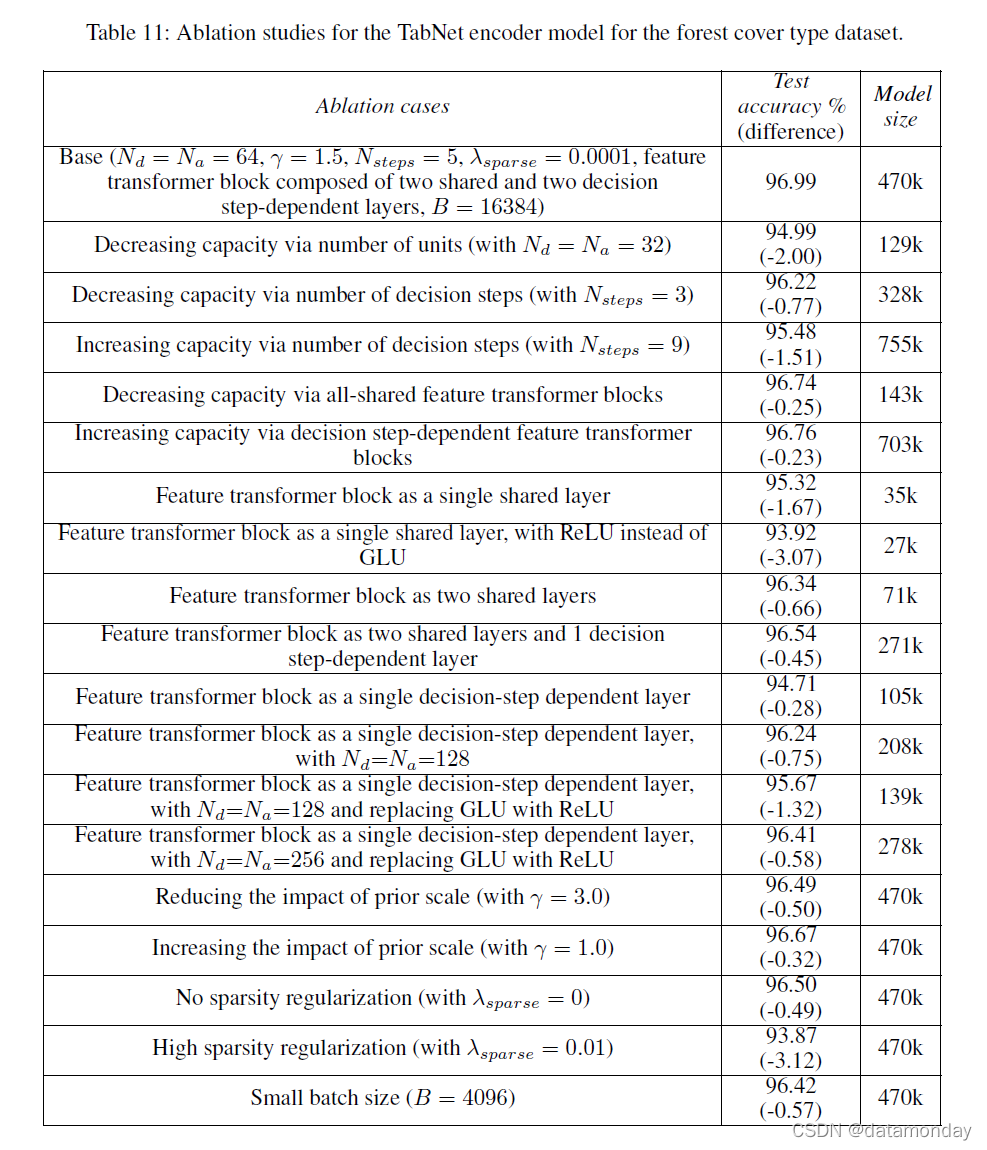
稀疏特征选择的强度取决于我们引入的两个参数:γ 和 λsparse。我们表明,这两者的最佳选择对性能很重要。接近 1 的 γ 或高 λsparse 可能会对稀疏强度产生过紧的约束,并可能会损害性能。另一方面,仍然有足够低的 γ 和足够高的 λsparse 的好处,以通过有利的归纳偏置来帮助模型学习。
最后,鉴于固定模型架构,我们展示了由 ghost BN 启用的大批量训练的好处((Hoffer, Hubara, and Soudry 2017)。 TabNet 的最佳批量大小似乎远高于用于其他数据类型(例如图像或语音)的传统批量大小。
Guidelines for hyperparameters
我们考虑从 10 K 到 10 M ~10K到~10M 10K到 10M 样本的数据集,具有不同程度的拟合难度。TabNet 通过一些关于超参数的一般原则在所有方面都获得了高性能:
- 对于大多数数据集,Nsteps ∈ [3, 10] 是最优的。通常,当有更多的信息承载特征时,Nsteps 的最佳值往往更高。另一方面,将其增加到超过某个值可能会对训练动态产生不利影响,因为网络中的某些路径变得更深并且存在更多潜在问题的病态矩阵。非常高的 Nsteps 值可能会受到过拟合的影响并产生较差的泛化性。
- 调整 Nd 和 Na 是一种在性能和复杂性之间取得折衷的有效方法。 Nd = Na 对于大多数数据集来说是一个合理的选择。
- γ 的最佳选择对性能有重要影响。通常,较大的 Nsteps 值有利于较大的 γ。
- 大批量是有益的——如果内存限制允许,大至总训练数据集大小的 1-10% 可以帮助提高性能。虚拟批量大小通常要小得多。
- 最初大的学习率很重要,应该逐渐衰减直到收敛。
















 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











