






1、飞桨PGL介绍
Paddle Graph Learning (PGL)是一个基于PaddlePaddle的高效易用的图学习框架

在最新发布的 PGL 中引入了异质图的支持,新增MetaPath采样支持异质图表示学习,新增异质图Message Passing机制支持基于消息传递的异质图算法,利用新增的异质图接口,能轻松搭建前沿的异质图学习算法。而且,在最新发布的PGL中,同时也增加了分布式图存储以及一些分布式图学习训练算法,例如,分布式deep walk和分布式graphsage。结合PaddlePaddle深度学习框架,我们的框架基本能够覆盖大部分的图网络应用,包括图表示学习以及图神经网络。
目前业界知识表示模型层出不穷,例如 TransE、RotatE 等。飞桨 PGL 基于大规模知识表示库 PGL-KE,对已有算法升级提出了 Normalized Orthogonal Transforms Embedding(NOTE)模型,能够对关系进行多维度建模,同时能在大规模场景下仍保持数值稳定性。

另外,飞桨 PGL 也迎来重大升级,推出了万亿超大规模分布式图引擎,分布式图引擎研发的初衷也是希望图学习算法可以在业界实现更大规模的产业应用,目前,百度已借助飞桨 PGL 在搜索、信息流推荐、金融风控、智能地图、知识图谱等多个场景实现数十项应用落地。 飞桨 PGL 还与多个外部机构合作:网易云音乐在调研了大量开源方案后,也选择了对大规模图训练更加友好的飞桨 PGL 作为云音乐推荐的图神经网络基础框架。同时,飞桨 PGL 也助力科技创新 2030「新一代人工智能」重大项目 OpenKS 知识计算引擎。
源于图神经网络对于复杂数据建模的便利以及其强大的表达能力,飞桨 PGL 也探究图神经网络与多个交叉学科的结合,包括构建大数据疫情预测系统,与飞桨螺旋桨 PaddleHelix 合作致力于化合物属性预测,并在多个化合物预测榜单上取得 SOTA。

图学习作为通用的人工智能算法之一,势必成为智能时代新的基础能力,赋能各行各业,助力智能经济腾飞。现阶段仅仅是图学习热潮的开始,未来还将有更加深度的技术产出,和更大规模的产业机会出现,扎根图学习领域,持续为产业智慧化升级赋能,需要从现在就开始。
PGL 链接:
https://github.com/PaddlePaddle/PGL
B 站 图神经网络 7 日教程:
https://www.bilibili.com/video/BV1rf4y1v7cU
PGL 图学习入门教程:
https://aistudio.baidu.com/aistudio/projectdetail/413386
2、知识图谱嵌入:TransE介绍
TransE模型是针对给定三元组进行计算“能量”达到优化目的,其中负例是通过替换头实体或者尾实体自行构造的,优化目标就是使得正负例样本距离最大化,通过最小化正样本的“能量”,最大化负样本的“能量”,达到优化嵌入表示的目的。

(一)算法流程图
TransE的算法流程图下图所示:

(二)算法伪代码
伪代码的意思是:
input: 输入模型的参数是训练集的三元组,实体集E,关系集L,margin,向量的维度k
1:初始化: 对于关系按照1的初始化方式初始化即可
2:这里进行了L2范数归一化,也就是除以自身的L2范数
3:同理,也对实体进行了初始化,但是这里没有除以自身的L2范数
4:训练的循环过程中:
5:首先对实体进行了L2范数归一化
6:取一个batch的样本,这里Sbatch代表的是正样本,也就是正确的三元组
7: 初始化三元组对,应该就是创造一个用于储存的列表
8,9,10:这里的意思应该是根据Sbatch的正样本替换头实体或者尾实体构造负样本,然后把对应的正样本三元组和负样本三元组放到一起,组成Tbatch
11:完成正负样本的提取
12:根据梯度下降更新向量
13:结束循环
3、实验过程
3.1 数据准备
数据准备(数据处理):从本地或 URL 读取数据,并完成预处理操作(如数据校验、格式转化等),保证模型可读性。
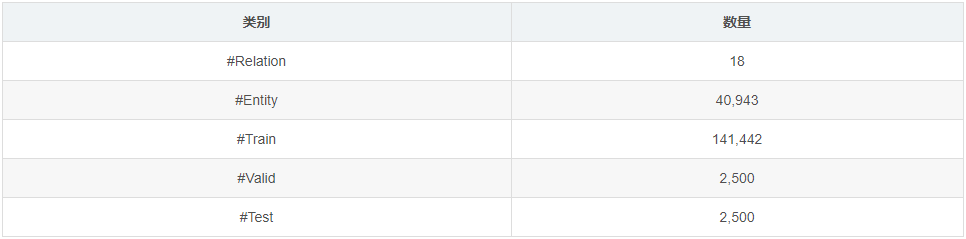
本次实验数据采用数据集 WN18 ,分为训练集和测试集。利用训练集进行transE建模,通过训练为每个实体和关系建立起向量映射,并在测试集中计算MeanRank和Hit10指标进行结果检验。
数据集 WN18 是 WordNet 的子集,包含18种关系和40k种实体。
WN18: https://drive.google.com/open?id=1MXy257ZsjeXQHZScHLeQeVnUTPjltlwD
# 下载数据(本环境中已经下载好,此步骤可忽略)
%pwd
%cd /home/aistudio/
!sh download.sh
# 对下载数据解压并移动到指定位置
# %pwd
# %cd /home/aistudio/data/
# !tar xvf WN18RR.tar.gz -C WN18RR
# !tar xvf FB15k-237.tar.gz -C FB15k-237
# !tar xvf fb15k.tgz -C FB15k
# !mv FB15k/FB15k/freebase_mtr100_mte100-train.txt FB15k/train.txt
# !mv FB15k/FB15k/freebase_mtr100_mte100-valid.txt FB15k/valid.txt
# !mv FB15k/FB15k/freebase_mtr100_mte100-test.txt FB15k/test.txt# 切换回工作空间位置
%cd /home/aistudio/work
%pwd3.2 环境准备(初始化)
在工作环境中,引入paddle、pgl等相关依赖包。导包: 运行这些模型的脚本。
"""
The script to run these models.
"""
import argparse
import timeit
import os
import numpy as np
import paddle.fluid as fluid
import paddle
from data_loader import KGLoader
from evalutate import Evaluate
from model import model_dict
from model.utils import load_var
from mp_mapper import mp_reader_mapper
from pgl.utils.logger import log
paddle.enable_static()3.3 模型设计
模型设计:网络结构设计,相当于模型的假设空间,即模型能够表达的关系集合。
选择迭代次数5000次,学习率0.01进行训练。损失函数变化如下:

3.3.1、评价指标
3.3.1.1 Mean rank
对于测试集的每个三元组,以预测tail实体为例,我们将(h,r,t)中的t用知识图谱中的每个实体来代替,然后通过distance(h, r, t)函数来计算距离,这样我们可以得到一系列的距离,之后按照升序将这些分数排列。
distance(h, r, t)函数值是越小越好,那么在上个排列中,排的越前越好。
现在重点来了,我们去看每个三元组中正确答案也就是真实的t到底能在上述序列中排多少位,比如说t1排100,t2排200,t3排60.......,之后对这些排名求平均,mean rank就得到了。
3.3.1.2 Hit@10
还是按照上述进行函数值排列,然后去看每个三元组正确答案是否排在序列的前十,如果在的话就计数+1
本实验的TransE模型设计,可查阅/home/aistudio/work/model/TransE.py文件。
"""
The TransE Model.
"""
def __init__(self,
data_reader,
hidden_size,
margin,
learning_rate,
args,
optimizer="adam"):
self._neg_times = args.neg_times
super(TransE, self).__init__(
model_name="TransE",
data_reader=data_reader,
hidden_size=hidden_size,
margin=margin,
learning_rate=learning_rate,
args=args,
optimizer=optimizer)
self.construct()
def creat_share_variables(self):
"""
Share variables for train and test programs.
创建共享变量
"""
# fluid.layers.create_parameter 该OP创建一个参数,该参数是一个可学习的变量, 拥有梯度并且可优化
entity_embedding = fluid.layers.create_parameter(
shape=self._ent_shape, dtype="float32", name=self.ent_name)
relation_embedding = fluid.layers.create_parameter(
shape=self._rel_shape, dtype="float32", name=self.rel_name)
return entity_embedding, relation_embedding
@staticmethod
def score_with_l2_normalize(head, rel, tail):
"""
定义一个计算首尾实体以及关系的特征函数,用l2标准化评分
Score function of TransE
TransE的得分函数
"""
head = fluid.layers.l2_normalize(head, axis=-1)
rel = fluid.layers.l2_normalize(rel, axis=-1)
tail = fluid.layers.l2_normalize(tail, axis=-1)
score = head + rel - tail # 首实体+关系-尾实体 #一范数
return score
def construct_train_program(self):
"""
Construct train program.
构建训练程序
"""
# 初始化定义好相关参数,通过计算最小化loss来优化更新ent_embeddings,rel_embeddings两个矩阵
# pos代表好的三元组里面的首实体尾实体和关系,neg则代表不相关的
entity_embedding, relation_embedding = self.creat_share_variables()
pos_head = lookup_table(self.train_pos_input[:, 0], entity_embedding)
pos_tail = lookup_table(self.train_pos_input[:, 2], entity_embedding)
pos_rel = lookup_table(self.train_pos_input[:, 1], relation_embedding)
neg_head = lookup_table(self.train_neg_input[:, 0], entity_embedding)
neg_tail = lookup_table(self.train_neg_input[:, 2], entity_embedding)
neg_rel = lookup_table(self.train_neg_input[:, 1], relation_embedding)
pos_score = self.score_with_l2_normalize(pos_head, pos_rel, pos_tail)
neg_score = self.score_with_l2_normalize(neg_head, neg_rel, neg_tail)
pos = fluid.layers.reduce_sum(
fluid.layers.abs(pos_score), 1, keep_dim=False)
neg = fluid.layers.reduce_sum(
fluid.layers.abs(neg_score), 1, keep_dim=False)
neg = fluid.layers.reshape(
neg, shape=[-1, self._neg_times], inplace=True)
loss = fluid.layers.reduce_mean(
fluid.layers.relu(pos - neg + self._margin))
return [loss]
def construct_test_program(self):
"""
Construct test program
"""
entity_embedding, relation_embedding = self.creat_share_variables()
entity_embedding = fluid.layers.l2_normalize(entity_embedding, axis=-1)
relation_embedding = fluid.layers.l2_normalize(
relation_embedding, axis=-1)
head_vec = lookup_table(self.test_input[0], entity_embedding)
rel_vec = lookup_table(self.test_input[1], relation_embedding)
tail_vec = lookup_table(self.test_input[2], entity_embedding)
# The paddle fluid.layers.topk GPU OP is very inefficient
# we do sort operation in the evaluation step using multiprocessing.
id_replace_head = fluid.layers.reduce_sum(
fluid.layers.abs(entity_embedding + rel_vec - tail_vec), dim=1)
id_replace_tail = fluid.layers.reduce_sum(
fluid.layers.abs(entity_embedding - rel_vec - head_vec), dim=1)
return [id_replace_head, id_replace_tail]3.4 训练配置
训练配置:设定模型采用的寻解算法,即优化器,并指定计算资源。
运行程序一个时期。
:param batch_iter:准备数据的batch_ite。
:param程序:运行程序、train_program或测试程序。
:param exe:Paddle 的执行器。
:param fetch_list:要获取的变量。
:param epoch:训练进程的epoch编号。
:param prefix:前缀名称,键入“string”。
:param log_per_step:每个步骤的日志。
def run_round(batch_iter,
program,
exe,
fetch_list,
epoch,
prefix="train",
log_per_step=1000):
"""
Run the program for one epoch.
:param batch_iter: the batch_iter of prepared data.
:param program: the running program, train_program or test program.
:param exe: the executor of paddle.
:param fetch_list: the variables to fetch.
:param epoch: the epoch number of train process.
:param prefix: the prefix name, type `string`.
:param log_per_step: log per step.
:return: None
"""
batch = 0
tmp_epoch = 0
loss = 0
tmp_loss = 0
run_time = 0
data_time = 0
t2 = timeit.default_timer()
start_epoch_time = timeit.default_timer()
for batch_feed_dict in batch_iter():
batch += 1
t1 = timeit.default_timer()
data_time += (t1 - t2)
batch_fetch = exe.run(program,
fetch_list=fetch_list,
feed=batch_feed_dict)
if prefix == "train":
loss += batch_fetch[0]
tmp_loss += batch_fetch[0]
if batch % log_per_step == 0:
tmp_epoch += 1
if prefix == "train":
log.info("Epoch %s (%.7f sec) Train Loss: %.7f" %
(epoch + tmp_epoch,
timeit.default_timer() - start_epoch_time,
tmp_loss[0] / batch))
start_epoch_time = timeit.default_timer()
else:
log.info("Batch %s" % batch)
batch = 0
tmp_loss = 0
t2 = timeit.default_timer()
run_time += (t2 - t1)
if prefix == "train":
log.info("GPU run time {}, Data prepare extra time {}".format(
run_time, data_time))
log.info("Epoch %s \t All Loss %s" % (epoch + tmp_epoch, loss))3.5 训练过程
训练过程:循环调用训练过程,每轮都包括前向计算、损失函数(优化目标)和后向传播三个步骤。
def train(args):
"""
Train the knowledge graph embedding model.
:param args: all args.
:return: None
"""
kgreader = KGLoader(
batch_size=args.batch_size,
data_dir=args.data_dir,
neg_mode=args.neg_mode,
neg_times=args.neg_times)
if args.model in model_dict:
Model = model_dict[args.model]
else:
raise ValueError("No model for name {}".format(args.model))
model = Model(
data_reader=kgreader, # 数据加载器
hidden_size=args.hidden_size,# 神经网络的隐藏节点(神经元)
margin=args.margin, # 表示正负样本之间的间距,是一个超参数,也就是公式中Loss里的γ;loss时设置有一个边缘值‘甘码’(y表示),代码中用margin表示;margin (以下称作间隔)被认为是模型泛化能力的保证,但在神经网络时代使用的最多的损失函数 Softmax 交叉熵损失中并没有显式地引入间隔项;
learning_rate=args.learning_rate, # 学习率,其实就是梯度下降中的步长
args=args,
optimizer=args.optimizer) # 模型优化器:一般设置为adam
def iter_map_wrapper(data_batch, repeat=1):
"""
wrapper for multiprocess reader
:param data_batch: the source data iter.
:param repeat: repeat data for multi epoch
:return: iterator of feed data
"""
def data_repeat():
"""repeat data for multi epoch"""
for i in range(repeat):
for d in data_batch():
yield d
reader = mp_reader_mapper(
data_repeat,
func=kgreader.training_data_no_filter
if args.nofilter else kgreader.training_data_map,
num_works=args.sample_workers)
return reader
def iter_wrapper(data_batch, feed_list):
"""
Decorator of make up the feed dict
:param data_batch: the source data iter.
:param feed_list: the feed list (names of variables).
:return: iterator of feed data.
"""
def work():
"""work"""
for batch in data_batch():
feed_dict = {}
for k, v in zip(feed_list, batch):
feed_dict[k] = v
yield feed_dict
return work
loader = fluid.io.DataLoader.from_generator(
feed_list=model.train_feed_vars, capacity=20, iterable=True)
places = fluid.cuda_places() if args.use_cuda else fluid.cpu_places()
exe = fluid.Executor(places[0])
exe.run(model.startup_program)
exe.run(fluid.default_startup_program())
if args.pretrain and model.model_name in ["TransR", "transr"]:
pretrain_ent = os.path.join(args.checkpoint,
model.ent_name.replace("TransR", "TransE"))
pretrain_rel = os.path.join(args.checkpoint,
model.rel_name.replace("TransR", "TransE"))
if os.path.exists(pretrain_ent):
print("loading pretrain!")
#var = fluid.global_scope().find_var(model.ent_name)
load_var(exe, model.train_program, model.ent_name, pretrain_ent)
#var = fluid.global_scope().find_var(model.rel_name)
load_var(exe, model.train_program, model.rel_name, pretrain_rel)
else:
raise ValueError("pretrain file {} not exists!".format(
pretrain_ent))
prog = fluid.CompiledProgram(model.train_program).with_data_parallel(
loss_name=model.train_fetch_vars[0].name)
if args.only_evaluate:
s = timeit.default_timer()
fluid.io.load_params(
exe, dirname=args.checkpoint, main_program=model.train_program)
Evaluate(kgreader).launch_evaluation(
exe=exe,
reader=iter_wrapper(kgreader.test_data_batch,
model.test_feed_list),
fetch_list=model.test_fetch_vars,
program=model.test_program,
num_workers=10)
log.info(timeit.default_timer() - s)
return None
batch_iter = iter_map_wrapper(
kgreader.training_data_batch,
repeat=args.evaluate_per_iteration, )
loader.set_batch_generator(batch_iter, places=places)
for epoch in range(0, args.epoch // args.evaluate_per_iteration):
run_round(
batch_iter=loader,
exe=exe,
prefix="train",
# program=model.train_program,
program=prog,
fetch_list=model.train_fetch_vars,
log_per_step=kgreader.train_num // args.batch_size,
epoch=epoch * args.evaluate_per_iteration)
log.info("epoch\t%s" % ((1 + epoch) * args.evaluate_per_iteration))
fluid.io.save_params(
exe, dirname=args.checkpoint, main_program=model.train_program)
if not args.noeval:
eva = Evaluate(kgreader)
eva.launch_evaluation(
exe=exe,
reader=iter_wrapper(kgreader.test_data_batch,
model.test_feed_list),
fetch_list=model.test_fetch_vars,
program=model.test_program,
num_workers=10)3.6 模型预测
def main():
"""
The main entry of all.
:return: None
"""
parser = argparse.ArgumentParser(
description="Knowledge Graph Embedding for PGL")
parser.add_argument('--use_cuda', action='store_true', help="use_cuda")
parser.add_argument(
'--data_dir',
dest='data_dir',
type=str,
help='the directory of dataset',
default='/home/aistudio/data/data176054/')
parser.add_argument(
'--model',
dest='model',
type=str,
help="model to run",
default="TransE")
parser.add_argument(
'--learning_rate',
dest='learning_rate',
type=float,
help='learning rate',
default=0.001)
parser.add_argument(
'--epoch', dest='epoch', type=int, help='epoch to run', default=400)
parser.add_argument(
'--sample_workers',
dest='sample_workers',
type=int,
help='sample workers',
default=4)
parser.add_argument(
'--batch_size',
dest='batch_size',
type=int,
help="batch size",
default=1000)
parser.add_argument(
'--optimizer',
dest='optimizer',
type=str,
help='optimizer',
default='adam')
parser.add_argument(
'--hidden_size',
dest='hidden_size',
type=int,
help='embedding dimension',
default=50)
parser.add_argument(
'--margin', dest='margin', type=float, help='margin', default=4.0) # loss时设置有一个边缘值‘甘码’(y表示),代码中用margin表示
parser.add_argument(
'--checkpoint',
dest='checkpoint',
type=str,
help='directory to save checkpoint directory',
default='output/')
parser.add_argument(
'--evaluate_per_iteration',
dest='evaluate_per_iteration',
type=int,
help='evaluate the training result per x iteration',
default=50)
parser.add_argument(
'--only_evaluate',
dest='only_evaluate',
action='store_true',
help='only do the evaluate program',
default=False)
parser.add_argument(
'--adv_temp_value', type=float, help='adv_temp_value', default=2.0)
parser.add_argument('--neg_times', type=int, help='neg_times', default=1)
parser.add_argument(
'--neg_mode', type=bool, help='return neg mode flag', default=False)
parser.add_argument(
'--nofilter',
type=bool,
help='don\'t filter invalid examples',
default=False)
parser.add_argument(
'--pretrain',
type=bool,
help='pretrain for TransR model',
default=False)
parser.add_argument(
'--noeval',
type=bool,
help='whether to evaluate the result',
default=False)
# args = parser.parse_args()
args = parser.parse_known_args()[0]
log.info(args)
print('---组参完成---')
train(args)4、实验结果
指标如下:
MeanRank: 230.38,MRR: 0.4860,Hits@1: 0.1725,Hits@3: 0.7794,Hits@10: 0.9346
结果存储在:
/home/aistudio/work/output/TransE__dim=50_entity_embeddings
/home/aistudio/work/output/TransE__dim=50_relation_embeddings
5、链接预测
通过transE建模后,我们得到了每个实体和关系的嵌入向量,利用嵌入向量,我们可以进行知识图谱的链接预测
将三元组(head,relation,tail)记为(h,r,t),链接预测分为三类
1、头实体预测:(?,r,t)
2、关系预测:(h,?,t)
3、尾实体预测:(h,r,?)
原理:利用向量的可加性即可实现。以(h,r,?)的预测为例:
假设t'=h+r,则在所有的实体中选择与t'距离最近的向量,即为t的的预测值















 1839
1839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









