





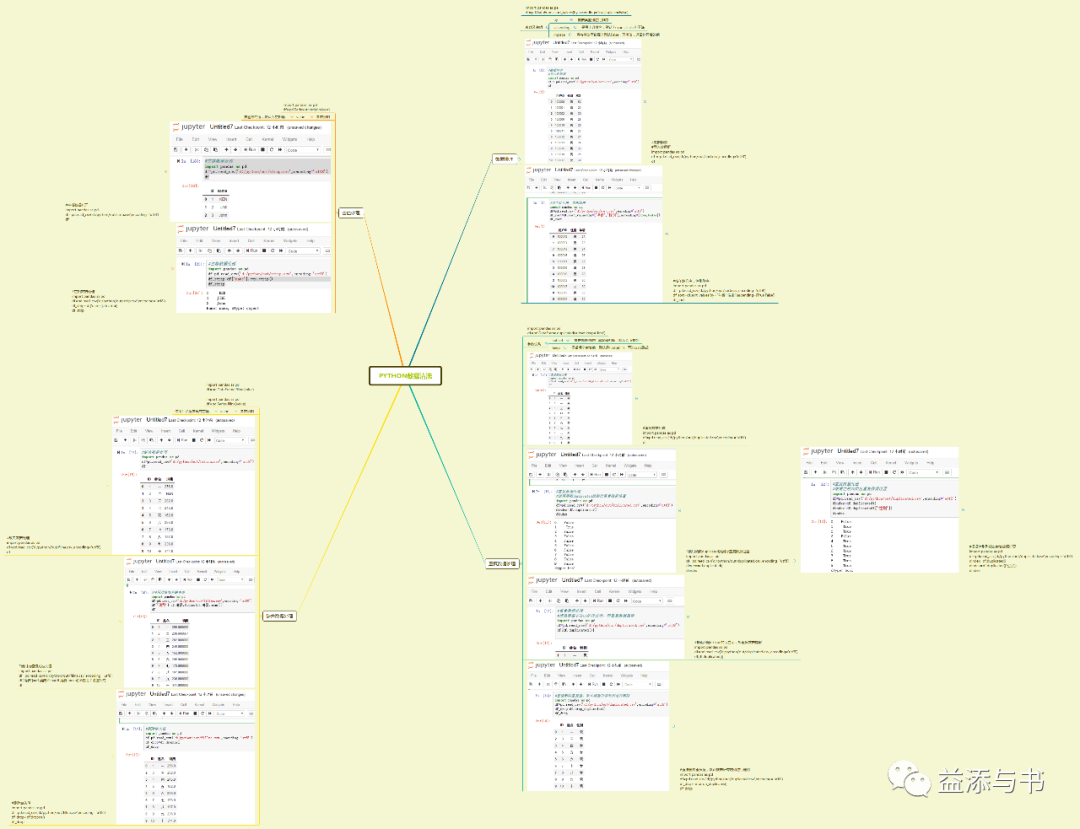
python数据清洗
数据排序
import pandas as pa
df=pd.DataFrame.sort_values(by,ascending=True,inplace=False)
参数及说明
by
根据某些列进行排序
ascending
是否上升排序,默认为True,False为下降
inplace
直接修改原数据?默认False,不修改,返回处理后的值
#数据排序#导入数据框import pandas as pddf = pd.read_csv('d:/python/out/sort.csv',encoding='utf8')df#按年龄升序,性别降序import pandas as pddf=pd.read_csv('d:/python/out/sort.csv',encoding='utf8')df_sort=df.sort_values(by=['年龄','性别'],ascending=[True,False])df_sort重复数据处理
import pandas as pd
df=pd.DataFrame.duplicated(subset,keep='first')
参数说明
subset
根据哪些列进行重复值判断,默认为所有列
keep
保留哪个重复值,默认是first(首个),可选last(最后)
#重复数据处理import pandas as pddf=pd.read_csv('d:/python/out/duplicated.csv',encoding='utf8')df#使用函数duplicated找到行重复数据位置import pandas as pddf=pd.read_csv('d:/python/out/duplicated.csv',encoding='utf8')dindex=df.duplicated()dindex#根据性别列找出重复数据位置import pandas as pddf=pd.read_csv('d:/python/out/duplicated.csv',encoding='utf8')dindex=df.duplicated()dindex=df.duplicated(['性别'])dindex#把返回值中True的行显示,即重复数据提取import pandas as pddf=pd.read_csv('d:/python/out/duplicated.csv',encoding='utf8')df[df.duplicated()]#直接删除重复值,默认根据所有的列进行删除import pandas as pddf=pd.read_csv('d:/python/out/duplicated.csv',encoding='utf8')df_drop=df.drop_duplicates()df_drop缺失数据处理
import pandas as pd
df=pd.DataFrame.fillna(value)
import pandas as pd
df=pd.Series.fillna(value)
参数说明
value
使用什么值来填充空值
#缺失数据处理import pandas as pddf=pd.read_csv('d:/python/out/fillna.csv',encoding='utf8')df#使用均值填充缺失值import pandas as pddf=pd.read_csv('d:/python/out/fillna.csv',encoding='utf8')df['消费']=df.消费.fillna(df.消费.mean())#使用平均值补充df#删除缺失值import pandas as pddf=pd.read_csv('d:/python/out/fillna.csv',encoding='utf8')df_drop=df.dropna()df_drop空值处理
import pandas as pd
df=pd.Series.str.strip(value=)
参数说明
value
要剔除的值,默认为空格值
#空格数据处理import pandas as pddf=pd.read_csv('d:/python/out/strip.csv',encoding='utf8')df#空格数据处理import pandas as pddf=pd.read_csv('d:/python/out/strip.csv',encoding='utf8')df_strip=df['name'].str.strip()df_strip学习小结:
数据清洗是数据可视化基础,因此梳理常见清洗步骤。数据清洗的目的就是将原始数据转化为可以进行数据分析的形式,使数据保持准确性、一致性、有效性。
数据清洗最常见的方法有数据排序、重复数据处理、缺失数据处理、空格数据处理。
排序:是按一定顺序将数据排列,以便通过浏览数据发现一些明显的特征、规律或趋势。
重复数据查找:包括重复数据查找与重复数据删除;
重复数据删除是将数据中重复多余的数据进行删除处理,以保证数据的唯一性,也称为数据去重。
缺失数据处理:一般情况,缺失比例不高于30%,尽量别删除,而是选择数据补齐。数据补齐除了用0补充、平均值填充、众数(大多数)填充,还有向前填充(即用缺失数据值的前一非缺失值填充)、向后填充等方式。















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









