






 在设备能力研究中,选择合适的分布模型至关重要。通常依据经验数据、理论分布和公差类型来预设模型,并通过偏度、峰度等检验方法验证。Q-Das软件提供了自动分析流程,确保数据的准确性和一致性。如果分布模型不符,可能需要质量部门批准,即使能力指数达标。能力研究的目标是评估特征值的集中度和离散度。
在设备能力研究中,选择合适的分布模型至关重要。通常依据经验数据、理论分布和公差类型来预设模型,并通过偏度、峰度等检验方法验证。Q-Das软件提供了自动分析流程,确保数据的准确性和一致性。如果分布模型不符,可能需要质量部门批准,即使能力指数达标。能力研究的目标是评估特征值的集中度和离散度。

问:在设备能力研究中,如何合理的选择分布模型?
答:在能力研究的统计方法中,我们需要推断样本背后“虚构”的总体,用分布模型去描述总体中数值的分布情况,通常在推断分布模型时主要是想通过样本看总体能否用预计的分布模型描述,对于预计的分布模型如何选择,是一个需要考虑的问题。
1、 能力证明在实践中的意义和需要考虑的问题

就像前面所讲到的,进行机器或过程能力研究时,我们背后的理论是基于田口的品质损失函数,即我们希望机器或过程中其它因素导致的特性值变差小。我们在研究中抽取样品,测量样品的特征值,对特征值进行统计分析,最终的目的是来获取特性值变差方面的信息的,并与规格要求进行比较。我们不仅希望了解样本的信息,也想通过样本来推断总体,预测将来特性值的分布是否靠近目标中心,同时离散小。
尽管有些特性我们称为连续型的特征值,但由于测量的技术水平原因,实践中得到的测量值总是只有有限个不同的值,即数值是"离散"的(一般最好能有10个以上不同的数值,Q-Das公司建议是至少有5-7个以上不同的数值)。具体不同数值的个数取决于量具分辨率和过程变差两个方面。当不同数值的个数较少时,通常是无法合理的通过样本数据对总体的分布模型进行推断的(即使如此,我们分析的最终目标并不是去推断分布模型)。
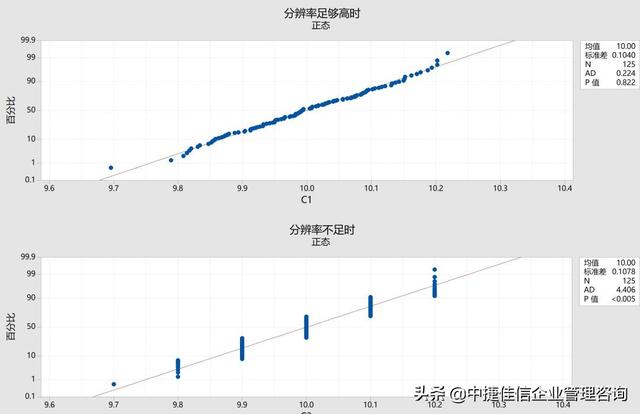
如上图所示,通常只有当量具有足够的分辨率,我们才能“合理的”推断总体的分布模型。
2、 如何合理的选择分布模型?

在Q-Das软件中,以设备能力研究为例,在分布模型的选择上通常有以下如何考虑步骤
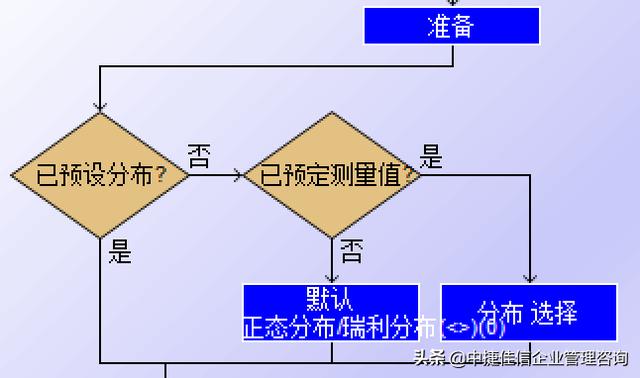
1、是否有以往的经验数据,用预设分布模型做为预计的分布模型;
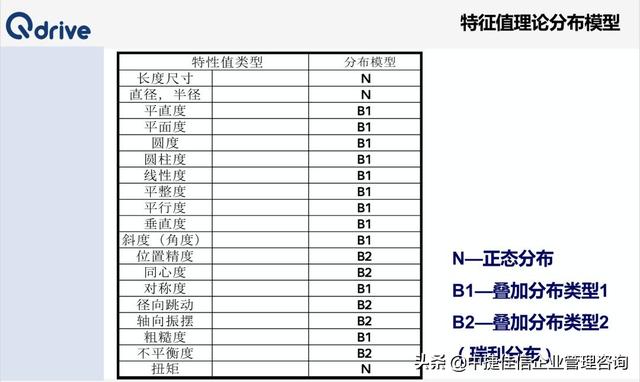
2、根据被测特性的类型,根据理论的分布模型来选择预计的分布模型(如下图所示);
3、根据单边或双边公差选择合适的分布来作为预计的分布模型,当然,关于默认分布模型的选择,根据不同的标准,有不同的选择。
一旦有了预计的分布模型,用样本中的数值分布情况去推断总体能为预计的分布模型。推断时,对于预计是正态分布时,可以用常用偏度,峰度,AD等检验方法,对于不是正态分布通常可以用卡方检验来看是否是预计的分布模型。
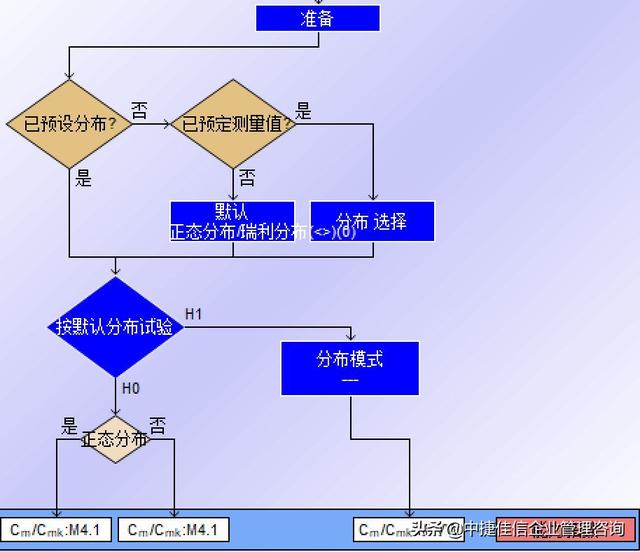

检验的结果如果是预计的分布模型,则选择该模型描述总体。
检验的结果如果不是预计的分布模型,就需要基于公司的标准,在不同的分布模型中选择最优的分布,选择的方法可以基于卡方检验的结果和100%的拟合优度,以及靠近关健界限处25%的拟合优度的来评价选择。(备注,如果不是预计的模型,在大众VW10130标准中用无分布来描述,并且规定了无分布时计算能力指数的方法)
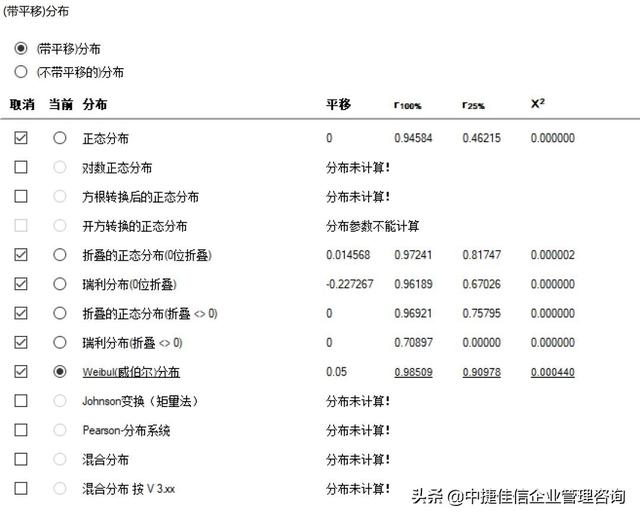
一旦分布模型选定好后,即可以基于ISO22514中的方法计算能力指数。
当是预计的分布模型时,能力指数合格,则机器能力合格
当不是预计分布模型时,有的公司标准要求,即使能力指数达到目标(如 cmk>=1.67),也不能认为机器能力合格,通常称为是有条件合格。此时的有条件需要质量部门来批准,会综合考虑测量量具分辨率,cmk的值的大小来评定,我们进行能力分析的目的是要考查特征值是否靠近目标,是否离散小,分布模型只是分析问题的工具。
3、 总结

在这篇短文中,我们介绍了Q-Das软件的机器能力研究中选择分布模型的流程,这些流程如果要靠人工去操作电脑一步一步执行,出现差错的概率会很高。在Q-Das软件中,将这些流程定义在评估策略中,由软件自动执行分析判定。工程技术人员需要了解的是能力研究的目的是评价测量特征值是否靠近目标中心,是否离散小。并能结合图形检验数据随时间的趋势是否合理,并检查以下两点
1、机器能力研究时,机器加工的零件特征值是否符合预计的分布模型,即是否能按照预计的分布模型来生产;
2 、机器能力是否足够。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









