






Fully convolutinal networks for semantic segmentations
——CVPR 2015
-
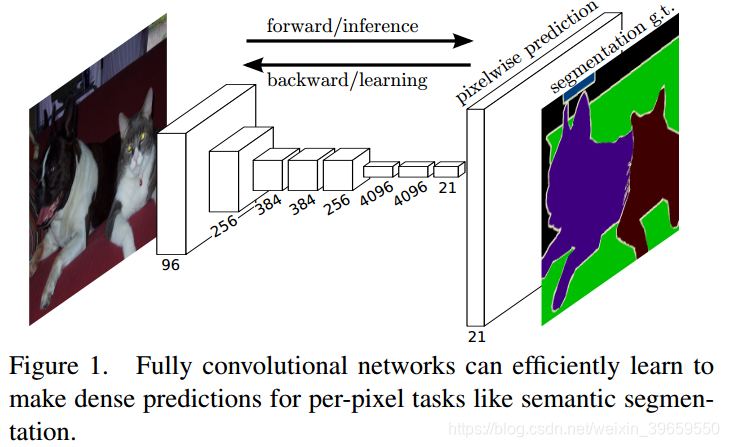
把CNN重新定义为FCN,卷积神经网络经过端到端(end-to-end),像素到像素(pixel-to-pixel)的训练之后,能够很好地用于语义分割。输入一幅任意尺寸的图像后,直接在输出端得到dense prediction,即每个像素所属的class,用segmentation的ground truth作为监督信息,进行训练。
作者提出了一个新型的“skip”结构,将深层、粗糙的semantic information与浅层、精细的appearance information结合起来。全局信息(seantic information)决定是什么,局部信息(appearance information)决定在哪。
传统的基于CNN的分割方法:为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测。这种方法有几个缺点:一是存储开销很大。例如对每个像素使用的图像块的大小为15x15,然后不断滑动窗口,每次滑动的窗口给CNN进行判别分类,因此则所需的存储空间根据滑动窗口的次数和大小急剧上升。二是计算效率低下。相邻的像素块基本上是重复的,针对每个像素块逐个计算卷积,这种计算也有很大程度上的重复。三是像素块的大小限制了感知区域的大小。通常像素块的大小比整幅图像的大小小很多,只能提取一些局部的特征,从而导致分类的性能受到限制。
而全卷积神经网络(FCN)则是从抽象的特征中恢复出每个像素所属的类别,即从图像级别的分类进一步延伸到像素级别的分类。
- 全连接层-- >>卷积层
我们已有一个CNN模型,首先将CNN的全连接层看成是卷积层,卷积核的大小就是输入的特征map的大小,也就是把全连接层网络看成是对整张输入特征map做卷积。因而,全连接层分别有4096个7×7的卷积核(github上的源码也显示大小为7),4096个1×1的卷积核,1000个1×1的卷积核。如下图:
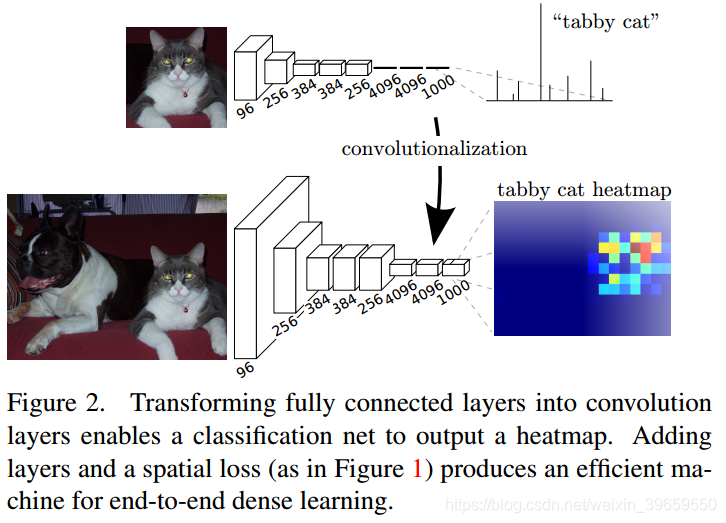 |
接下来,对这1000个1×1的输出,做upsampling(即反卷积deconvolution),得到1000个原图大小(如32×32)的输出,这些输出合并后,得到上图所示的heatmap(如何合并?)。这里有一个小trick,最后通过逐个像素地求其在1000张像素位置的最大数值描述(概率)作为该像素的分类。因此产生一张已经分类好的图片,如下图所示。
反卷积的参数不需要固定,而是具有学习功能。
 |
作者为实现dense prediction,比较了三个方案,分别是shift-and-stitch, decreasing subsampling 和 deconvolution + skip 结构。
- shift-and-stitch:

设网络只有一层 2x2 的maxpooling 层,所以下采样因子 f =2。下面以向左上方shift为例,(此处是向左上方shift,右下方padding,我觉得卷积应该从右下方开始,下面的图应该是有错误的,但不影响整体思想):
|
|

原始图像经过shift和padding 后,得到f^2=4个input:
 |
4个input分别进行2×2的maxpooling后,共产生4个output:
上图中灰色区域代表receptive field中心重叠的像素。例如,黄色output中的像素5与红色output中的像素5对应receptive中心是重叠的。
最后,stitch the 4 different output获得dense prediction:
那么,如何进行stitch呢?FCN中说明:
Process each of these f2 inputs, and interlace the outputs so that the predictions correspond to the pixels at the centers of their receptive fields.
 |
即output中的每个pixel都对应original image的不同receptive field,将receptive field的中心c填入这个来自output的pixel值,就是网络对original image中像素c的prediction。
求centers of their receptive fields:
(没找到具体的公式,感觉像是重心)
- decreasing subsampling:
 |
考虑其中某一层L1(卷积层或汇聚层)具有stride=s,后面的卷积层L2具有卷积核权重fij。现在设置原本L1的stride=1,避免降采样的出现(相当于对原来L1的输出进行因子为s的上采样)。但是,直接对这样的上采样结果按照原本的卷积核操作并不能得到相等于shift-and-stitch的结果。因为这样的卷积核只能看到上采样结果的一小部分,所以扩大原本的卷积核,即rarefy filter:
需注意的是,这样的操作会造成一种tradeoff:卷积核如果需要看到更精细的信息,往往需要较小的感受野,且需要更多的计算。扩大了原本的卷积核,使感受野固定成较大的input size,不能完成精细的定位分割。
以上两种方法都没有被采用,因为都是tradeoff的:
b方法的缺点上面已经说了。a方法虽然没有使感受野变小,但由于原图被划分为f*f个区域,使得filters无法感受更精细的信息。
- deconvolution + skip
这里upsampling的操作其实是反卷积(deconvolutional),反卷积的参数不是固定的,而是在训练中学习的。
 |
以上是对CNN的结果做处理,得到了dense prediction,但结果比较粗糙,所以考虑加入更多前层的细节信息,即把倒数第几层的输出和最后的输出做一个fusion,实际上也就是加和:
4)卷积和反卷积:
卷积的矩阵操作:
将输入的4*4原始图像A展开成(16,1)的向量,则将大小为(3,3)的卷积核用于图像A等同于下面的矩阵操作。
C*A=B
其中,C为由卷积核得到的(16,4)矩阵;B为卷积得到的(4,1)向量,再reshape成(2,2)矩阵即为输出。
反卷积的矩阵操做:
若输入图像A大小为(2,2),则先展开成(4,1)的向量,则将卷积核用于图像A 等同于下面的矩阵操做。
C.T*A=B
其中,B为卷积后得到的(16,1)向量,再reshape成(4,4)的矩阵即为反卷积操做的输出结果。C.T为上面C的转置矩阵。
5)Patchwise training
(文章中关于patchwise training的介绍没怎么看懂,下面是从网上找的介绍。)
通常做语义分割都是使用patchwise training,就是将一张图片的重要部分裁剪下来进行训练,以避免整张图片直接进行训练所产生的信息冗余,这种方法有助于快速收敛。但本文提出直接使用整张图片也许能使效果更好,而patchwise training可能使信息受损(所以原文中说,patchwise training is loss sampling)。因为,一整张图片可能是空间相关性的,而patchwise就减少了这种相关性。














 1578
1578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









