






本文试图探讨反向传播算法,但只关注思想和原理,寻求一个直观感性的认识。所以,文中所举的例子、使用的公式都力图简单。
简,就意味着会损失细节、不够全面。如果对反向传播算法已经有所涉及,希望全面、深入了解的童鞋可以绕道,以免浪费时间。
一、付出与收获
诗《悯农》中有这么两句:
春种一粒粟,秋收万颗子。
问:如果一个农夫春天种下10粒种子,那么他秋天能收多少粮食?
因为一颗对一万颗,所以10颗种子收获的粮食为:
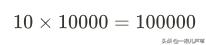
颗。
这是通常的做法儿,从机器学习的角度又该怎么解答呢?
首先建立一个模型。
假设种下x粒种子,可以收获y颗粮食。付出与收获成正比,比例因子为ω。于是得出学习模型如下:
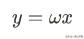
于是,问题就转化为,用该模型预测当种下:
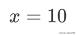
颗种子时,可以收获的粮食数:
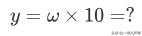
问题的关键是确定参数ω。
ω可以通过训练来确定,也就是所谓的机器学习。但要训练参数,首先要有训练数据。
从已知条件“春种一粒粟,秋收万颗子”中,可以提炼出一组训练数据:
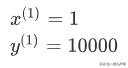
有了模型,有了数据,就可以开始训练了。
问题是训练什么?怎么训?
训练的目的是确定未知参数ω,依据是预测和目标趋于一致。
预测值:
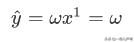
目标值:
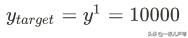
我们把预测值和目标值的偏差:
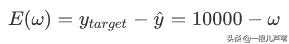
定义为损失函数。
训练的目标就转化为:
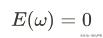
首先,给ω一个初值:
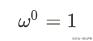
偏差为:
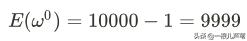
为了使偏差趋于0,该如何调ω呢,调大还是调小?
调整之前,先分析一下,ω参数对损失函数:
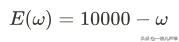
的影响。
对损失函数求导:
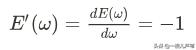
也就是说,ω和损失函数E(ω)的变化趋势相反。ω增加,E(ω)减小,ω减小,E(ω)也增加。并且增加或减小的量和E'(ω)相关。
可以看出来,导数值的符号反应了损失函数上升的方向,导数值的大小反应了上升得速率。
例如,这里的-1。符号为负,表示ω往负方向走,损失函数增加。值为1,表示ω走1单位,损失函数也增加1个单位。
如果将导数看成一个矢量,它反映的就是损失函数的上升速度。
由于我们的目标是要损失函数下降,和导数正好相反,所以就可以用负导数的方向作为参数调整的方向,导数值乘以一个系数作为参数调整的大小,公式表示如下:
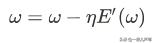
由于这里讨论的是一维空间,导数和梯度相等,高于一维的空间用的实际是梯度。
所以这种调参的策略又叫梯度下降法。
有了梯度下降公式,设η=1,有:
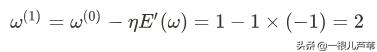
偏差为:

继续重复以上过程,直至:
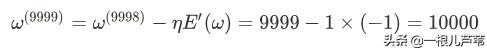
偏差为:
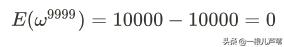
得到参数:
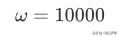
训练结束。
将训练得到的参数值:
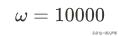
带入模型:
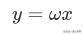
得到确定的模型:
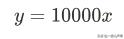
将:
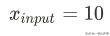
带入模型,得到预测值:
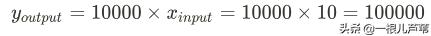
问题得解。
二、例子总结
通过上面的例子,对机器学习解决问题的过程算是有一个大致的了解。无非就是:
- 创建模型;
- 学习参数;
- 预测结果;
模型的创建要视具体的问题而定,不同的问题可能需要设计不同的模型。对模型的要求是对问题有足够的描述能力,也就是说能够反应训练数据输入输出的因果关系。
这就好比学开车,首先要确定你四肢是不是健全,眼睛是不是色盲。目的就是看你是不是具备操作方向盘、油门、离合以及分辨红绿灯的能力。只有这些能力都具备了,你才能驾驭开车这件事儿。
但是,能力只是前提条件,要想会做,还要学习。对于模型来说,就是调整参数,使训练数据的输入和输出一一对应。对于学车来说就是根据不同的路况,执行不同的驾驶动作。其本质也是输入输出相互对应。比如,遇到红灯,要踩刹车停车等待。红灯信号就是输入,踩刹车的动作就是输出。
所以,学习的实质就是建立因果关系。输入特定的因,输出对应的果。
那如何学习呢?和标准因果比对。
对于学车来说,红灯和刹车就是标准因果。看到红灯踩刹车就是正确操作。如果看到红灯你踩了油门,和标准不一致,那就错了。你需要反复比对、调整,直至正确的因果关系建立,学习也就完成了。
对于机器学习来说,训练数据就是标准因果。输入数据是标准因,输出数据是标准果。
学习的过程就是给模型输入标准因,拿输出跟标准果进行比对,如果不一致则调整参数,如此反复,直至和标准果相同或足够接近。
学习结束以后,参数固定下来,模型就具备了预测能力,能够用于处理类似的问题。就好比,一旦红灯和刹车在你脑海里建立了联系,不管是在北京还是上海,广州还是深圳,只要是红灯的场景,你都会采取同样的刹车动作,因为你已经具备了处理这类问题的能力。
学习好的机器模型也同样就具备了某种能力,可以自动的处理某一类问题。
三、梯度下降算法
前面举了只有一个参数的模型,主要用于说明机器学习的过程和原理。而在实际的应用中,参数通常会有很多。ω不再是一个单纯的数,而是一个多维的向量,输入输出也是。
此时的模型可以用:
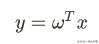
来表示。其中y、ω、x都是多维向量。
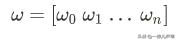
但不管模型如何复杂,参数如何多,学习的方法基本一样。都是通过预测值和标准值的偏差来调整参数。
偏差的大小跟参数ω有关,是ω的函数,如下:

参数虽然多,但不用害怕,我们采用分而治之的策略将其简化。
首先,假设只有一个参数,其它的保持不变。根据我们开头付出与收获的例子,可以得到参数调整如下:
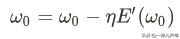
而其它参数不变,只对其中一个求导,又叫偏导,可以用下式表示:
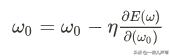
依次类推可以得到所有参数的调整策略:
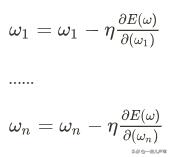
所有参数的偏导数放到一块儿:
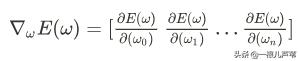
叫梯度,它指向损失函数上升最快的方向。
所以参数的调整策略就可以统一到一个公式表示:
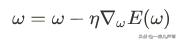
这就是梯度下降算法。
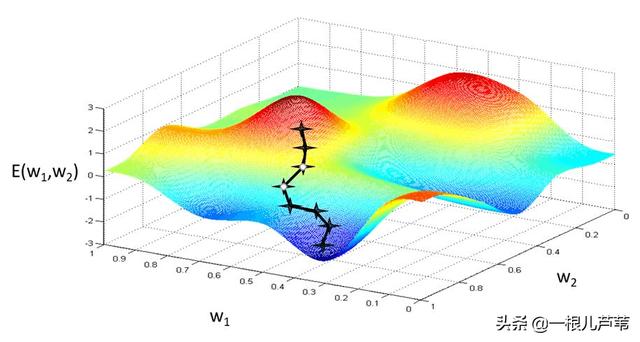
它的效果直观看起来是这样的:
四、反向传播算法
反向传播算法主要用于神经网络。神经网络没有什么神秘的,也无非就是众多学习模型中的一类。
但这类模型有一个特点,就是傻瓜化。基本上不用费太多的神思去设计模型,只需要根据问题的规模增删网络节点和层数,总能满足你的要求。
因为已经有人证明过,只要规模够大,神经网络基本可以拟合任何你可以想出来的函数。就像信号处理界的傅里叶变换。
但不好的是,参数特别多,学习起来比较耗时费力。
所以,你需要的就是大量的训练数据,加上强大的计算机处理能力。剩下的就可以交给时间。
好在现在的计算机处理能力有了大幅度的提升,互联网上的数据也呈爆炸式的增长,这也是当前神经网络比较有效的重要原因。
言归正传,继续反向传播算法。
前面说过,不管再复杂的系统,再多的参数。学习的根本大法不变,比较、调参,比较、调参,直到满意的结果为止。调参的策略就是梯度下降。神经网络也不例外。
那既然这样,反向传播算法又是个什么东东?
我们知道,梯度下降需要求偏导。这对简单的模型不算什么,可如果是成百上千层,有千万甚至上亿参数的神经网络呢?能计算得出来吗?即使能计算得出来,一个一个算,得算到什么时候?
反向传播算法算法解决的就是如何快速求偏导的问题。
本着复杂问题简单化的指导思想,举一个简单的例子。
有这么一个简单的神经网络:
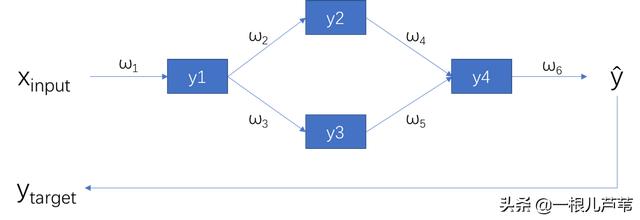
其中:

偏差:
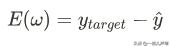
为了训练这个神经网络,得出各个ω参数的值,需要最小化这个偏差。可以采用梯度下降算法来做,如下:
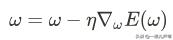
问题的关键是求偏差函数的梯度。也就是求各个参数的偏导数。首先看第一个参数:

一脸懵,不知道从何下手。
没关系,先从网络结构上理一下各个量之间的关系:
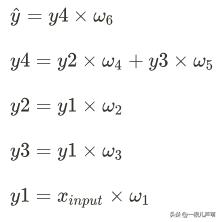
求偏导:
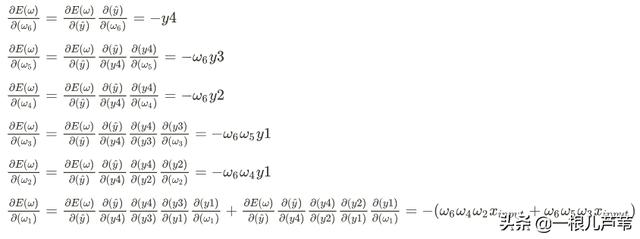
对比偏导结果和神经网络结构图,是不是发现了什么规律?
每个参数的偏导数只跟正向传播的输入和输出路径上的参数有关。如果由后往前看,偏导数好像是顺着路径在反向传播一样。
这样,对于一个神经网络,只要知道每个节点的正向传播输入,以及由后到前到达该节点的路径上的参数就可以得到该节点的参数的偏导数。
利用神经网络的这种规律计算梯度的算法就叫做反向传播算法。
所以,反向传播算法不是独立的优化算法,它要结合着梯度下降算法来用。是计算梯度下降的算法。
为什么参数的偏导数会有这种特点?
其实,结合神经网络的结构,就会发现其实不难理解。
偏导数的含义是,单个参数的变化对整体结果的影响。
由于整个神经网络的通路上的参数是相乘的关系。参数变化首先会作用于输入,然后沿着路径向后传播,每过一个节点都会被放大或缩小,放大或缩小的倍数是跟节点的参数有关的。所以最终反应到整体结果上就是输入和路径参数的连乘了。
五、题外
知道了反向传播和偏导数的特点,一些相关的术语也就很容易理解了。
比如,梯度消失和梯度爆炸。
如果神经网络的层数比较多,每一层上的参数都小于1,那么由反向传播算法可知,由后向前经过一些层以后,由于偏导是连乘的结果,就会导致前面一些层的偏导趋于0,参数得不到学习,到达不了理想的目标点。这就是梯度消失。
梯度爆炸正好相反,如果每一层的参数都大于1,连乘以后层层放大,导致偏导过大,从而跳过目标点。
不管是梯度消失还是梯度爆炸,对机器学习都是不利的。
这也是为什么目前的神经网络中,激活函Sigmoid被ReLU取代的原因。
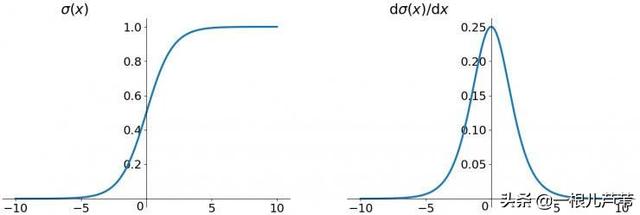
下图左侧是Sigmoid原函数,右侧是其导数。可以看出来,即使是最大值也才0.25,所以放到神经网络路径上极易造成梯度消失。
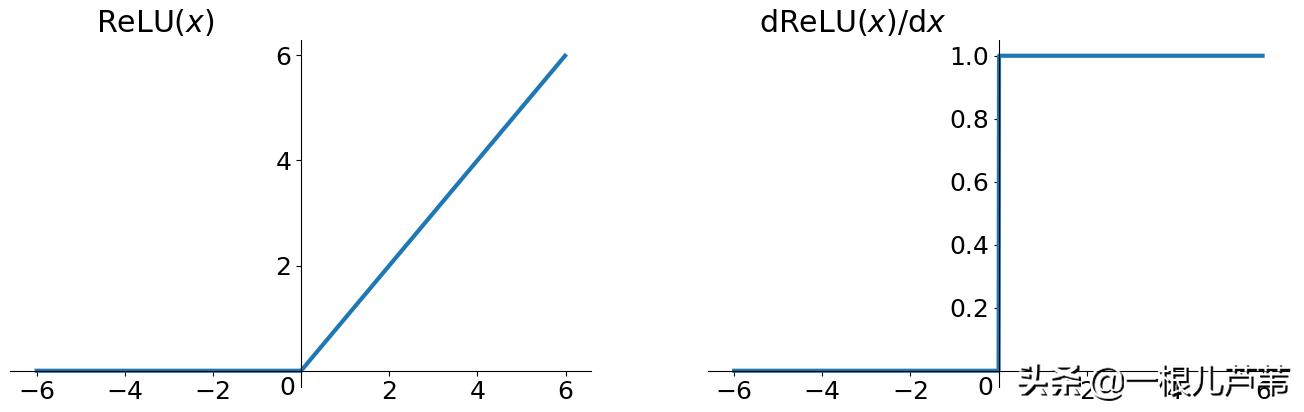
下图是ReLU函数,可以看出来,当函数值大于0时,其导数恒为1,连乘后也不会缩小或放大,有效的避免了梯度消失和爆炸。
学习率。
在我们的参数调整策略公式中:
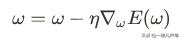
参数η就叫学习率。
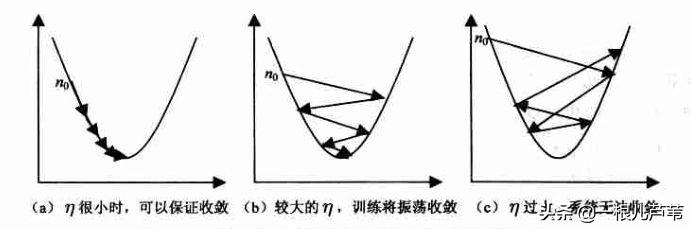
学习率的大小对学习过程的影响很大。如果设的太小就会导致学习速度太慢,加长学习时间。如果设的太大,导致震荡,或发散,影响最终效果。
(本文部分图片来自于网络,如有侵权请联系作者删除)














 7710
7710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









