






本文将介绍如何为机器学习算法增加正则化来提高算法的准确性。我们会梳理线性回归中的正则化案例进行讨论,来看看不同数量的正则化是如何影响准确性的。

欠拟合和过拟合
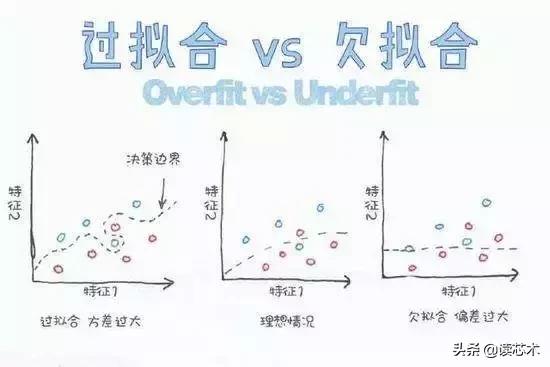
当涉及机器学习算法时,往往会面临过拟合和欠拟合的问题。欠拟合算法意味着对算法简化过多,以至于很难映射到数据上;过拟合则意味着算法过于复杂,它完美地适应了训练数据,但是很难普及。
欠拟合和过拟合的例子如下所示。欠拟合算法用黑线显示,过拟合算法用蓝线显示。
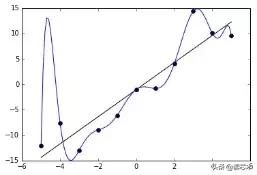
要解决算法欠拟合的问题,你通常可以添加更多其他功能,或者使你的功能更高,以更好地匹配数据。
另一方面,为了防止过度拟合,可以减少功能的数量或使用正则化。删除功能可能很困难,因为要清楚地知道删除哪些功能并不简单。另一方面,调整算法可以轻松地将正则化应用于问题中。
正则化
正则化的核心是减小算法中某些θ参数的大小。将其视为阻尼器,可以抑制算法中不太有用的功能,从而减少过度拟合数据的可能性。当数据集中有许多稍微有用的功能时,正则化最有效。稍微有用的意思是它们与输出变量的相关性较低。
为了理解正则化如何运作,我们将正则化应用于下面的线性回归中。如果你对细节不感兴趣,可以跳转到案例部分,了解它对实际算法的影响。
为了将正则化应用于线性回归,我们在成本和梯度函数中引入了一个附加项。
线性回归的常规成本函数如下所示:
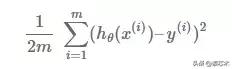
这是平方误差均值的一半。
为了应用正则化,我们引入了一个由参数λ控制的新项:
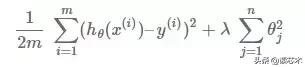
类似地,因为梯度函数是成本函数的偏导数,所以这也改变了梯度函数。现在是具有正则化的梯度函数:
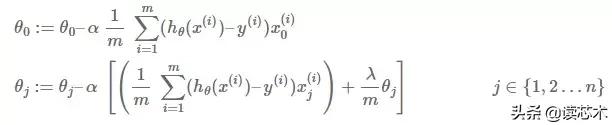
现在,由于梯度函数是用来训练算法到最佳可能θ值的方法,我们可以研究新的梯度函数来理解正则化的作用。
· 对于θ0来讲,并没有影响——渐变函数没有偏移。
· 对于θj来讲,这是针对每个特征术语,我们引入了λ术语。这将有助于抑制数据集中不太有用的功能。
如你所见,新参数λ控制正则化的幅度。λ的最佳值因问题而异。一些机器学习库将包括为问题和训练集自动找到λ的最佳值的功能。
案例
为了测试正则化,可以用公式收集一些数据集:
y=sin(x)∗x
在XY图上绘制训练数据如下所示:
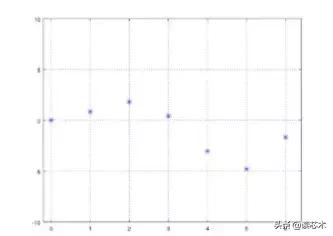
训练数据
我们现在将使用线性回归来找到最能模拟函数的函数。从训练数据中可以很明显地看出来,直线不会很好地模仿函数。因此,我将不得不使用更高阶的多项式。为此,我将给予线性回归算法的输入功能从仅仅为[X]更改为以下一组功能:
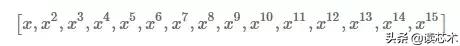
这实质上意味着线性回归将找到能够适应训练数据的15度多项式。 这应该为算法留出足够的空间来模拟正弦函数的变化,但也让我们开放过度拟合解决方案的算法。
首先,我们尝试在不使用正则化的情况下训练算法并绘制结果函数。
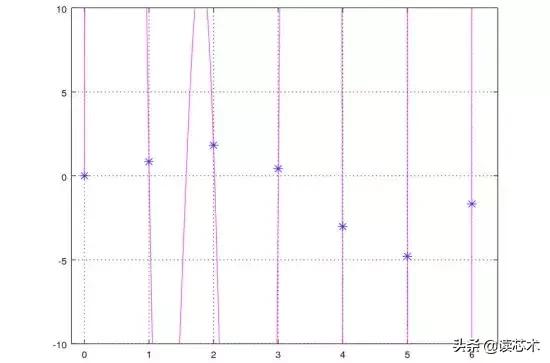
不正则化 – λ = 0
没有正则化,我们可以看到我们发现了能够完美适应训练数据的算法,但是这类算法不能很好地概括解决方案。对于任何没有存在于训练集中的数据而言,这会给我们完全错误的结果。
此时,我们可以尝试从训练集中手动删除输入要素以获得更好的结果,或者我们可以使用正则化以使正则化算法将不需要的要素影响最小化。在我们的例子中,我们尝试应用正则化。
考虑到这一点,我们尝试将λ设置为5并重新运行训练。
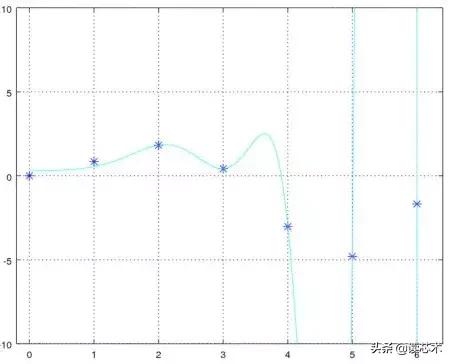
运用正则化 – λ=5
将λ设置为5,我们可以看到所得函数在开过解决方案方面要好得多。对于0
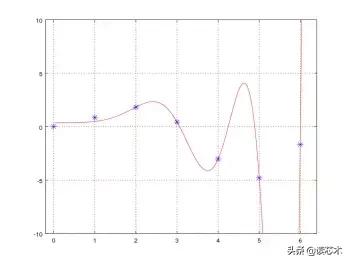
运用正则化 – λ=13
将λ设置为13,我们发现算在概括问题的解决方案方面更加有效。但是,它在训练集的上限方面表现仍不完美。虽然不完美,但模型仍然是没有任何正则化的改进,这显然只是一个例子,在现实生活中我们可能已经使用特征消除和正则化的组合来获得更好的结果。
这个例子展示了如何应用正则化改善机器学习模型。然而,找到最佳λ值可能是一个挑战。拥有能够可视化的一维或者二维数据使其更容易一些。如果没有可视化数据的选项,建议使用可靠的测试数据集来计算算法丢失或错误。从那里你可以尝试许多不同的λ值来找到具有最低误差的λ值。如果选择此方法,请记住测试数据集必须与训练数据不同 ——这是你可以测试算法的一般化并避免过度拟合模型的唯一方法。















 971
971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









