






1. 介绍
在线RL智能体根据观察到的经验递增式地更新参数。在最简单的形式下,智能体会在更新后立刻丢弃数据。这里有两个问题:第一个是强相关性的数据打破了随机梯度算法所要求的i.i.d.假设;第二个是会丢弃将来可能有用的经验。
经验回放解决了这两个问题:经验储存在一个回放内存中,通过混合最近的经验来减少时间相关性,同时那些西游的经验会被重复更新。DQN就使用了经验回放来稳定值函数的训练。一般来说,经验回放可以有效减少学习所需的经验数量。
本文,作者提出了优先方法来使经验回放更加高效。核心思想是RL智能体可以从某些经验中更高效地学习。具体地,作者提出了更多地采样高期望值的经验,通过TD误差来衡量。这样的优先法会导致多样性的损失,作者采用随机优先化的方法来减少损失;还会引入误差,作者通过重要性采样来修正。
2. 背景
大量神经科学的研究表明优先经验是更多被重复的。与奖励有关的序列会被重复地更加频繁。高TD误差的经验也经常被重复。规划算法如值迭代可以通过适当顺序优先更新来提高效率。Prioritized sweeping根据值的改变来选择对哪个状态进行更新。TD误差则提供了一个方法来衡量这些性质。TD误差还可以觉得关注哪些资源,比如选择探索方向或特征。
在监督学习中,有很多技术可以解决不平衡数据集的问题,如重采样、下采样、过采样等,还可能与ensemble的方法结合。有研究将经验分为正负奖励两个buck进行固定比例地采样,这种方法只对可以分为正负经验地经验有效。有文章基于误差引入了非均匀采样,通过重要性采样来修正。
3. 优先回放
3.1 例子
为了理解优先化的潜在受益,作者引入了一个人为的实例环境”Blind Cliffwalk“,它的奖励是非常稀疏的。对于n个状态,环境需要指数级别的随机步来得到第一个非零奖励。
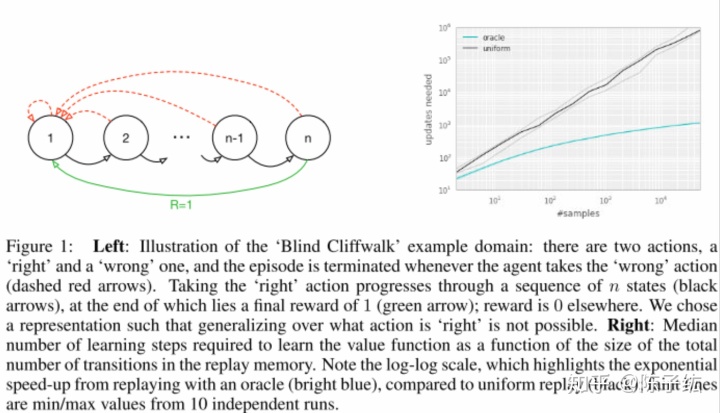
作者使用这个例子来说明两个智能体的学习差异。两个智能体都采用Q-learning从相同的回放内存中更新。第一个智能体随机均匀采样,第二智能体使用一个数据结构优先采样。这个数据结构贪婪选取可以最大程度减小损失的数据。图1右体现了这种方法的加速效果。
3.2 TD误差优先化
优先回放的核心原则就是对每个状态转移重要性的衡量。一个理想的方式是智能体在当前状态所能学习的转移数量。当这种方法不可行时,我们就可以采用TD误差来代替。
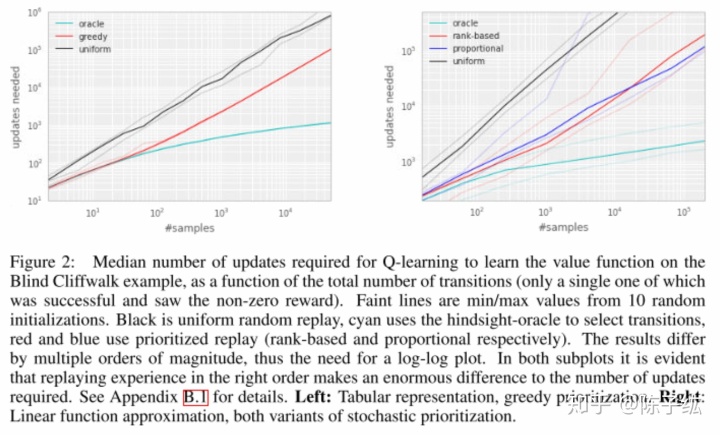
为了阐述用TD误差衡量优先性的效果,作者对比了均与和基于数据结构的贪婪TD误差优先算法。算法将遇到的所有TD误差都储存在replay buffer中。有最大TD误差的转移被重复。参数根据TD误差的比例进行更新。新的转移无法计算TD误差,作者而将他们放在最优先的顺序来保证所有经验都至少被见过一次。图2左显示这个算法可以有效减少学习时间。
3.3 随机优先化
贪婪TD误差优先化有以下几个问题。第一,为了避免昂贵的扫描成本,只有回放的经验才跟新TD误差。这样就导致TD误差一开始就小的状态很长时间不会被访问。第二,算法对噪声很敏感。第三,贪婪优先关注于经验的子集,这就导致了一开始TD误差高的转移会更频繁被重复,导致过拟合。
为了解决这些问题,作者引入了随机采样方法,结合纯贪婪优先化和均匀随机采样。作者保证在一个转移优先中采样的概率是单一的,对低优先值的转移概率也是非零的。具体的,转移i的采样概率为:
其中
作者考虑的第一个情况就是比例优先化,其中
实施:为了从分布中高效采样,复杂度不能依赖于N。对排序方法,我们可以用k个分段线性函数来拟合密度函数。分割点可以被预先计算(仅根据N和alpha改变)。在运行时,我们采样一个部分,然后在其中进行均匀采样。这个方法对小批次的算法很有效:选择k为批次量,然后从每个部分采样一个转移,这是一个分层采样的形式,可以平衡批次。比例方法则不同,它根据累加树的数据结构来实现。
3.4 偏差退火
优先回放引入了偏差,因为它改变了数据分布,改变了期望值。作者通过重要性采样的方法来修正权重:
当beta=1时,非均匀概率被完全弥补。通过使用
典型的RL常见情景中,更新的无偏差性在训练末期收敛时最重要。作者假设在这种情境下小的误差可以忽略。因此作者利用重要性采样退火,在训练终止时beta=1,实际中线性退火至1。beta与alpha具有交互效应,同时增加两个参数会增加优先性。
重要性采样在非线性拟合下还有一个优点:大的步长会导致梯度过于陡峭,因此一般会采用小的步长。在本方法中,优先性保证了高误差的情况被智能体见过很多次,重要性采样减少了梯度的数量级。
作者将该方法与doubleDQN结合,算法如下:
















 5519
5519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









