





短文本关键短语/关键词提取
背景:短文本具有内容简短、表达灵活、主题风格各异等特点,从中提取关键短语具有挑战性
1 类目 标签 关键短语 关键词的区别
类目(category) 是预先定义好的,具有树形的层次结构,抽象的概括某类事物,强调共性,往往具有排他性。
标签tag 粒度比类目更加细,用于刻画一小批群体的特征,不一定有层次结构,一条内容往往可以有多个标签。
关键词(keyword)更侧重于某一具体内容本身表达的意义,往往是内容的主题。
关键短语(keyphrase)是关键词组成的短语,短语的语义更加丰富,能够更加全面的概括内容主题。

2 可能的特征
特征选取往往对提取效果起到关键的作用。
统计特征 tf idf
位置特征 首次出现的位置、是否在title中、词的跨度(第一次和最后一次出现的间隔宽度)
语言特征 词性、停用词、形态特征(后缀、首字母缩写)、词干特征、偏旁、语义
语境特征 上下文特征
先验知识 比如 核心商品词、地名、书名、电影名等。
3 方法概览
无监督方法
- 统计 根据2提到的特征,通过分析设置权重和阈值进行排序,选出关键短语
- 基于图的思想 构造短语和短语之间的联通权重图,根据pagerank的思路得到短语的排序,选出关键短语
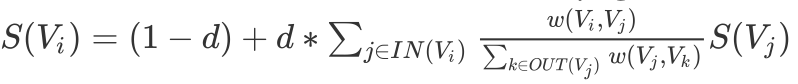
- 基于文本滑动窗口的 textrank Mihalcea and Tarau (2004) )
- 基于term frequencies、tfidf、co-occurrences等算权重的 SGrank Papagiannopoulou and Tsoumakas (2015)
- 基于文档相似的 singlerank Wan and Xiao, 2008
- 根据主题相似 topic pageranke Liu et al., 2013
监督方法
- 统计机器学习分类方法 根据3提到的特征,用统计机器学习学习各个特征的权重值,为每个短语做是否是关键短语的二分类。比如比较古老的 KEA KEA (Witten et al.,也可以用gbdt等其他分类方法。
- learn to rank LTR 目标是学习一个排序模型,使得排在前面的都是关键短语。Ranking SVM Jiang et al .MIKE Zhang et al., 2017.
- 翻译的思想 可以把文本看作源语言,把关键短语看作目标语言,用encoder-decoder思路做提取 Deep Keyphrase Generation Meng 2017
- 序列标注的思路 把每个字做序列标注分类,类似实体识别的思路,实体识别提取的是实体词,这里提取的是关键短语。是否是关键短语除了短语本身的特征外,往往上下文的特征更为重要,比如主语宾语成分是关键短语的概率大于其他成分。 CRF - Incorporating Expert Knowledge into Keyphrase Extraction Gollapalli et al. 2017 Bi-LSTM-CRF Rabah et al 2019
4 离线评估方法
1 关键短语的F1 score.
2 排名质量衡量MAP MRR
3 binary preference measure(bpref)
4 Average of Correctly Extracted Keyphrases - (ACEK)
5 我们尝试的方法
无监督方法
在最开始无训练语料的情况下,我们把ugc文本切词后,每个词构造相应的特征做规则排序(属于关键词提取)。这里的特征包括词本身的特征,词所在的文本内容特征,还包括内容发表者的特征。
词的内容中首次出现位置
词性(是否是名词形容词等)
停用词(直接去掉停用词)
tf-idf值
text-rank值
词是否在用户设置的内容话题中(##里面的内容)
词的长度
ugc文本长度
词和ugc文本的语义相似度.
词的簇和内容中其他词的簇分布情况(根据词embedding做聚类,得到每个词的簇类别)
词是否在feed发表者的简介描述中
词和发表者简介的语义相似度
等等...统计机器学习做分类(GBDT/XGboost)
使用无监督方法时,构造的特征越多,用规则越显得拙荆见肘,于是采用了统计分类的思路。对比了gbdt和xgboost,效果非常接近,spark ml集成了gbdt的方法,在Tesla上能够方便的例行化。
优点:
1 免去人工去设定那些繁杂而又捉襟见肘的规则
2 发现的时关键词共性的特征,需要训练的数据少
3 特征往往是交叉的
缺点:
1 只是根据所有标签词的总体位置、tfidf等特征来判断,特征粒度太粗,太过共性,而feed短文的表示复杂,关键词提取比较复杂,普适性不是那么强。
2 没有强语义序列特征,只用到简单的cos相似的特征,不够深
3 依赖先验知识,导致pipline 精度损失。比如切词错误、词性错误、停用词错误等
4 同一个feed中,每个词做独立二分类,实际上,词之间是否是关键词不是相互独立的。
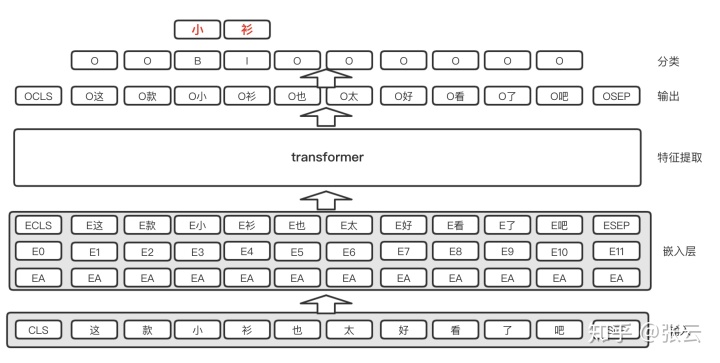
BERT 序列标注
针对上述提到的统计机器学习特征的缺点,我们采用了bert做fine-tune提取关键短语的方法。 1 Bert训练的任务之一是从语料中随机 mask token 做预测,能够通过self-attention 学习到句子中词和词的相关性,这一点挺适合于提标签词,因为标签词往往是句子中的关键词,除了词本身的特征外,句子中的其他词也会一起决定是否是关键词。 2 bert做fine-tune,大大减少训练样本。
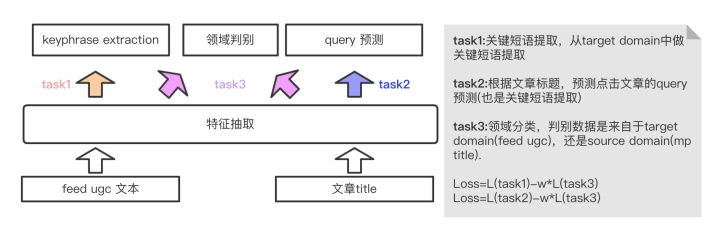
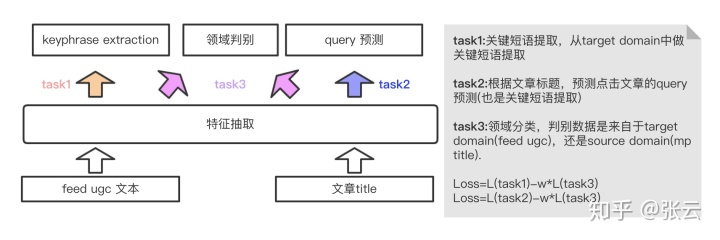
改进1 多任务学习+对抗学习
我们拿搜索点击的文章的头部query做关键短语,点击的文章title做输入内容,因为我们的目标是提取feed里面的ugc文本关键短语,相当于短文本主题。而点击文章的头部query往往是文章title的主题,因为用户在搜索时是带有强烈需求目的的,往往头脑中想到的query短语是主题核心短语。所以我们采用多目标学习,如下图的task1和task2,底层特征抽取共享参数,上层分别做关键短语抽取和query词预测,跟图像处理类似,文本特征底层往往抽取语言模型中共性的部分,通过底层知识共享来加强模型泛化能力。
文章标题和视频feed ugc文本存在差异,数据分布不同,视频内容更侧重于图文结合的方式,内容相对发散,核心短语数据平均到1.5个。文章标题主题更加集中,高度概括长文的主题,平均只有一个关键短语。基于此,我们引入对抗学习的机制,引入领域识别分类任务,如下图的task3,此模块主要是用来判别数据是来自source domain还是target domain。然后对梯度作反向,使得分类尽可能的随机,这样做的目的是为了让领域判别模块抽取的特征尽可能的往source domain和target domain共性特征靠拢。只有抽取的是共性特征,判别模型才判别不出数据来自哪个领域,为此,可以把判别模型抽取到的共性特征共享到关键短语抽取的任务中。这里的损失函数是关键短语抽取的损失函数和领域判别的反向损失按照一定的权重加和作为模型的损失。
改进2 加入crf和词先验知识
因为我们采用的是字作序列标注,可能会造成短语边界划分错误的问题,比如王者荣耀,分类可能会把耀字分错,最终提取出王者荣。我们的改进是加入crf和词先验知识。 在最后输出时加入crf层,主要是为了统计字类别转移概率,比如如果上一个字是关键短语的开头时,下一个字是关键短语的概率远大于非关键短语。 另外,我们融合词先验知识,词是表达语义的最小单元,每个字的特征如果能够融合它所在的词的信息,对字的类别判定是很有意义的,为此我们在bert输入的时候,加入字在词中的偏移特征,让模型学习字和词的关系,如下图的橙色部分。另外在输出时,采用attention的思想,学习出字和词中其他字的关联权重,作为词的权重,再把词的向量信息叠加到字的向量中。如下图的蓝色部分。

6 结语
本文介绍的关键短语提取可以用于ugc短文本提取,基于bert输出加一层全连接做字的分类,就能取得一个很不错的baseline,而且除了bert微调,训练的参数很少,少量样本就能训练得到不错的效果。 由于本人能力有限,如果存在错误,欢迎各位指出。
附录
附一张模型预测结果
















 1574
1574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









