







声明:
本文旨在介绍TF-IDF算法的简单应用。作者本人编程小白,如有错误,欢迎各路大佬指正。
jieba库的介绍:
中文名“结巴”,一个擅长有对中文文本进行分词、关键词提取、词性标注等功能的第三方python库。在NLP领域具有一定的应用。
jieba库的安装:
清华镜像源快速安装:
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
预备知识:
此部分非源码,仅添加一些辅助理解的知识。
TF-IDF算法原理:
此部分可参考文章:NLP:TF-IDF算法-CSDN博客
也是我写的,哈哈,一下给你讲明白。
文本清洗:
文本清洗几乎是文本处理之前必不可少的一部分吧,不论是对文本进行分词,还是提取关键词等任务,都需要先进行文本清洗。这么做可以提高模型处理效果,减少计算量,匹配模型输入等等。
文本清洗的一般要求:
去除标点等其他无关符号、去除停用词、格式统一(比如有时候需要将英文文本全部转为小写之类)等等。
停用词的概念:
停用词简单理解起来就是:在无论何种文章中,几乎都会出现的词,例如“的”,“你”,“他”,“是”之类这些词语。一般认为,这些词语均不会是关键词。所以在关键词提取的任务中,往往会在文本清洗阶段去除停用词。
正则化表示:
正则化表示可以简单理解为:用来筛选文本,匹配需要的内容的。
比如我想提取出一个文本中的电话号码、去除文本中的所有标点之类的都可以。
正则化表示,是文本清洗的主要手段之一。
举例:
import re
# 正则表达式匹配中国的手机号码
phone_pattern = r'1[3956789]\d{9}'# 中国的手机号码是有一定的规范的,在正则化表达式的写法上需要按规则来写
# [3956789] 表示从中任意选择一个数组
# \d{9} 表示匹配数字,匹配九个数字
# 示例文本
text = "我的手机号码是1313512345678,他的电话号码是15720987973,小刘的号码是:13787678352,欢迎联系我。"
# 使用正则表达式搜索手机号码
matches = re.findall(phone_pattern, text)
# 输出匹配的结果
print(matches)运行结果:

完整源码:
代码中已经做了详细说明。
文本内容是从网页选取的一段,大家可以先不看文本内容,根据最后关键词的提取结果先猜一下文本内容,最后在看文本是什么,来衡量一下这种算法的关键词提取效果。
import pprint
import jieba
import re
# 示例文本
text = "华为,在历经一系列挑战与困境后,不仅稳住了阵脚,更在多个技术领域取得了显著突破。特别是在自研技术方面,华为展现出了卓越的实力" \
"与决心 ,持续推动国产化进程,展现出了令人瞩目的创新活力。在华为的不懈努力下,其营收稳步回升并实现持续增长,智能手机业务也实现了国产率高达90%的突破。\
Mate60系列的成功推出和热销,不仅证明了华为在手机市场的强大竞争力,更彰显了其技术实力的显著提升。\
随着华为重启一年双旗舰模式,其手机出货量也呈现出迅猛增长的态势,迅速登顶国内手机出货量榜首,展现了其强大的市场号召力。\
近日,华为P70的上市销售再次引发了业界和消费者的广泛关注。这款新品不仅搭载了华为自研的新一代麒麟9010芯片,\
还融入了诸多前沿技术,展现了华为在技术创新方面的领先地位。麒麟9010作为华为自研的一款处理器,在性能、功耗和设计方面均达到了业界领先水平。\
它采用了先进的多核心设计,能够根据不同的使用场景灵活切换性能模式,既满足了高性能需求,又保证了续航时间和温度控制。在Geekbench\
6测试中,麒麟9010的单核得分令人瞩目,其性能表现甚至接近或追平了市场上主流的处理器,充分展示了华为在处理器技术方面的强大实力。\
与前代产品麒麟9000S相比,麒麟9010在单核性能上实现了显著提升。其IPC值的提升意味着执行效率更高、单线程处理能力更强。同时,\
麒麟9010在保持较低运行频率的情况下仍能展现出优于麒麟9000S的性能,这充分证明了华为在处理器架构设计上的深厚积累和创新能力。\
当然,与市场上的其他旗舰处理器如高通骁龙8+和骁龙8Gen2相比,麒麟9010同样具有不俗的竞争力。虽然在实际性能上可能存在一定的差异,\
但麒麟9010在功耗控制和高效能设计上具有明显优势。这使得它在满足用户日常需求的同时,能够提供更长时间的使用和更好的用户体验。\
除了处理器性能的提升外,华为P70还凭借其独特的设计和功能吸引了众多消费者的目光。其创新的可伸缩摄像头设计不仅提升了拍摄的趣味性和便利性,\
更展现了华为在摄影技术方面的领先地位。这也进一步提升了华为P70的市场竞争力,使其在众多手机产品中脱颖而出。"
def clean_text(text): # 两种正则化的写法
pattern = r'[\u4e00-\u9fa5a-zA-Z0-9]+' #只保留汉字、字母、数字的含义,后面的+号是可以迭代多次的一次
extracted_text = re.findall(pattern, text) #通过这样的方法会得到一个字符串列表,因为一旦出现了标点符号,其实就匹配截止了
#所以在最终的表现形式上,是多个字符串组成的一个列表
cleaned_text = ''.join(extracted_text) #对上一步得到的字符串列表进一步处理,将这些分开的字符串拼接起来,join()
return cleaned_text
def clean_text2(test):
pattern = r'[^\w\s]' #^是取反的意思,即与后面的条件不相符的情况
# \w 匹配任何字母、数字或下划线,就相当于[a-zA-Z0-9_]
# \s 匹配任何空白字符,空格、制表符等。
cleaned_text = re.sub(pattern,'',text) # 使用re.sub()函数替换标点符号为空字符串,不过这种写法处理后的文本中会出现空格的情况
return cleaned_text
cleaned_text = clean_text2(text)
# print(cleaned_text)
# 使用jieba进行分词
words = jieba.cut(cleaned_text,cut_all = False) #使用jieba分词后,返回结果是一个生成器类型,无法直接看到分词的结果,需要将其转化成列表的
# 形式或者用for循环来查看分词结果。用generator类型,能够节省内存,用完立马就释放了,不会像存储在一个变量中一样。
words_list = list(words) #分词结果
# pprint.pprint(words_list) #通过这里才可以看到分词的结果
#去除停用词
stop_word = set(["的","和","是","这","华为","在"])#这里的set是一种数据结构,不采用list的形式是因为其较于列表有这样的优势:
#自动去重、查找速度较快(因为后面得对分词进行判断,是否为停用词)
'''
这里是设定停用词
停用词一般是"的",“是”这类在几乎每一篇文章中都会出现的词语
一般认为,这些词都不作为文章的关键词
后续利用TF-IDF算法计算时,往往会优先排除停用词
'''
#错误写法
# for word in words_list: #导致错误的原因是在不断删除列表中数据时,会改变列表的结构,导致遍历出现问题
# if word in stop_word:
# words_list.remove(word)
# pprint.pprint(words_list)
#正确写法
final_list = [] #创建新的列表,存储不存在于停用词列表中的元素,或者采用列表推导式,但是不好理解
for word in words_list:
if word not in stop_word:
final_list.append(word)
# pprint.pprint(final_list)
# 列表推导式 words_list = [word for word in words_list if word not in stop_word]
#使用TF-IDF算法提取关键词
from sklearn.feature_extraction.text import TfidfVectorizer
# 将 final_words 转换为字符串格式,因为 TfidfVectorizer 需要文本格式的输入
texts = [" ".join(word for word in doc) for doc in [final_list]]
# print(texts)
# exit()
# 使用 TfidfVectorizer 计算 TF-IDF
vectorizer = TfidfVectorizer() #实例化一个TF-IDF计算器
tfidf_matrix = vectorizer.fit_transform(texts) #调用上面的TF-IDF计算器计算
# 查看矩阵部分信息
# print(tfidf_matrix[:10, :20]) # 打印矩阵前20行信息
'''
部分显示结果:
这里第一列应该指的是第几篇文档,但由于这里只输入了一篇,所以都是0;
第二列是每个词对应的一个下标吧;
第三行就是对应词语的TF-IDF值
(0, 8) 0.03829197905337418
(0, 14) 0.03829197905337418
(0, 0) 0.03829197905337418
(0, 5) 0.03829197905337418
'''
# exit()
# 获取词语的TF-IDF分数
feature_names = vectorizer.get_feature_names_out()
scores = tfidf_matrix.toarray().sum(axis=0)
# print(feature_names[0:10])
# print(scores[0:10])
# exit()
# print(type(zip(feature_names, scores)))
'''
是zip类型(一种迭代器,和generator类型有点像,好处是不用变量存储空数据吧,
用的时候才会需要更多空间,这样做能节省空间。)的数据,不能直接打印
'''
# print(list(zip(feature_names, scores))[0:10])#得转化成列表才能显示
# exit()
# 将词语和对应的TF-IDF分数组合
tfidf_items = sorted(zip(feature_names, scores), key=lambda x: x[1], reverse=True)
#这里zip会将feature_names和scores组合成一个元组,然后排序时按照元组[1],也就是第二个元素(即TFIDF)的大小进行排序
# 提取分数最高的关键词
keywords = tfidf_items[:10] # 假设我们提取分数最高的10个关键词
pprint.pprint(keywords)
运行结果:
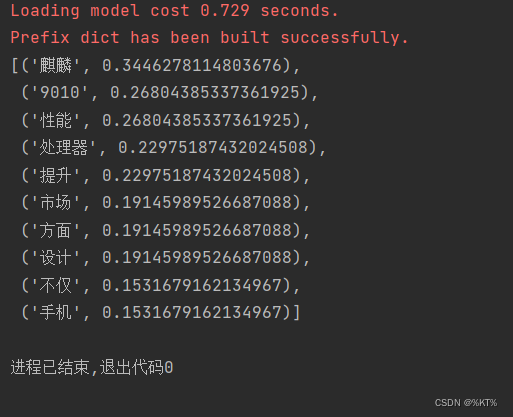
结果分析:
从提取出的关键词来看,我们大概可以猜测这一篇文章是在分析:华为的麒麟芯片的性能、市场反响等。这和真实文本论述的内容大体上是一致的。















 3067
3067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









