







在机器学习中,模型的训练过程与数据可视化是紧密相关的。模型的产出基于训练数据样本,模型的评估又基于测试数据样本。而数据样本的可视化,不论是对原始样本的加工还是对模型训练过程的调参都至关重要,是算法同学不可或缺的工具。
本文将以 Kaggle 上房价预测和经典的德国评分卡两个问题为引导,为大家介绍蚂蚁内部机器学习平台上的数据可视化能力。
数据预处理
机器学习的目的是通过上线模型进行预测来解决实质性的问题。模型最终的上线效果,除了训练时对应的参数设定,其所依赖的数据样本同样起到了决定性的作用。
在模型训练前,通常需要对数据样本进行优化,包括处理异常值来提高整个样本的质量、寻找优质的入模特征来提高训练和预测效率等等。
缺失值与异常值处理
我们并不希望一些异常的样本值将整个模型的效果拉垮(一只老鼠毁了一锅汤),训练前的异常值处理就显得尤为重要。
除了传统意义上的缺失值(Null,空字符)、错误信息(age 列中竟然混入了负数)等,像是样本中的离群值(age 列中大于 800 的值,是不是把老鳖的信息录入了。。)是更值得关注的异常值信息。
缺失值
缺失值的出现意味着样本的大小会缩减,从而影响后续的模型训练效果。而在对缺失值进行处理的过程中,还需要保证处理流程不会导致结果的偏差(矫枉过正)。
这一缺失数据的普遍性如何?
缺失数据是随机的还是有律可循?
以房价预测问题[1](一下简称房价问题)为例,我们在 Kaggle 上拿到的数据样本大致长这样(1460 * 81 的大小):
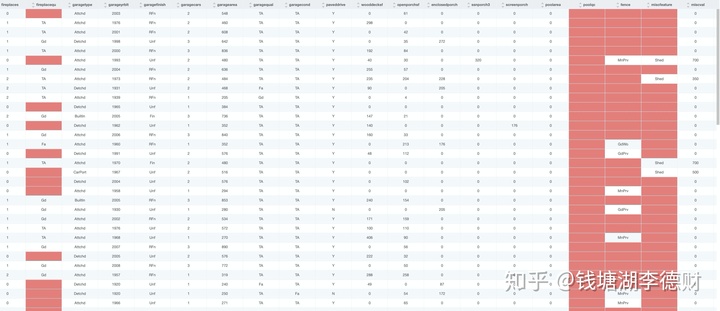
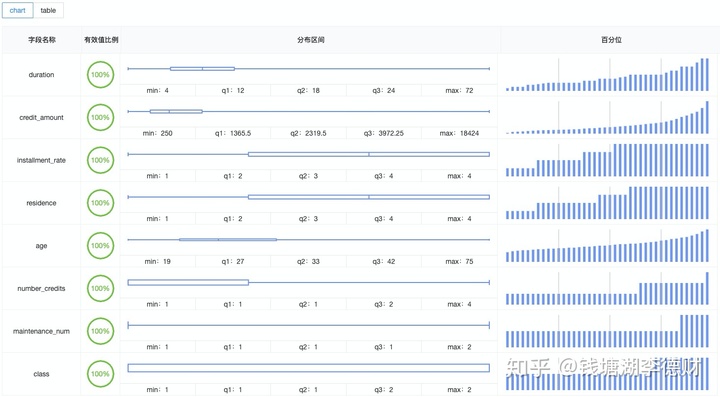
通过平台的全表统计功能,可以大致了解到整个数据样本的分布画像:

可以看到样本中 poolqc、lotfrontage、fireplacequ 等列或多或少都存在一些缺失值。对于这些缺失值,需要使用不同的方式进行处理。
对于缺失值比例超过 15% 的数据样本,理论上可以直接删除该特征列。对此我们直接移除 poolqc(Pool quality),miscfeature(Miscellaneous feature not covered in other categories),alley(Type of alley access) 等列,这些特征同样也不是我们买房时会考虑的因素。
而关于车库相关的特征(garagetype、garageyrblt、garageyrblt 等)占据了一定的缺失值比例,其最重要的信息都可以由 GarageCars(Size of garage in car capacity)来表达。于是我们删除所有类似特征并只保留 GarageCars。
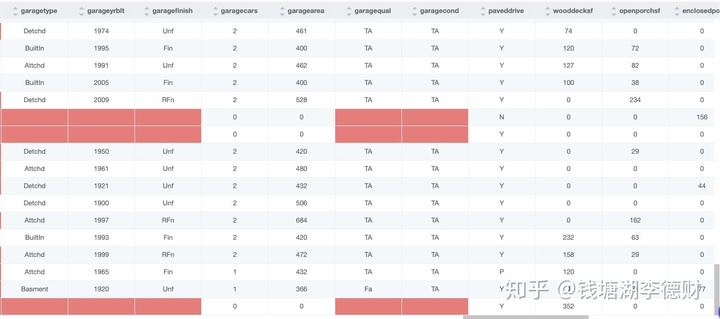
像是 saletype、mszoning(The general zoning classification)、electrical(Electrical system) 这种缺失率较小的离散型的变量,我们使用众数来进行填充。同时对于 lotfrontage(Linear feet of street connected to property) 这种连续性变量,考虑到房屋的每条街道距离与其附近的其他房屋相似,我们使用按照 neighborhood(Physical locations within Ames city limits)分组后每组内的中位数进行填充。最后,针对所有的未特别指定的字段,用“合法的空值”进行填充,即:数值型样本中的 Null 或空替换为 “0”,字符型样本中的 Null 或空替换为 “None”。
整个过程的流程编排为:

填充后的样本集:

异常值
继续以上述房价预测问题为例。
grlivarea(Above grade (ground) living area square feet)与 saleprice (the property's sale price in dollars)的散点图
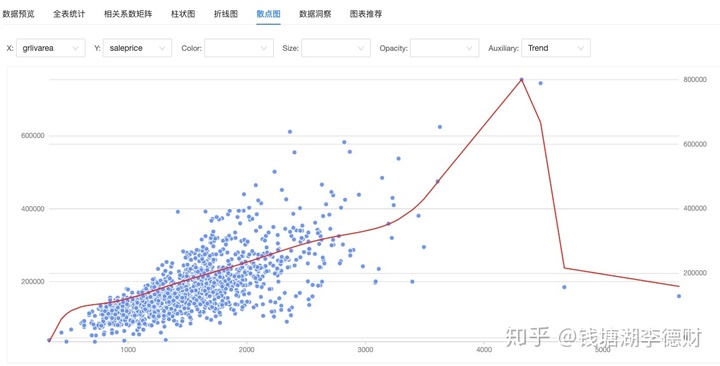
建模可视化平台的散点图融合了智能辅助的功能,例如帮助我们在样本分布中绘制出拟合曲线。在 grlivarea 与 saleprice 的散点图中,可以看到当 grlivarea 大于 4500 时有两条“异常记录”明显偏离了原本的拟合线。面积越大价格反而越低,这显然不合理,干掉就完事了。
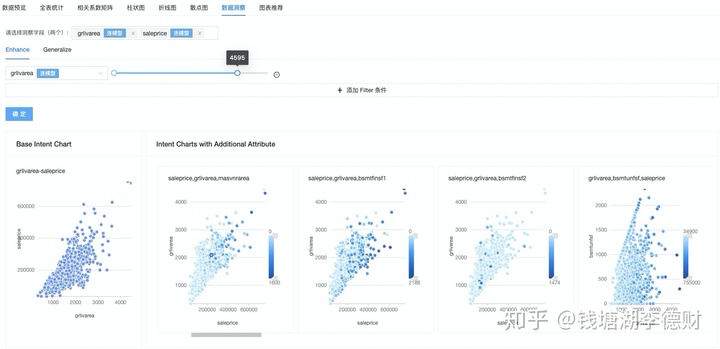
而在建模平台的数据洞查功能中,可以通过指定 grlivarea 与 saleprice 两个列来展示其在样本中与其他列之间的关系,同时可以添加筛选条件对样本进行实时裁剪和探查。指定 grlivarea 的筛选范围后,我们得以对异常值快速处理并对剩余样本进行洞察。
数据洞察和特征选择
经过以上操作,我们已经得到了一个比较理想的房价预测样本。那么回到房价预测问题的本质:我们使用已有样本训练出一个模型,通过该模型来进行房价预测。其本身是一个回归问题。
问题对焦与样本分析
在我们的样本中,saleprice 字段是我们需要预测的列,是目标列(或叫标签列,通常在机器学习中以 label 或 target 来表示);而其他数据列统称为标签列。我们需要对数据样本进行洞察,查看每个特征对目标列的重要性,分析其之间的关系。
就房价预测本身而言,我们会主观的考虑:
- 这个特征在买房子时会考虑么?
- 对于房价来说这个特征的权重如何?
- 这个特征与其他特征是否具有相关性?
由此,我们挑选对房价至关重要的四个特征来进行分析:
grlivarea - Above grade (ground) living area square feet totalbsmtsf - Total square feet of basement area overallqual - Overall material and finish quality yearbuilt - Original construction date
grlivarea 与 saleprice 的关系上文已有涉及,此处不再赘述。在散点图中两者基本成线性关系。
来看看其他几个特征与目标间的关系。

通过散点图可以看出 totalbsmtsf 与 saleprice 的关系很密切,除部分异常值外基本成指数分布。但从最左侧的分布可以看出当 totalbsmtsf 为 0 时对 saleprice 没有影响。
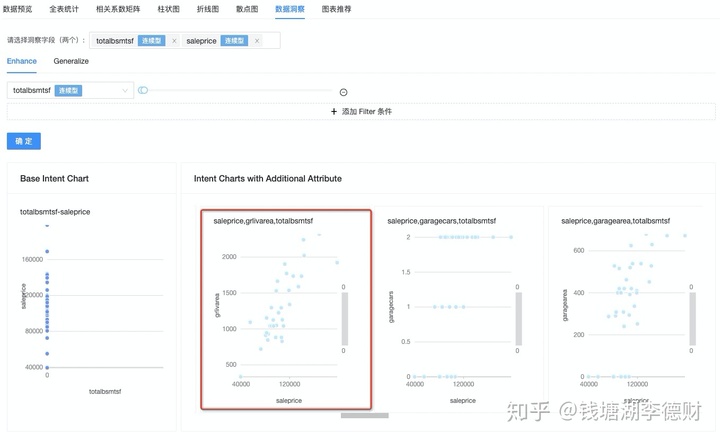
在数据探查中,将 totalbsmtsf 范围设定在 0~95,可以看到在该范围下 totalbsmtsf 与 saleprice 没有关联,但依然不会影响 grlivarea 与 saleprice 的线性关系。
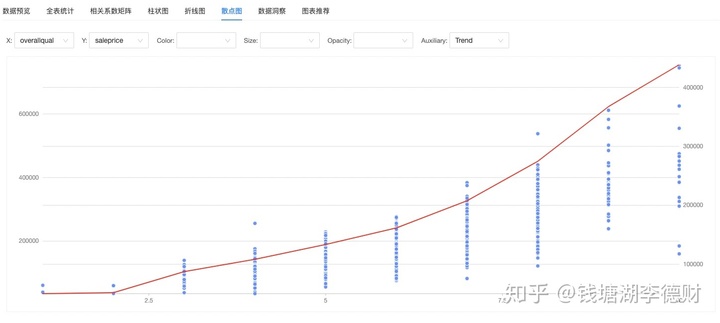
可以看出 overallqual 与 saleprice 的分布趋势相同。
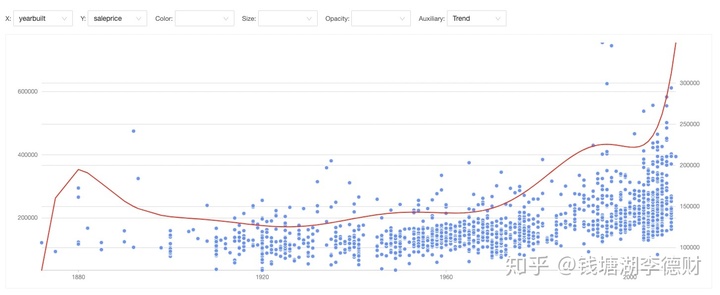
yearbuilt 与 saleprice 似乎没有什么趋势,但可以看出房龄越短的房子价格越高。
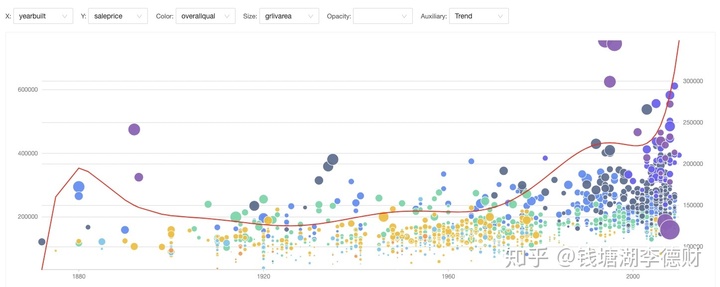
而当把 overallqual 和 grlivarea 分别设置为 color 与 size 时,可以看出虽然房龄在增加,面积也是房价坚挺的原因之一;而装修的等级在影响价格的同时似乎与房龄存在一些联系:每个时期的都有特定的装修风格,同时随着时间推移装修等级也在逐渐升高。
除了这四项主观挑选的特征外,我们再看看整个样本的相关性。

乍一看似乎难以发现什么信息。我们调整一下阈值,去掉一些相关系数底的特征:
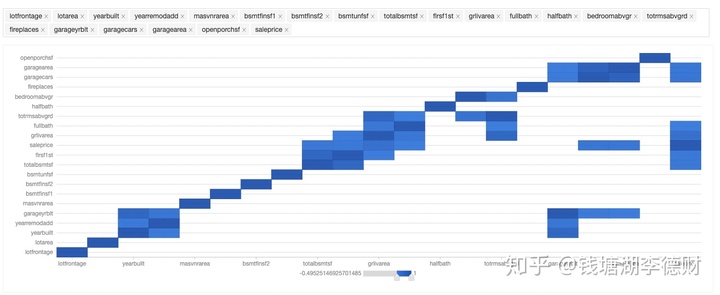
可以看到:
- grlivarea、totalbsmtsf 与 saleprice 有很强的相关性,与我们的主观猜想一致。
- garagecars 和 garagearea、totalbsmtsf 和 1stFloor、totrmsabvgrd 和 grlivarea 两两具有很强的相关性,事实上它们所表达信息的对房价的权重也是相似的。于是我们挑选它们中与 salepraice 相关系数高的作为入模变量(garagecars、totalbsmtsf、grlivarea)。
目标的分析与处理
我们的最终目的是为了预测房价。经过上述步骤,我们对样本集进行了清洗,得到了令人满意的特征集。现在我们再进一步对处理过的样本进行分析。
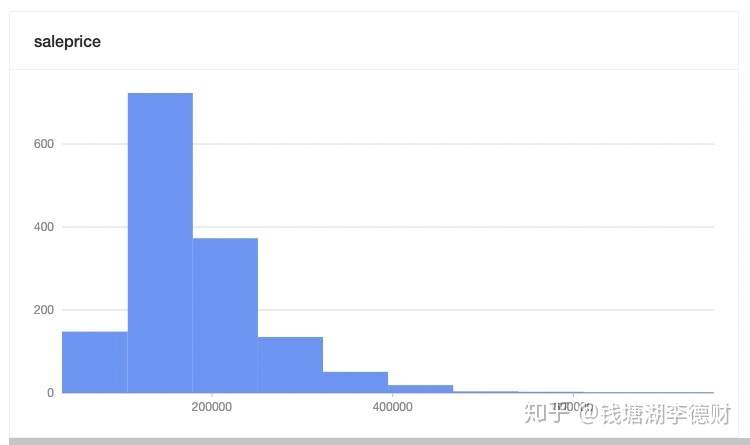
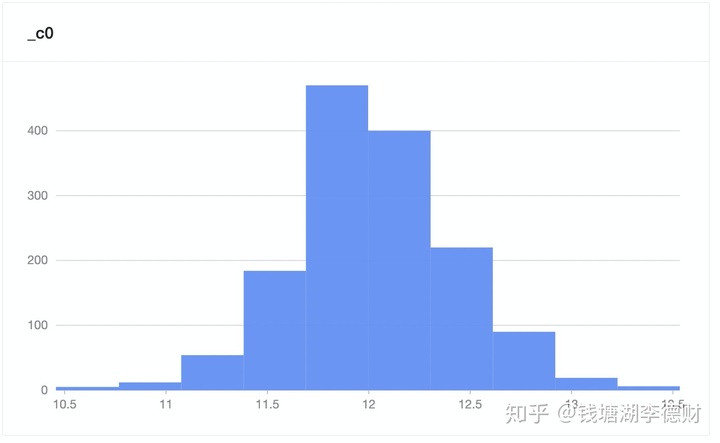
样本中 saleprice 并不是标准正太分布。这里使用对数变换来解决:
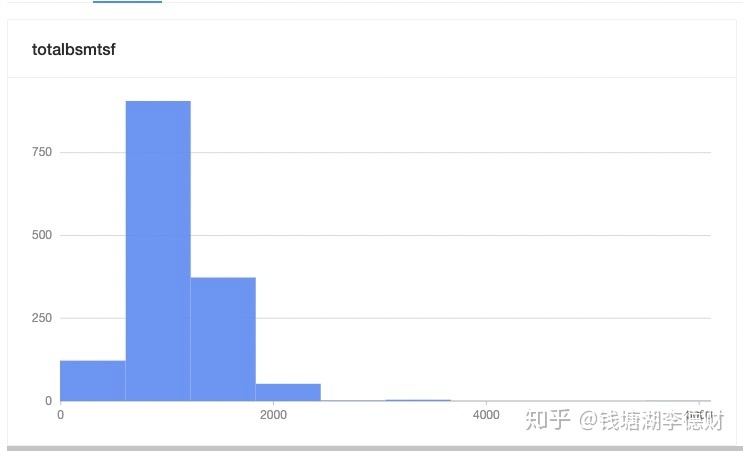
totalbsmtsf 也是同样的问题,依旧进行对数变换:
其他类似处理不再赘述。
总结
至此,我们已经得到了一个相对完美的入模样本集,可以开始模型训练流程。可以看到在数据预处理的过程中,可视化基本贯穿了整个流程,是不可或缺的一部分。而借助可视化容器以及 AntV 的能力,建模平台产品可以为用户提供机器高效方便的可视化解决方案,能够帮助用户快速完成数据处理工作。
至于房价预测的模型训练部分内容,可使用多种算法解决。本文重点在于建模平台可视化相关功能讨论,对于模型训练与评估阶段,我们将以经典的德国评分卡模型为例来为大家介绍平台相关的可视化功能。
模型训练与评估
在评分卡问题中,我们可以从网上找到完美的入模样本数据[2],从而省略上文所述的数据预处理过程,直接开始模型训练。
评分卡作为机器学习中最具有代表性的二分类问题,其方法论在商业应用中的落地场景数不胜数,可谓是最简单高效的二分类问题解决方案。
信用评分卡模型在国外是一种成熟的预测方法,尤其在信用风险评估以及金融风险控制领域更是得到了比较广泛的使用,其原理是将变量通过分箱离散化之后运用二分类线性模型对数据进行建模。
在该案例中,我们将数据样本按特征进行分箱,之后使用逻辑回归算法训练出二分类模型。最后通过模型评估,我们来判断所得模型的“质量”。
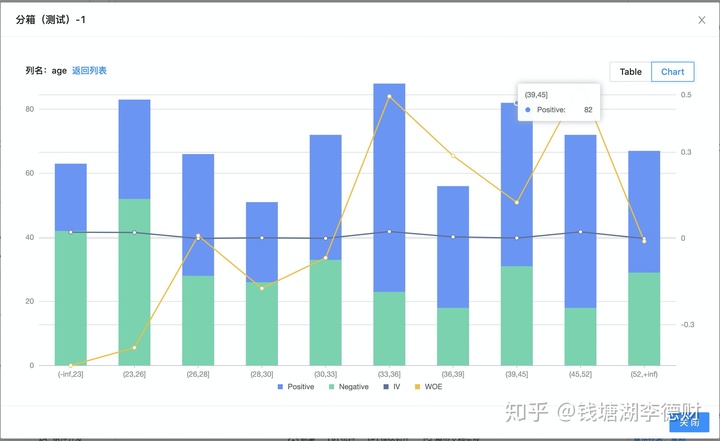
分箱
分箱是一种数据离散化的操作,通常包括等频、等宽分箱两种操作。这里我们对评分卡样本中的所有特征列进行等频分箱,分箱数为 10。
建模平台中的为用户提供了可视化方式的分箱操作。用户快速查看离散分析报告,同时对分箱结果进行二次手动编辑。
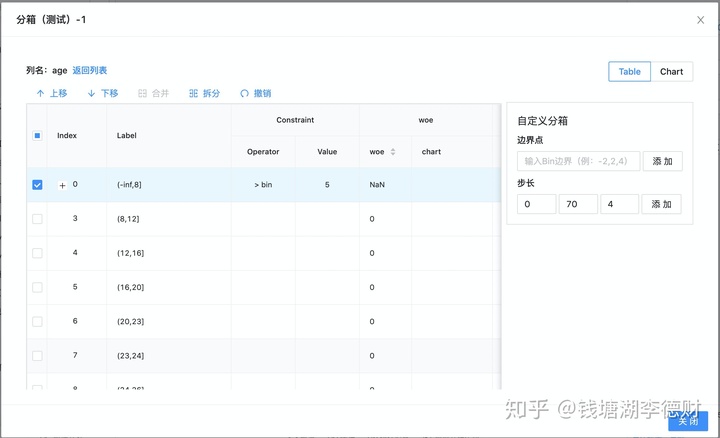
模型训练与评估
在得到合适的离散值后,就可以入模训练。为了帮助用户快速完成模型开发的流程,建模平台基本模型评估的基础上增加了配套的可视化能力。
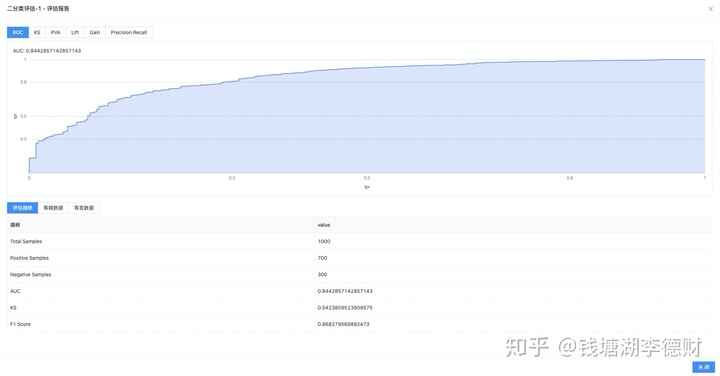
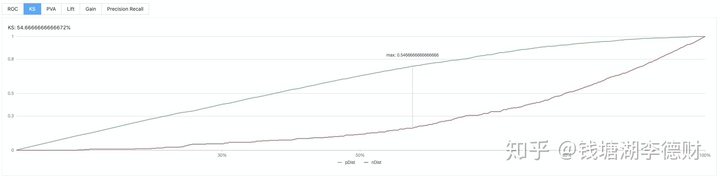
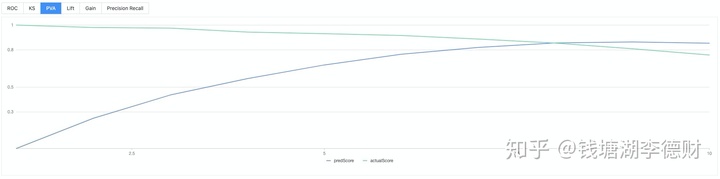
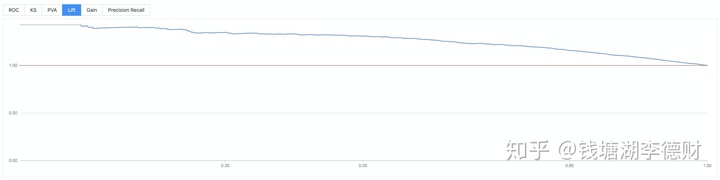
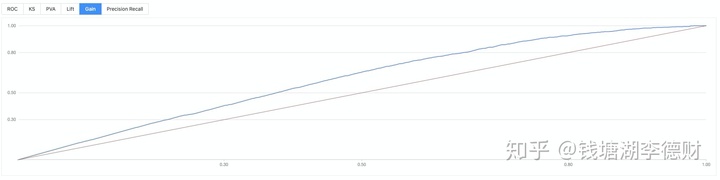
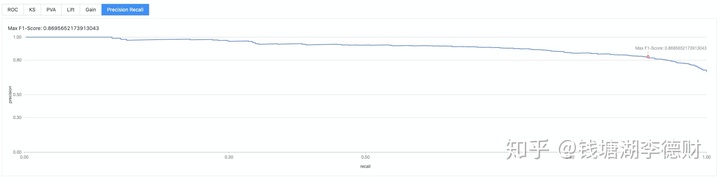
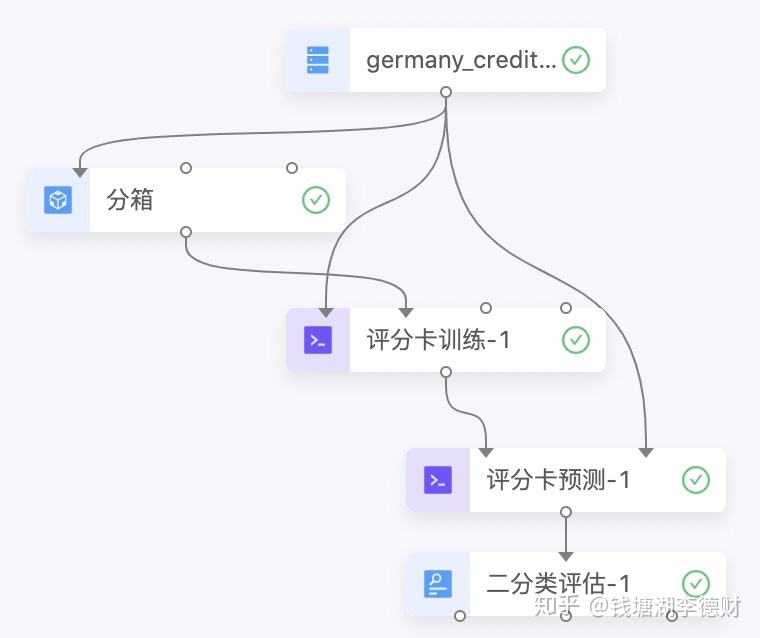
至此,以大致完成整个模型训练流程。整个流程编排:
写在最后
值得一提得是,上述可视化相关的功能从前到后都是前端同学自己进行了实现(没有任何后端同学参与)。在展示层,依赖 AntV 为用户提供了丰富的图表交互能力;在数据以及逻辑计算层,基于 Python 容器可以快速高效完成可视化展示相关的数据计算。前端与 Python 容器直连通信,自然不再需要后端同学提供支持了。
关于我们
我们是蚂蚁体验技术部数据智能前端小组。我们着手于机器学习平台,图编辑、WebIDE、Notebook、数据可视化什么的都是我们的能力范围,快来加入我们吧!
参考
- ^Kaggle 房价预测问题 https://www.kaggle.com/c/house-prices-advanced-regression-techniques/data
- ^评分卡样本集及字段解释 https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)















 2705
2705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









