







最优化问题是计算数学中最为重要的研究方向之一。在深度学习领域,优化算法同样是关键环节之一。即使完全相同的数据集与模型架构,不同的优化算法也很可能导致不同的训练结果,甚至有的模型出现不收敛现象。
进行过深度学习模型训练的小伙伴都清楚:一个训练过程的完成包含以下几点:
- 数据集加载
- 网络搭建
- 优化器设置
- 学习率调整(可选)
对caffe了解的童鞋应该比较清楚,在训练之前需要编写两个prototxt文件,分别是:(1)net.prototxt,它定义了训练网络以及相关数据集加载方式等;(2) solver.prototxt,它定义待优化的网络以及优化器以及学习率调整机制。下面给出了caffe与pytorch的相关优化器定义方式。
# copy from caffe/examples/mnist.
net: "lenet_train_test.prototxt"
base_lr: 0.001
momentum: 0.9
momentum2: 0.999
type: "Adam"
# pytorch version
net = YourNet()
optimizer = Adam(net.parameters(), lr=0.001, betas=(0.9, 0.999)) 深度学习相关论文看的多就会发现,大部分论文的优化器主要是SGD, Adam以及RMSprop,甚少见到其他形式的优化器。那么除了上述三种外还有哪些可供选择的优化器呢?
通过查看Pytorch中的optim模块源码,可以发现:Pytorch框架中支持以下几种优化器。

梯度下降简介
梯度下降是目前神经网络中使用最为广泛的优化算法之一。为弥补基本梯度下降的种种缺陷,研究者们提出了一系列的变种算法,从最初的SGD逐步演变到Adam、RMSprop等。
Gradient Descent
标准的梯度下降可以描述为: $$ theta = theta -eta cdot nabla_{theta}J(theta) $$ 标准的梯度下降是对计算所有训练样例的梯度再进行参数更新。标准梯度下降方法的缺点是:训练速度慢,同时容易陷入局部最优。关于梯度下降的伪码如下:
for i in range(epoch):
params_grad = evaluete_gradient(loss_fn, data, params)
params = prams - learning_rate * params_gradStochastic Gradient Descent
不同于标准梯度下降中计算所有样例的的损失后再计算梯度,SGD对每一个样例计算一次梯度并更新参数。可以描述为: $$ theta = theta -eta cdot nabla_{theta}J(theta; x^{(i)};y^{(i)}) $$ SGD可以很轻易的跳出局部最优,但会因个别样例梯度过大而出现过大的波动,如下图所示。
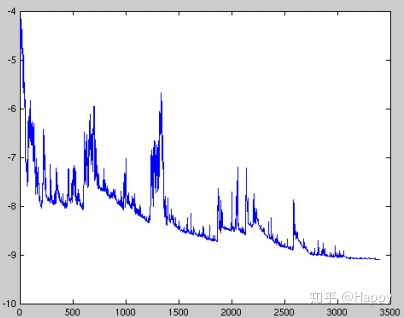
Mini-batch Gradient Descent
批梯度下降是介于两者之间的方法,可以用如下公式进行描述:
它在一定程度上避免了前两者的弊端,是当前深度学习领域最常用的方法,常用SGD称呼。
改进版优化器
前述优化器可以一定程度上解决大部分优化问题,但是它们无法保证收敛到全局最优(近全局最优)。存在以下几点挑战:
- 如何选择合适的学习率。学习率过小导致过慢收敛速度,过大则会影响收敛性能;
- 如何调整学习率。
- 不同参数学习率自适应问题。
- 如何跳出局部最优。
事实上,关于优化器的介绍,参考3与参考6已经介绍的非常详细。限于个人数学功底薄弱,就不再进行优化器的更多介绍了,请移步深度学习最全优化方法总结比较与An overview of gradient descent optimization algorithms。这里仅仅对每个优化器进行简单的公式汇聚。
Momentum
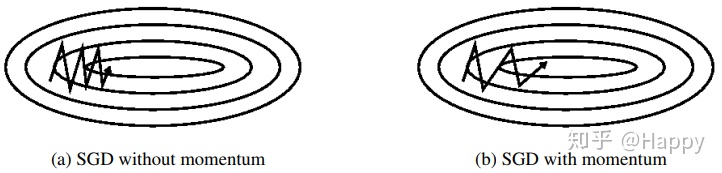
动量是一种加速SGD收敛的方法,上图给出了带与不带动量时的SGD收敛示意图。动量方法用公式描述如下:
Nesterov Accelerated Gradient
NAG公式描述如下:
Adagrad
它是一种自适应学习率的方法,对于低频率参数执行高学习率,对于高频参数执行地学习率。该特性使得它比较适合于处理稀疏数据。它公式描述如下:
RMSprop
公式描述如下:
Adam
公式描述如下:
AdaMax
公式描述如下:
Other略
如何选择优化器
关于如何选择优化器,目前还没有达成共识。可以参考一下优化器综述一文中的对比分析。目前最流程且使用率最高的当属Adam、SGD、RMSprop及带动量因子版本。
- 对于稀疏数据,尽量使用学习率可自适应的优化方法,不用手动调节学习率;
- SGD通过训练时间更长,在更好的学习率配置方案下往往具有更可靠的结果;
- Adam在实际应用中效果比较好,大部分场景下均超过了其他的自适应技术;
- 如果希望有更快的收敛速度,推荐使用学习率自适应的优化方法;
---------
- 机器学习:各种优化器Optimizer的总结与比较
- 深度学习——优化器算法Optimizer详解
- 深度学习最全优化方法总结比较
- 从SGD到Adam-深度学习优化算法概览
- 一文看懂各种神经网络优化算法:从梯度下降到Adam方法
- An overview of gradient descent optimization algorithms














 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









