





本教程演示了如何使用基于字符的 RNN 生成文本。我们将使用 Andrej Karpathy 在 The Unreasonable Effectiveness of Recurrent Neural Networks 一文中提供的莎士比亚作品数据集。
我们根据此数据(“Shakespear”)中的给定字符序列训练一个模型,让它预测序列的下一个字符(“e”)。通过重复调用该模型,可以生成更长的文本序列。

tensorflow2.0教程
本教程中包含使用 tf.keras 和 Eager Execution 实现的可运行代码。以下是本教程中的模型训练了30个周期时的示例输出,并以字符串“Q”开头:
QUEENE:I had thought thou hadst a Roman; for the oracle,Thus by All bids the man against the word,Which are so weak of care, by old care done;Your children were in your holy love,And the precipitation through the bleeding throne.BISHOP OF ELY:Marry, and will, my lord, to weep in such a one were prettiest;Yet now I was adopted heirOf the world's lamentable day,To watch the next way with his father with his face?ESCALUS:The cause why then we are all resolved more sons.VOLUMNIA:O, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, it is no sin it should be dead,And love and pale as any will to that word.QUEEN ELIZABETH:But how long have I heard the soul for this world,And show his hands of life be proved to stand.PETRUCHIO:I say he look'd on, if I must be contentTo stay him from the fatal of our country's bliss.His lordship pluck'd from this sentence then for prey,And then let us twain, being the moon,were she such a case as fills m虽然有些句子合乎语法规则,但大多数句子都没有意义。该模型尚未学习单词的含义,但请考虑以下几点:
- 该模型是基于字符的模型。在训练之初,该模型都不知道如何拼写英语单词,甚至不知道单词是一种文本单位。
- 输出的文本结构仿照了剧本的结构:文本块通常以讲话者的名字开头,并且像数据集中一样,这些名字全部采用大写字母。
- 如下文所示,尽管该模型只使用小批次的文本(每批文本包含 100 个字符)训练而成,但它仍然能够生成具有连贯结构的更长文本序列。
1. 设置Setup
1.1. 导入 TensorFlow 和其他库
from __future__ import absolute_import, division, print_function, unicode_literals# !pip install tensorflow-gpu==2.0.0-alpha0import tensorflow as tfimport numpy as npimport osimport time1.2. 下载莎士比亚数据集
通过更改以下行可使用您自己的数据运行此代码。
path_to_file = tf.keras.utils.get_file('shakespeare.txt', 'https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt')1.3. 读取数据
首先,我们来看一下文本内容。
# Read, then decode for py2 compat.text = open(path_to_file, 'rb').read().decode(encoding='utf-8')# length of text is the number of characters in itprint ('Length of text: {} characters'.format(len(text)))Length of text: 1115394 characters# Take a look at the first 250 characters in textprint(text[:250])First Citizen:Before we proceed any further, hear me speak.All:Speak, speak.First Citizen:You are all resolved rather to die than to famish?All:Resolved. resolved.First Citizen:First, you know Caius Marcius is chief enemy to the people.# The unique characters in the filevocab = sorted(set(text))print ('{} unique characters'.format(len(vocab)))65 unique characters2. 处理文本
2.1. 向量化文本
在训练之前,我们需要将字符串映射到数字表示值。创建两个对照表:一个用于将字符映射到数字,另一个用于将数字映射到字符。
# Creating a mapping from unique characters to indiceschar2idx = {u:i for i, u in enumerate(vocab)}idx2char = np.array(vocab)text_as_int = np.array([char2idx[c] for c in text])现在,每个字符都有一个对应的整数表示值。请注意,我们按从 0 到 len(unique) 的索引映射字符。
print('{')for char,_ in zip(char2idx, range(20)): print(' {:4s}: {:3d},'.format(repr(char), char2idx[char]))print(' ...}')# Show how the first 13 characters from the text are mapped to integersprint ('{} ---- characters mapped to int ---- > {}'.format(repr(text[:13]), text_as_int[:13]))2.2. 预测任务
根据给定的字符或字符序列预测下一个字符最有可能是什么?这是我们要训练模型去执行的任务。模型的输入将是字符序列,而我们要训练模型去预测输出,即每一个时间步的下一个字符。
由于 RNN 会依赖之前看到的元素来维持内部状态,那么根据目前为止已计算过的所有字符,下一个字符是什么?
2.3. 创建训练样本和目标
将文本划分为训练样本和训练目标。每个训练样本都包含从文本中选取的 seq_length 个字符。
相应的目标也包含相同长度的文本,但是将所选的字符序列向右顺移一个字符。
将文本拆分成文本块,每个块的长度为 seq_length+1 个字符。例如,假设 seq_length 为 4,我们的文本为“Hello”,则可以将“Hell”创建为训练样本,将“ello”创建为目标。
为此,首先使用tf.data.Dataset.from_tensor_slices函数将文本向量转换为字符索引流。
# The maximum length sentence we want for a single input in charactersseq_length = 100examples_per_epoch = len(text)//seq_length# Create training examples / targetschar_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)for i in char_dataset.take(5): print(idx2char[i.numpy()])批处理方法可以让我们轻松地将这些单个字符转换为所需大小的序列。
sequences = char_dataset.batch(seq_length+1, drop_remainder=True)for item in sequences.take(5): print(repr(''.join(idx2char[item.numpy()])))对于每个序列,复制并移动它以创建输入文本和目标文本,方法是使用 map 方法将简单函数应用于每个批处理:
def split_input_target(chunk): input_text = chunk[:-1] target_text = chunk[1:] return input_text, target_textdataset = sequences.map(split_input_target)打印第一个样本输入和目标值:
for input_example, target_example in dataset.take(1): print ('Input data: ', repr(''.join(idx2char[input_example.numpy()]))) print ('Target data:', repr(''.join(idx2char[target_example.numpy()])))这些向量的每个索引均作为一个时间步来处理。对于时间步 0 的输入,我们收到了映射到字符 “F” 的索引,并尝试预测 “i” 的索引作为下一个字符。在下一个时间步,执行相同的操作,但除了当前字符外,RNN 还要考虑上一步的信息。
for i, (input_idx, target_idx) in enumerate(zip(input_example[:5], target_example[:5])): print("Step {:4d}".format(i)) print(" input: {} ({:s})".format(input_idx, repr(idx2char[input_idx]))) print(" expected output: {} ({:s})".format(target_idx, repr(idx2char[target_idx])))2.4. 使用 tf.data 创建批次文本并重排这些批次
我们使用 tf.data 将文本拆分为可管理的序列。但在将这些数据馈送到模型中之前,我们需要对数据进行重排,并将其打包成批。
3. 实现模型
使用tf.keras.Sequential来定义模型。对于这个简单的例子,我们可以使用三个层来定义模型:
- tf.keras.layers.Embedding:嵌入层(输入层)。一个可训练的对照表,它会将每个字符的数字映射到具有 embedding_dim 个维度的高维度向量;
- tf.keras.layers.GRU: GRU 层:一种层大小等于单位数(units = rnn_units)的 RNN。(在此示例中,您也可以使用 LSTM 层。)
- tf.keras.layers.Dense:密集层(输出层),带有vocab_size个单元输出。
# Length of the vocabulary in charsvocab_size = len(vocab)# The embedding dimensionembedding_dim = 256# Number of RNN unitsrnn_units = 1024def build_model(vocab_size, embedding_dim, rnn_units, batch_size): model = tf.keras.Sequential([ tf.keras.layers.Embedding(vocab_size, embedding_dim, batch_input_shape=[batch_size, None]), tf.keras.layers.LSTM(rnn_units, return_sequences=True, stateful=True, recurrent_initializer='glorot_uniform'), tf.keras.layers.Dense(vocab_size) ]) return modelmodel = build_model( vocab_size = len(vocab), embedding_dim=embedding_dim, rnn_units=rnn_units, batch_size=BATCH_SIZE)对于每个字符,模型查找嵌入,以嵌入作为输入一次运行GRU,并应用密集层生成预测下一个字符的对数可能性的logits:
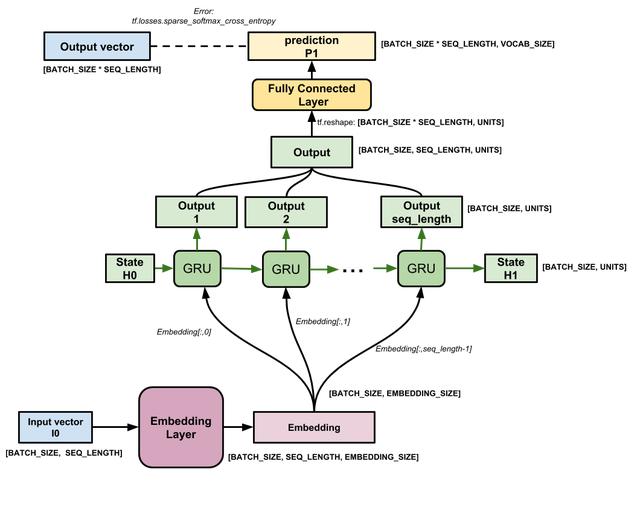
模型
4. 试试这个模型
现在运行模型以查看它的行为符合预期,首先检查输出的形状:
for input_example_batch, target_example_batch in dataset.take(1): example_batch_predictions = model(input_example_batch) print(example_batch_predictions.shape, "# (batch_size, sequence_length, vocab_size)")(64, 100, 65) # (batch_size, sequence_length, vocab_size)在上面的示例中,输入的序列长度为 100 ,但模型可以在任何长度的输入上运行:
model.summary()为了从模型中获得实际预测,我们需要从输出分布中进行采样,以获得实际的字符索引。此分布由字符词汇表上的logits定义。
注意:从这个分布中进行_sample_(采样)非常重要,因为获取分布的_argmax_可以轻松地将模型卡在循环中。
尝试批处理中的第一个样本:
sampled_indices = tf.random.categorical(example_batch_predictions[0], num_samples=1)sampled_indices = tf.squeeze(sampled_indices,axis=-1).numpy()这使我们在每个时间步都预测下一个字符索引:
sampled_indices解码这些以查看此未经训练的模型预测的文本:
print("Input: 














 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









