







本文主要从以下几个方面介绍SparkStreaming读取Kafka的两种方式:
一、SparkStreaming简介
二、Kafka简介
三、Redis简介(可用于保存历史数据或偏移量数据)
四、SparkStreaming读取Kafka数据的两种方式
五、演示Demo
一、SparkStreaming简介
可以参考这篇文章:SparkStreaming 详解
二、Kafka简介
可以参考这篇文章:Kafka(分布式发布订阅消息系统) 简介
三、Redis简介
可以参考这篇文章:Redis简介
四、SparkStreaming读取Kafka数据的两种方式
spark streaming提供了两种获取方式,一种是利用接收器(receiver)和kafaka的高层API实现。
一种是不利用接收器,直接用kafka底层的API来实现(spark1.3以后引入)。
1、reciver链接方式(有些问题,开发中不采用这种方式)
- 用KafkaUtils.createDstream创建链接。Receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming启动的job会去处理那些数据。
- Receiver方式是通过zookeeper来连接kafka队列,调用Kafka高阶API,offset存储在zookeeper,由Receiver维护。
- 在executor上会有receiver从kafka接收数据并存储在Spark executor中,在到了batch时间后触发job去处理接收到的数据,1个receiver占用1个core使用wal预写机制,因为需要使用hdfs等存储,因此会降低性能。
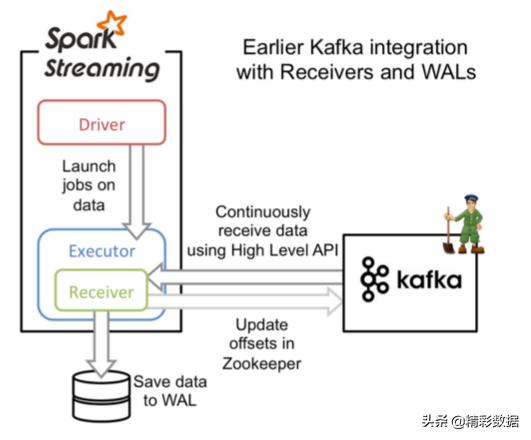
receiver方式
基于Receiver方式存在的问题:
- 启用WAL机制,每次处理之前需要将该batch内的数据备份到checkpoint目录中,这降低了数据处理效率,同时加重了Receiver的压力;另外由于数据备份机制,会受到负载影响,负载一高就会出现延迟的风险,导致应用崩溃。
- 采用MEMORY_AND_DISK_SER降低对内存的要求,但是在一定程度上影响了计算的速度。
- 单Receiver内存。由于Receiver是属于Executor的一部分,为了提高吞吐量,提高Receiver的内存。但是在每次batch计算中,参与计算的batch并不会使用这么多内存,导致资源严重浪费。
- 提高并行度,采用多个Receiver来保存kafka的数据。Receiver读取数据是异步的,不会参与计算。如果提高了并行度来平衡吞吐量很不划算。
- Receiver和计算的Executor是异步的,在遇到网络等因素时,会导致计算出现延迟,计算队列一直在增加,而Receiver一直在接收数据,这非常容易导致程序崩溃。
- 在程序失败恢复时,有可能出现数据部分落地,但是程序失败,未更新offsets的情况,这会导致数据重复消费。
2、Direct直连方式(开发中使用的方式)
- 使用KafkaUtils.createDirectStream创建链接。这种方式定期从kafka的topic下对应的partition中查询最新偏移量,并在每个批次中根据相应的定义的偏移范围进行处理。Spark通过调用kafka简单的消费者API读取一定范围的数据。
- Direct方式是直接连接kafka分区来获取数据。从每个分区直接读取数据大大提高了并行能力Direct方式调用Kafka低阶API(底层API),offset自己存储和维护,默认由Spark维护在checkpoint中,消除了与zk不一致的情况当然也可以自己手动维护,把offset存在mysql、redis中所以基于Direct模式可以在开发中使用,且借助Direct模式的特点+手动操作可以保证数据的Exactly once 精准一次
基于Direct方式的优势:
- 简化并行读取:如果要读取多个partition,不需要创建多个输入DStream然后对他们进行union操作。Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从kafka中读取数据。所以在kafka partition和RDD partition之间,有一一对应的关系。
- 高性能:如果要保证数据零丢失,在基于Receiver的方式中,需要开启WAL机制。这种方式其实效率很低,因为数据实际被复制了两份,kafka自己本身就有高可靠的机制,会对数据复制一份,而这里又会复制一份到WAL中。而基于Direct的方式,不依赖于Receiver,不需要开启WAL机制,只要kafka中做了数据的复制,那么就可以通过kafka的副本进行恢复。
- 强一致语义:基于Receiver的方式,使用kafka的高阶API来在Zookeeper中保存消费过的offset。这是消费kafka数据的传统方式。这种方式配合WAL机制,可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和Zookeeper之间可能是不同步的。基于Direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据时消费一次且仅消费一次。
- 降低资源:Direct不需要Receiver,其申请的Executors全部参与到计算任务中;而Receiver则需要专门的Receivers来读取kafka数据且不参与计算。因此相同的资源申请,Direct能够支持更大的业务。Receiver与其他Executor是异步的,并持续不断接收数据,对于小业务量的场景还好,如果遇到大业务量时,需要提高Receiver的内存,但是参与计算的Executor并不需要那么多的内存,而Direct因为没有Receiver,而是在计算的时候读取数据,然后直接计算,所以对内存的要求很低。
- 鲁棒性更好:基于Receiver方式需要Receiver来异步持续不断的读取数据,因此遇到网络、存储负载等因素,导致实时任务出现堆积,但Receiver却还在持续读取数据,此种情况容易导致计算崩溃。Direct则没有这种顾虑,其Driver在触发batch计算任务时,才会读取数据并计算,队列出现堆积并不不会引起程序的失败。
基于Direct方式的不足:
- Direct方式需要采用checkpoint或者第三方存储
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









