







 本文介绍了一种新型的视频插帧技术,通过将运动估计与像素合成融合为一个过程,利用深度卷积神经网络估计自适应卷积核。这种方法解决了传统两步法在遮挡、模糊和亮度变化等问题上的不足,能够生成高质量的视频插帧结果。实验表明,端到端训练的深度学习模型在处理挑战性视频场景时表现优异。
本文介绍了一种新型的视频插帧技术,通过将运动估计与像素合成融合为一个过程,利用深度卷积神经网络估计自适应卷积核。这种方法解决了传统两步法在遮挡、模糊和亮度变化等问题上的不足,能够生成高质量的视频插帧结果。实验表明,端到端训练的深度学习模型在处理挑战性视频场景时表现优异。
通过自适应卷积的视频插帧
摘要
视频插帧通常涉及两个步骤:运动估计和像素合成。这种两步法的效果很大程度上取决于运动估计的质量。本文提出了一种鲁棒的视频插帧方法,该方法将这两个步骤组合为一个过程。具体来说,我们的方法将内插帧的像素合成视为两个输入帧上的局部卷积。卷积核捕获输入帧之间的局部运动以及用于像素合成的系数。我们的方法采用全卷积的深度神经网络来估计每个像素的空间自适应卷积核。可以直接使用大量的可用视频数据直接端到端地训练此深度神经网络,而无需像光流这样的难以获得的标准数据。我们的实验表明,将视频插值表述为单个卷积过程可以使我们的方法很好地处理诸如遮挡,模糊和亮度突然变化之类的问题,并实现高质量的视频插帧。
1. 介绍
插帧是一个经典的计算机视觉问题,对于诸如新颖的视图插值(view interpolation)和帧率转换等应用非常重要[36]。传统的插帧方法有两个步骤:运动估计(通常是光流)和像素合成[1]。在受遮挡,模糊和亮度突然变化的区域,光流通常很难估算。基于流的像素合成方法无法可靠地处理遮挡问题。这两个步骤中任何一个步骤的失败都会导致插帧视频帧中出现明显的伪像(artifacts)。
本文提出了一种通过深度卷积神经网络实现插帧的鲁棒视频插帧方法,并且无需将其明确划分为单独的步骤。我们的方法将像素插值视为对两个输入视频帧中相应图像块的卷积,并使用深度全卷积神经网络来估计空间自适应卷积核。具体来说,对于内插帧中的像素 ( x , y ) (x,y) (x,y),深度神经网络将以该像素为中心的两个感知野块(receptive field patches) R 1 R_{1} R1和 R 2 R_{2} R2作为输入,并估计卷积核 K K K。该卷积核用于与输入块 P 1 P_{1} P1和 P 2 P_{2} P2进行卷积来合成输出像素,如图1所示。
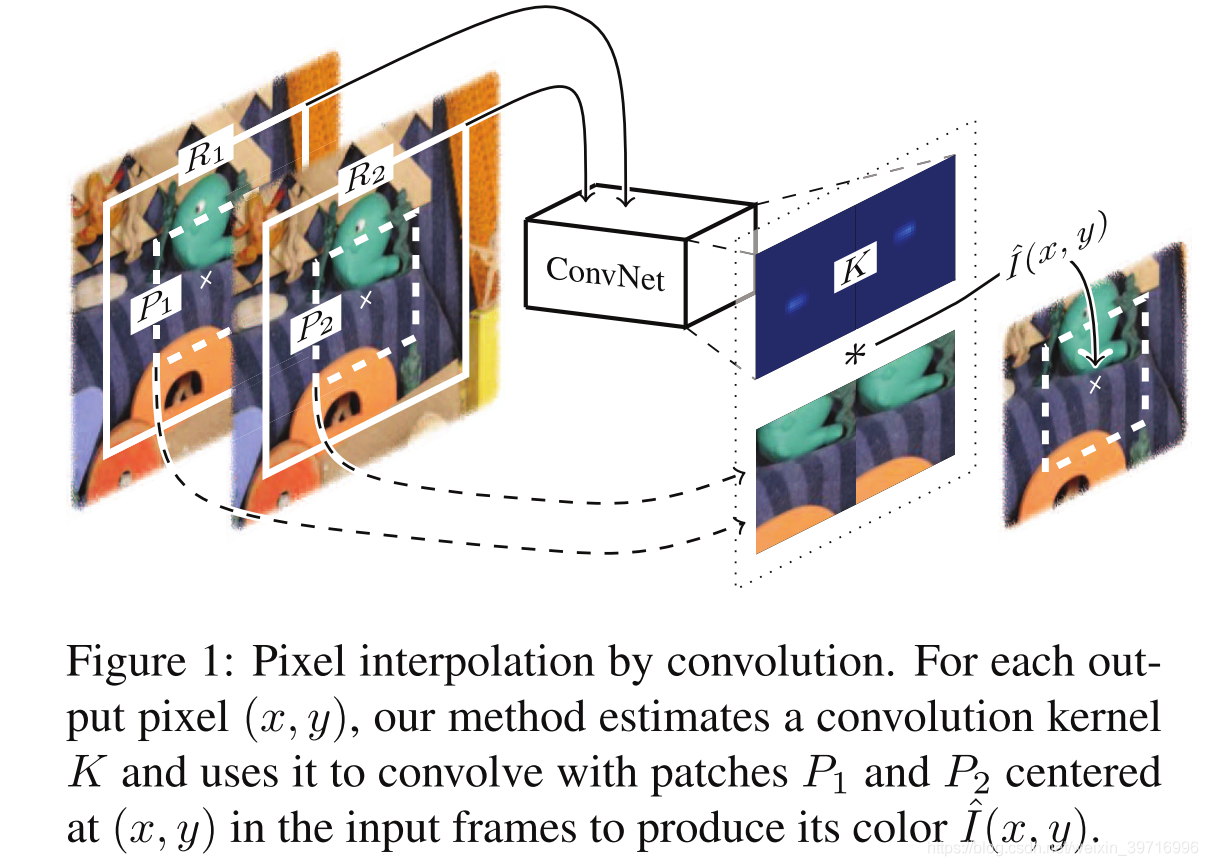
我们方法的一个重点是将像素插值表述为在像素块上的卷积,而不是依赖于光流。该卷积公式将运动估计和像素合成统一为一个过程。它使我们能够为视频插帧设计一个深度全卷积神经网络,而无需将插值划分为单独的步骤。该公式比基于光流的公式更灵活,并且可以更好地处理具有挑战性的插帧情景。此外,我们的神经网络能够估计能得出清晰结果的边缘感知卷积核。
本文的主要贡献是一种鲁棒的视频插帧方法,该方法采用全深度卷积神经网络来产生高质量的视频插值结果。该方法具有一些优点:首先,由于将视频插值建模为单个过程,因此它能够在相互竞争的约束之间做出适当的权衡,从而可以提供鲁棒的插值方法。其次,可以使用广泛的可用视频数据直接端对端地训练该插帧深度卷积神经网络,而无需像光流这样的难以获取的标准数据。第三,如我们的实验所示,我们的方法可以为具有挑战性的视频场景(例如具有遮挡,伪影模糊和亮度突然变化的视频)生成高质量的插帧结果。
2. 相关的工作
视频插帧是计算机视觉和视频的基本处理技术之一。视频插帧是基于图像的渲染的特例,并且根据时间上相邻的帧插入中间帧。[25、44、62]是关于图像渲染的优秀研究。本节重点研究视频插帧和我们的工作。
现有的大多数插帧方法使用立体匹配或光流算法在两个连续的输入帧之间进行密度运动(dense motion)估计,然后根据估计的密度对应关系插值一个或多个中间帧[1、53、61]。与这些方法不同,Mahajan等人开发了一种运动梯度方法,该方法可以估计输入图像中的路径,将适当的梯度复制到待插值的帧中的每个像素,然后通过泊松重建合成插值的帧[33]。所有上述方法的性能都取决于密度对应估计(dense correspondence estimation)的质量,并且在之后的图像合成中要特别注意处理诸如遮挡之类的问题。
作为基于显式运动估计方法的替代,基于相位的方法近来已显示在视频处理方面很有前景。这些方法在输入帧之间的相位差中编码运动,并利用相位信息进行诸如运动放大[51]和视图展开[6]之类的应用。 Meyer等人通过使用有界位移校正策略在定向的多尺度金字塔层次上传播相位信息,进一步扩展了这些方法以适应大型运动[36]。这种基于相位的插值方法可以产生非常好的视频插值结果,并可以轻松地处理具有挑战性的场景。但是,仍需要进一步改进来更好地保留帧间变化较大的视频中的高频细节。
深度学习在解决困难的视觉理解问题[16、20、26、28、39、40、42、45、54、60、64]以及其他计算机视觉问题,例如光流估计[9、14、19、48、49、52],样式转换[11、15、23、30、50]和图像增强[3、7、8、41、43、55、57、63、66 ]方面的成功,都激发了我们的工作灵感。我们的方法与最近的用于视图合成的深度学习算法[10、13、24、29、47、59、65]尤其具有相关性。 Dosovitiskiy等人[10],Kulkarni等人[29],Yang等人[59]和Tatarchenko等人[47]开发了深度学习算法,可以从输入图像渲染看不见的视图。这些算法适用于椅子和面部等物体,不是为一般场景视频的插帧而研发的。
最近,Flynn等人开发了一种深度卷积神经网络方法,用于从真实的输入图像中合成新的自然图像。他们的方法将输入图像投影到多个深度平面(depth planes)上,并在这些深度平面上组合颜色以创建的视图[13]。 Kalantari等人提供了一种基于深度学习的视图合成算法,用于光场成像的视图扩展。他们将新的合成过程分解为两个部分:视差和颜色估计,并使用两个卷积神经网络依次对这两个部分进行建模。这两个神经网络被同时训练[24]。 Long等人将插帧作为图像匹配的中间步骤[31]。然而,他们的内插帧往往是模糊的。周观察到同一物体的不同视图的视觉外观(appearance)是高度相关的,并设计了一种深度学习算法来预测外观流,该流用于选择输入视图中的适当像素以合成新视图[65]。给定多个输入视图,他们的方法可以通过使用相应的外观变换单个输入视图,然后将它们正确组合在一起,从而得到插值的新视图。
与这些方法一样,我们的深度学习算法也可以直接使用视频进行端到端的训练。与这些方法相比,我们的方法专用于视频感知野。更重要的是,我们的方法估计了可以同时捕获运动系数和内插系数的卷积核,并使用这些卷积核直接与输入图像进行卷积以合成中间视频帧。我们的方法不需要将输入图像投影到多个深度平面上,也不需要显式估计视差或外观流来处理输入图像并将它们组合在一起。我们的实验表明,将感知野公式化为单个卷积步骤,可以使我们的方法可靠地处理具有挑战性的情况。最后,使用卷积进行图像合成的想法在帧外插中也有所体现[12,22,58]。
3. 视频插值
给定两个视频帧 I 1 I_{1} I1和 I 2 I_{2} I2,我们的方法旨在时域的两个输入的视频帧中间插入帧 I ^ \hat{I} I^。传统的插值方法通过两个步骤,通过光流进行的密度运动估计和像素插值,来估计像素 I ^ ( x , y ) \hat{I}(x,y) I^(x,y)的颜色。例如,我们可以为像素 ( x , y ) (x,y) (x,y)找到 I 1 I_{1} I1中的对应像素 ( x 1 , y 1 ) (x_{1},y_{1}) (x1,y1)和 I 2 I_{2} I2中的对应像素 ( x 2 , y 2 ) (x_{2},y_{2}) (x2,y2),然后根据这些对应像素插值生成颜色。通常,此步骤还涉及对图像 I 1 I_{1} I1和 I 2 I_{2} I2进行重新采样以获得相应的值 I 1 ( x 1 , y 1 ) I_{1}(x_{1},y_{1}) I1(x1,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









