







Video Frame Interpolation: A Comprehensive Survey
JIONG DONG, KAORU OTA, and MIANXIONG DONG, Muroran Institute of Technology, Japan
ACM Transactions on Multimedia Computing, Communications and Applications(TOMCCAP), 2023, paper
摘要
视频帧插值(VFI)是计算机视觉(CV)领域中一个有趣而具有挑战性的问题,其目的是在两个连续的视频帧之间生成不存在的帧。近年来,许多基于光流、核或相位信息的算法被提出。在本文中,我们对VFI技术的最新进展进行了全面的回顾。首先介绍了VFI算法的开发历史、评估指标和公开可用的数据集。然后详细比较每种算法,指出它们的优缺点,并比较它们在不同显著数据集上的插值性能和速度。VFI技术在CV中不断受到关注,本调查还提到了一些基于VFI的视频处理应用,如慢动作生成、视频压缩、视频恢复等。最后,我们概述了当前视频帧插值技术所面临的瓶颈,并讨论了未来的研究工作。
1. 引言
视频帧插值(VFI) 是视频处理领域长期存在的一个研究课题,它是指在两个连续的视频帧之间合成不存在的帧。该技术在视频处理领域有着广泛的实际应用,如慢动作生成[4,50]、帧率上转换[6,10]、视频压缩[135]、新视图合成[33]、视频恢复[57,117,127,134]、视频编码[19,136]中的内部预测等。
传统的VFI解决方案有两个步骤:首先估计帧之间的运动信息,通常基于光流,然后是像素合成[3]。然而,这种方法存在一个众所周知的问题:在一些具有挑战性的条件下(例如,突然的亮度变化、大运动、遮挡、照明),光流通常难以估计,可能在插值视频帧中造成伪影。
为了解决上述问题,随着基于深度卷积神经网络(CNNs)[30,46,96,113]的光流估计方法的发展,一些VFI算法采用这些模型或它们的变化作为子网络,直接以端到端方式对帧进行插值。如图1(a)所示,flow-based方法估计了直接指向每个输出像素的参考位置的流矢量。
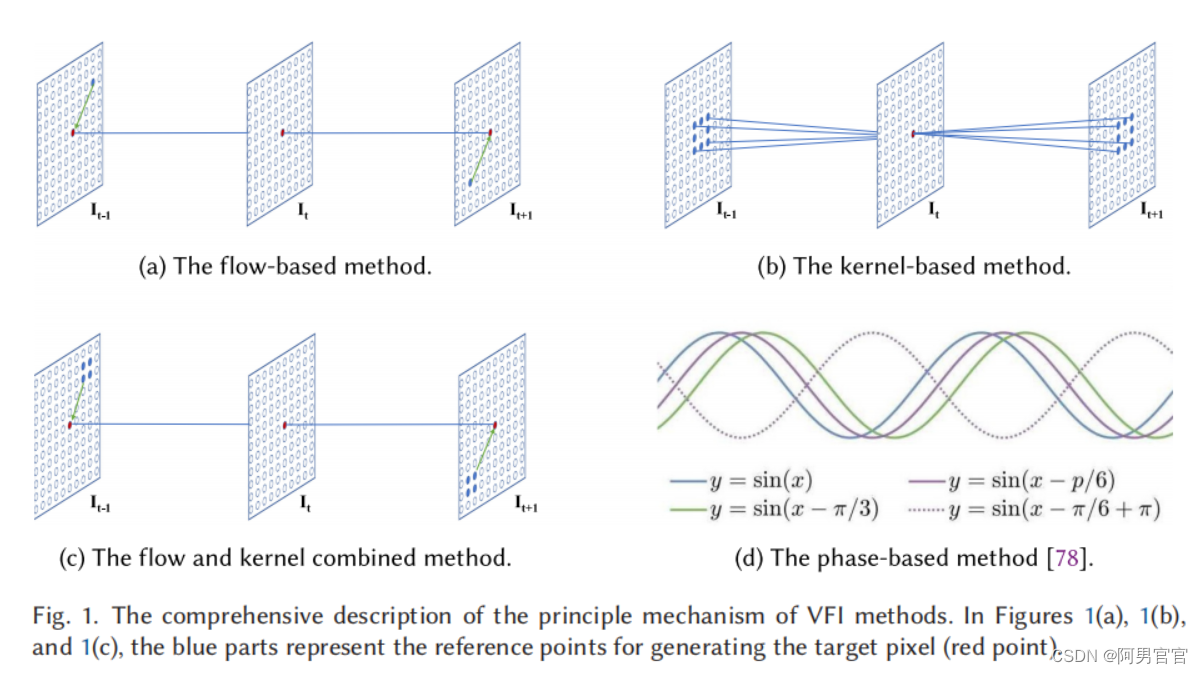
在图1(a)、1(b)和1©中,蓝色部分表示生成目标像素(红点)的参考点
VFI的另一个主要趋势方法是基于内核的(图1(b))[16,26,61,84,85]。在这些方法中,光流估计被看作是一个可以通过单一的卷积操作来绕过的中间相位。这些方法的局限性是如何平衡插值速度和插值质量。可以处理的运动的大小取决于内核的大小。如果核的大小越大,插值过程将需要更多的计算资源;但是,如果尺寸较小,该方法无法解决输入帧之间的大运动,导致中间帧的模糊或阴影。此外,一些算法结合了基于流和基于核的方法的优势来提高插值的性能(图1©)[5,143]。然而,该方法更接近于基于流的方法,因为它比基于核的方法使用更少的参考点。此外,在一些模型中,相位信息被应用于解决VFI问题(图1(d))。基于相位的方法[78,79]描述了单个像素相位移动的运动,允许通过简单的像素相位调整来创建两者之间的图片。
Contribution
- 提供了一个全面的VFI概述,包括基准数据集、性能指标、现有的先进方法的系统比较,以及基于VFI的应用程序。
- 总结了现有方法在一些公共基准数据集上的性能。此外,我们还研究了一些影响VFI效率的关键因素。
- 概述了VFI研究所面临的挑战和未来的趋势。我们的目标是为这个community提供一个有见地的指导。
2. 关于视频帧插值的基本概念
2.1. Problem Definition
根据帧插值的数量和位置,可以将VFI问题定义为单帧插值和多帧插值两类。
Single-Frame Interpolation.
给定两个视频帧
I
0
(
x
,
y
)
I_{0}(x,y)
I0(x,y)和
I
1
(
x
,
y
)
I_{1}(x,y)
I1(x,y),这些VFI算法旨在插值一个不存在的帧,
I
t
(
x
,
y
)
,
t
=
0.5
I_{t}(x,y), t=0.5
It(x,y),t=0.5或
t
∈
[
0
,
1
]
t\in[0,1]
t∈[0,1]。基于光流的VFI方法首先估计双向光流,记为
F
t
−
1
⟶
t
+
1
F_{t-1\longrightarrow t+1}
Ft−1⟶t+1和
F
t
+
1
⟶
t
−
1
F_{t+1\longrightarrow t-1}
Ft+1⟶t−1然后应用前向或向后的warping(adj. 扭曲的)策略来合成中间帧。基于核的VFI方法估计了一对二维卷积核
K
1
(
x
,
y
)
K_{1}(x,y)
K1(x,y)和
K
2
(
x
,
y
)
K_{2}(x,y)
K2(x,y)与
I
t
−
1
(
x
,
y
)
I_{t-1}(x,y)
It−1(x,y)和
I
t
+
1
(
x
,
y
)
I_{t+1}(x,y)
It+1(x,y)进行卷积计算输出像素颜色。然而,当计算大的运动时,二维内核消耗了更多的计算资源,为了解决这个问题,一些方法估计了一对一维内核而不是二维内核。
(补充)warping layer: 将生成光流应用到目标图像上来生成映射后的图像数据。由已知点预测target的计算方案(displacement),给定每个方向
(
X
,
Y
)
(\mathrm {X},\mathrm {Y})
(X,Y)的样条函数的系数
a
1
,
a
x
,
a
y
,
w
i
a_{1},a_{x},a_{y},w_{i}
a1,ax,ay,wi,矩阵表达计算过程
[
U
11
U
21
U
31
1
x
1
y
1
U
12
U
22
U
32
1
x
2
y
2
U
13
U
23
U
33
1
x
3
y
3
1
1
1
0
0
0
x
1
x
2
x
3
0
0
0
y
1
y
2
y
3
0
0
0
]
×
[
w
1
w
2
w
3
a
1
a
x
a
y
]
=
[
y
1
′
y
2
′
y
3
′
0
0
0
]
,
\begin{bmatrix} U_{11}& U_{21} & U_{31} & 1 & x_{1} & y_{1} \\ U_{12}& U_{22} & U_{32} & 1 & x_{2} & y_{2} \\ U_{13}& U_{23} & U_{33} & 1 & x_{3} & y_{3} \\ 1 & 1 & 1 & 0 & 0 & 0 \\ x_{1}& x_{2} & x_{3} & 0 & 0 & 0 \\ y_{1}& y_{2} & y_{3} & 0 & 0 & 0 \\ \end{bmatrix}\times \begin{bmatrix} w_{1}\\ w_{2}\\ w_{3}\\ a_{1}\\ a_{x}\\ a_{y} \end{bmatrix}= \begin{bmatrix} y_{1}'\\ y_{2}'\\ y_{3}'\\ 0\\ 0\\ 0 \end{bmatrix},
U11U12U131x1y1U21U22U231x2y2U31U32U331x3y3111000x1x2x3000y1y2y3000
×
w1w2w3a1axay
=
y1′y2′y3′000
,
其中
U
U
U是变形后的RBF函数,衡量相似性。
Multi-Frame Interpolation.
给定四个输入帧
(
I
−
1
,
I
0
,
I
1
,
I
2
)
(I_{-1},I_{0},I_{1},I_{2})
(I−1,I0,I1,I2),在[17]中,Chi等人的目标是在
I
0
I_{0}
I0和
I
1
I_{1}
I1之间生成7帧,这7帧在特定位置合成:
I
t
i
,
t
i
=
i
8
,
i
∈
[
1
,
2
,
.
.
.
,
7
]
I_{t_{i}},t_{i}=\frac{i}{8},i\in[1,2,...,7]
Iti,ti=8i,i∈[1,2,...,7]。而Super-SloMo [50]方法的目标是在两帧之间的任意时间步长内插值多帧,GDCN [106]方法侧重于一个四帧插值的情况。
2.2. Benchmark Datasets
本小节介绍了一些常用的用于训练和评估VFI方法的基准数据集,包括UCF101 [111]、Vimeo90K [143]、米德尔伯里[3]和在特定论文中使用的其他数据集。
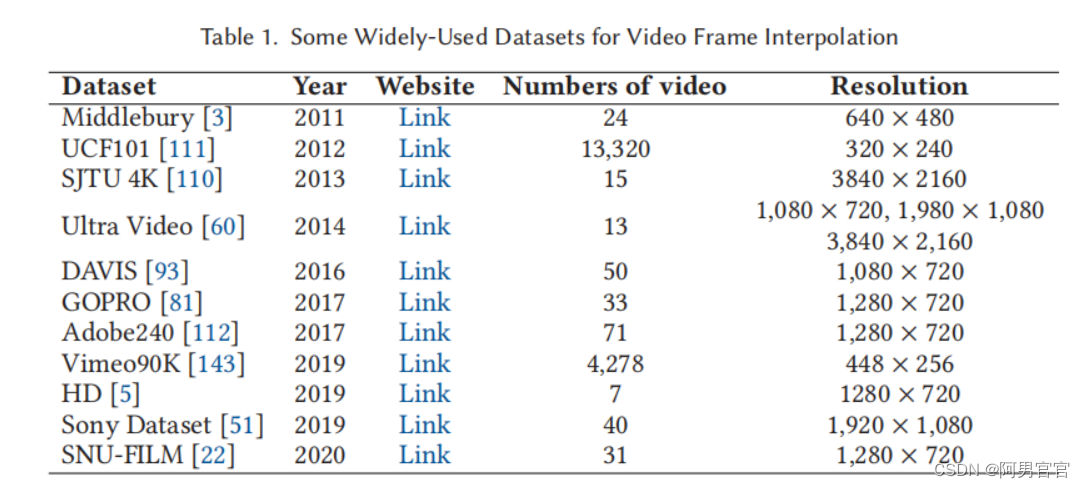
UFC101.
这个数据集包含13320个视频,有大量的人类动作,分辨率为320×240,它包含101个动作类。DVF [73]、CyclicGen [71]和CBOF-Net [37] VFI方法已经使用UCF101数据集进行了训练。
Vimeo90K.
Vimeo90K数据集包含4,278个视频,89,800个独立镜头从Vimeo视频共享网站下载,作者调整了所有帧的大小,分辨率为448×256。许多VFI方法已经应用Vimeo90k数据集进行训练,包括MEMC-Net [5]、DSepConv [15]、AdaCoF [61]、CAIN [22],因为物体的运动要大得多。
Middlebury.
该数据集由一个评估集和一个其他评估集组成。另一组总共包含12个示例,最大分辨率为640×480。大多数VFI研究都报道并比较了他们的方法在米德尔伯里基准测试上的性能,如[79]、[84]和[85]。
HD.
高清数据集是用[5]提出的。Bao等人从Xiph网站上收集了7个高分辨率的高清视频,分辨率为1280×544到1920×1080。这个数据集中的运动比其他数据集都要大。
YouTube240.
在[50]中,Jiang等人从YouTube上收集了大约240帧每秒的视频来训练他们的模型。该数据集总共由1132个视频剪辑和376K个独立的视频帧组成。这个数据集包含广泛的场景,包括日常活动、专业运动、室内和室外场景,以及用静态或移动的相机捕捉。
Adobe240.
在Adobe240 [112]数据集中,有71个视频,240帧的分辨率为1280×720。该数据集最初用于视频去模糊,所有的视频都是用不同的手机和消费者相机拍摄的。
DAVIS.
DAVIS(密集注释VIdeo分割)[93]数据集由50个高质量、全高清1080个视频序列组成,最初提出用于视频中的目标分割。由于该数据集包括具有复杂运动的静态和动态场景,Xu等人[141]应用该数据集来评估他们的二次VFI算法。
GOPRO
GOPRO [81]数据集由手持式GOPRO4 Hero黑色相机生成,由3214对模糊和清晰的图像组成,分辨率为1280×720。此外,该数据集包含了来自室内和室外情况的复杂运动,这对于目前的一些VFI方法来说是困难的。
Sony Dataset.
这个数据集[51]由40个高质量的视频组成,每个视频包含1000帧的1080p帧,这是用索尼RX V相机以250 fps的速度拍摄的。
SNU-FILM
为了评估VFI方法在运动量方面的能力,Choi等人[22]创建了一个更全面的基准数据集,称为SNU-FILM(SNU帧插值),包含大运动和遮挡。该数据集包括31个240帧每秒的视频,其中包括11个来自GOPRO数据集的测试集的视频和20个从YouTube收集的视频。
2.3. 评价指标
峰值信噪比(PSNR)、结构相似度指数(SSIM)[129]、插值误差(IE)[3]和归一化插值误差(NIE)[3]是VFI算法中最常用的性能度量指标。
对于VFI,给定地面真值帧
I
G
T
(
x
,
y
)
I^{GT}(x,y)
IGT(x,y)和插值帧
I
^
(
x
,
y
)
\hat{I}(x,y)
I^(x,y),PSNR定义如下:
P
S
N
R
=
10
⋅
log
10
(
L
2
1
N
∑
x
,
y
N
(
I
G
T
(
x
,
y
)
−
I
^
(
x
,
y
)
)
2
)
,
PSNR=10\cdot \log_{10}{\left ( \frac{L^{2}}{\frac{1}{N} {\textstyle \sum_{x,y}^{N}}\left ( I^{GT}(x,y)-\hat{I}(x,y) \right )^{2} } \right ) } ,
PSNR=10⋅log10
N1∑x,yN(IGT(x,y)−I^(x,y))2L2
,
其中,
L
L
L为最大像素值,通常等于255,
N
N
N为像素数。PSNR的值越大,帧插值的性能越好。
SSIM用于测量两幅图像之间的相似性。结构相似度的范围为-1到1。当两幅图像完全相同时,SSIM的值等于1。给定地面真实帧
I
G
T
(
x
,
y
)
I^{GT}(x,y)
IGT(x,y)和插值帧
I
^
(
x
,
y
)
\hat{I}(x,y)
I^(x,y),SSIM被定义为:
S
S
I
M
=
(
2
μ
I
^
μ
I
G
T
+
c
1
)
(
2
σ
I
^
I
G
T
+
c
2
)
(
μ
I
^
2
+
μ
I
G
T
2
+
c
1
)
(
σ
I
^
2
+
σ
I
G
T
2
+
c
2
)
,
SSIM=\frac{\left ( 2\mu _{\hat{I}}\mu_{I^{GT}} +c_{1} \right ) \left ( 2\sigma _{\hat{I}I^{GT}} +c_{2} \right ) } {\left ( \mu ^{2}_{\hat{I} }+\mu^{2}_{I^{GT}}+c_{1} \right ) \left ( \sigma ^{2}_{\hat{I} }+\sigma^{2}_{I^{GT}}+c_{2} \right ) } ,
SSIM=(μI^2+μIGT2+c1)(σI^2+σIGT2+c2)(2μI^μIGT+c1)(2σI^IGT+c2),
其中
μ
I
^
\mu _{\hat{I}}
μI^和
μ
I
G
T
\mu_{I^{GT}}
μIGT分别是
I
^
\hat{I}
I^和
I
G
T
I^{GT}
IGT的平均值,
σ
I
^
2
\sigma^{2}_{\hat{I}}
σI^2是
I
^
\hat{I}
I^的方差,
σ
I
^
2
\sigma^{2}_{\hat{I}}
σI^2是
I
G
T
I^{GT}
IGT的方差,
σ
I
^
I
G
T
\sigma _{\hat{I}I^{GT}}
σI^IGT是
I
^
\hat{I}
I^和
I
G
T
I^{GT}
IGT之间的协方差,
c
1
c_{1}
c1,
c
2
c_{2}
c2是避免不稳定的常数,定义为:
c
1
=
(
k
1
P
)
2
,
c
2
=
(
k
2
P
)
2
c_{1}=(k_{1}P)^{2} , c_{2}=(k_{2}P)^{2}
c1=(k1P)2,c2=(k2P)2
其中,
k
1
=
0.01
k_{1} = 0.01
k1=0.01,
k
2
=
0.03
k_{2} = 0.03
k2=0.03、
P
P
P为像素值的动态范围。
IE是地面真实帧
I
G
T
(
x
,
y
)
I^{GT}(x,y)
IGT(x,y)和估计的插值帧
I
^
(
x
,
y
)
\hat{I}(x,y)
I^(x,y)之间的均方根(RMS)差值。IE的定义为:
I
E
=
[
1
N
∑
(
x
,
y
)
(
I
^
(
x
,
y
)
−
I
G
T
(
x
,
y
)
)
2
]
1
2
IE=\left [ \frac{1}{N}\sum_{(x,y)}\left ( \hat{I}\left ( x,y \right )-I^{GT}(x,y) \right ) ^{2} \right ] ^{\frac{1}{2} }
IE=
N1(x,y)∑(I^(x,y)−IGT(x,y))2
21
插值帧
I
^
(
x
,
y
)
\hat{I}(x,y)
I^(x,y)和地面真值帧
I
G
T
(
x
,
y
)
I^{GT}(x,y)
IGT(x,y)之间的NIE为:
[
1
N
∑
x
,
y
(
I
^
(
x
,
y
)
−
I
G
T
(
x
,
y
)
)
2
∥
▽
I
G
T
(
x
,
y
)
∥
2
+
μ
]
1
2
,
\left [ \frac{1}{N}\sum_{x,y} \frac{\left ( \hat{I}\left ( x,y \right )-I^{GT}(x,y) \right ) ^{2}} {\left \| \bigtriangledown I^{GT} \right(x,y) \|^{2}+\mu } \right ] ^{\frac{1}{2} },
N1x,y∑∥▽IGT(x,y)∥2+μ(I^(x,y)−IGT(x,y))2
21,
其中
N
N
N为像素数,任意缩放常数设置为
μ
=
1.0
\mu = 1.0
μ=1.0。IE或NIE越低表示性能越好。
在SoftSplat [83]中,还加入了LPIPS(学习感知图像补丁相似度)度量[153],致力于测量感知相似度,LPIPS的低值意味着更好的插值性能。Yang等人[146]提出了一种新的用于视频压缩的VFI专用质量度量:感知帧插值质量度量(PFIQM)。他们考虑了阻塞工件和可能的质量下降区域,以克服其他广泛使用的指标中的这些缺点。与现有的很少直接使用运动信息的视频质量评估(VQA)算法的运动信息不同,[102]等人提出了一种基于运动的VQA算法MOVIE,用于评估动态视频保真度。Vu等人还考虑了运动伪影的视觉感知,并提出了VQA的时空最表观失真(ST-MAD)算法。Zhang等[152]提出了一种基于视觉显著性的图像质量评估(IQA)算法,即VSI。他们首先使用视觉显著性作为特征来计算失真图像的局部质量图,然后他们使用视觉显著性作为加权函数来反映局部区域的重要性。VSI的性能优于SSIM,但其计算成本是SSIM的5.6倍。Wang等人提出了一种多尺度SSIM方法,比单尺度方法具有更大的灵活性。Men等人的[77]评估了12种插入慢动作视频的质量评估指标,包括四种VQA方法(如电影、ST-MAD)和8种IQA方法(如VSI、MS-SSIM、SSIM)。然而,在VFI领域,PSNR、SSIM、IE和NIE是最常用的。
3. 视频帧插值方法
基于流的方法、基于核的方法、流和核组合方法,以及基于相位的方法。
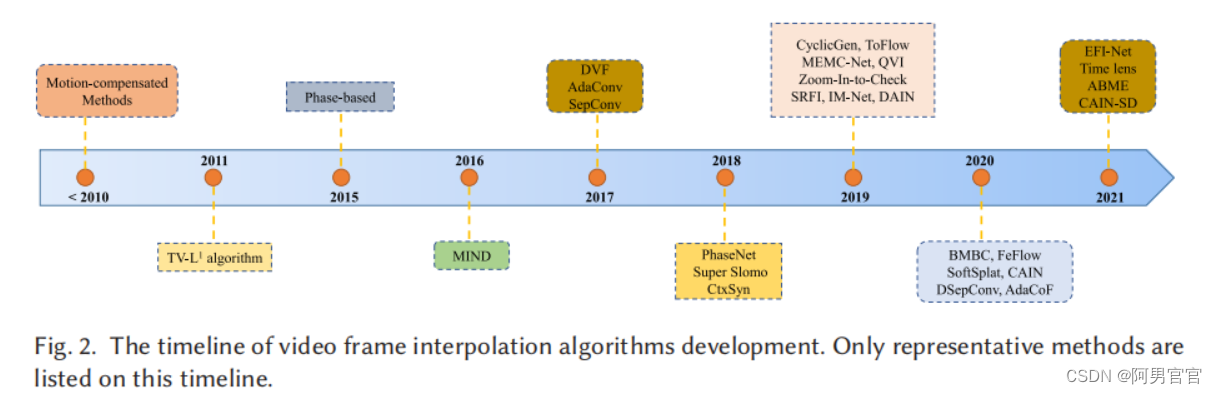
3.1. Brief History
运动补偿:运动补偿VFI方法通常包括运动估计和运动补偿帧插值两个阶段。在估计了相邻帧之间的运动轨迹后,沿着运动轨迹插值新的帧。运动轨迹的精度和插值方法的性能决定了生成帧的质量。
随着光流估计方法的发展,越来越多的算法在两个连续输入帧之间应用光流估计。维尔伯格等人[134]提出了一种光流驱动的TV-L1去噪算法,用于视频插值问题。CNN和深度学习的出现促进了更有效的光流分析方法,如FlowNet [30]、PWC-Net [113];许多VFI方法将它们作为基流估计算法来分析输入帧[4,82,90,141]之间的流。随着神经网络的发展,神经网络也被直接用于设计端到端VFI算法。Long等人[74]提出了一个基于cnn的方法的先驱,Liu等人[73]提出了一个端到端和自监督的完全可微网络:深度体素流(DVF)。AdaConv [84]使用全深度cnn来估计每个像素的空间自适应卷积核。CtxSyn [82]采用上下文映射以像素级上下文信息扭曲输入帧,合成中间视频帧,DAIN [4]利用深度信息,FeFlow [38]关注相应深度特征之间的特征流,CAIN [22]组合信道注意插值高质量帧。
另一方面,Meyer等人关注了相位信息,并提出了基于相位的VFI方法[78,79]。我们将在图2中介绍现有VFI方法介绍这些里程碑的时间表,下面将介绍这些方法的细节。除了这些方法之外,还有一些基于生成对抗网络(GAN)模型、事件摄像机和元学习的方法,我们在第3.7节中介绍这些方法。
3.2. Optical Flow Estimetion Methods
DeepFlow [132]是一种性能最好的手工算法,具有一个卷积框架,类似于深度学习模型,但没有学习参数。FlowNet [30]是基于U-Net架构[98]的光流估计场景中的一种里程碑方法,提出了两种网络架构[98](流网简单)和流网络C(流网相关),展示了使用CNN模型的优点。Ilg等人[46]设计了一个更大的网络流网2,使用流网和流网作为构建块。此外,作者通过去除小位移网络和显式亮度误差,并在堆栈中添加剩余连接,进一步提高了FlowNet2的性能,并提出了FlowNet3 [47]。
无监督的方法是这一领域的另一个重大发展。其主要思想是利用各种真实数据集来训练光流模型,该模型不受训练数据集和测试数据集之间不匹配的影响。Meister等人[76]提出了一个端到端无监督模型,可以在没有光流地面真相的大数据集上对流量网网络进行实际训练。[53]等人研究了什么影响无监督光流估计的性能,并使用系统的方法来比较、评估和改进一系列重要的组件。
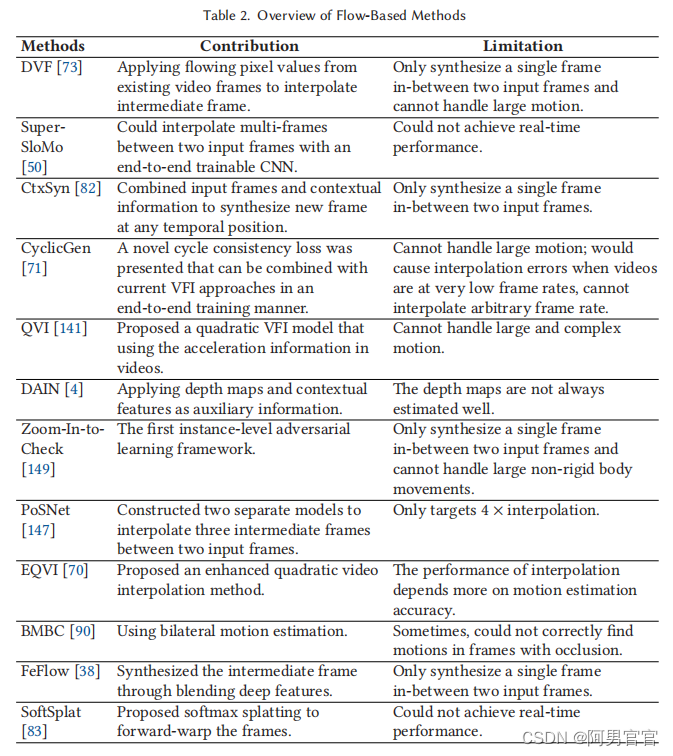
3.3. Flow-Based Methods
解决帧插值问题的最传统和最流行的方法是利用光流。光流可以感知连续帧中的运动信息,并捕获密集的像素对应关系。光流引导翘曲过程,将输入帧转换到插值帧的适当位置,然后将它们构造地混合。在[95]中,Raket等人引入了一种基于沿运动矢量插值的运动补偿VFI方法,以一个简单的TV-L1光流算法作为原型,证明了具有竞争力的结果。Yu等人提出了一种基于块级、像素级和序列级的多级VFI方案。这些传统的解分析连续帧之间的光流,然后沿着光流矢量进行插值。当光流准确时,它们工作得很好;然而,这种情况总是具有挑战性的,产生显著的伪影。
近年来,神经网络的发展促进了许多CV问题的解决,如目标识别、图像处理和视频处理。作为第一个使用基于CNN的方法之一,Long等人[74]提出了一种无监督的方法,该方法训练并应用CNNs进行帧插值,然后反向CNN来预测光流。然而,这种方法的主要缺点是遭受严重的模糊。Liu等人[73]引入了端到端自监督完全可微网络,深度体素流(DVF),通过流动连续帧的像素值来插值不存在的帧。然而,虽然这种方法可以减少新帧的模糊,但它不能处理大规模的运动。
基于CNN的方法侧重于单帧插值,并不适合多帧插值[4,17,50,140],这是慢动作应用的核心技术。Jiang等人[50]旨在解决这个问题,他们提出了超级slomo2在两个输入帧之间插值可变长度的多帧。他们首先应用一个U-Net [98]网络来计算输入帧之间的双向光流,然后他们使用另一个U-Net来改善光流并预测软可见性图。Dutta等人的[31]通过残差细化提高了超级slomo的性能。Wu等人[137]针对VFI问题提出了一种包括流细化、帧合成和Haar细化在内的双重细化网络,该网络包含三个浅层U-Ntes,其参数数量比以往的许多解决方案要少得多。此外,DAIN [4] 3方法使用深度信息来显式地检测遮挡。他们采用PWC-Net [113]来估计流量,采用U-Net [98]体系结构来估计内核,采用沙漏体系结构[12]作为深度估计网络。DAIN可以在输入帧之间插值多帧。然而,插值结果主要依赖于深度图,在具有挑战性的情况下,当深度图不能准确测量时,该方法往往会产生模糊和模糊的边界。
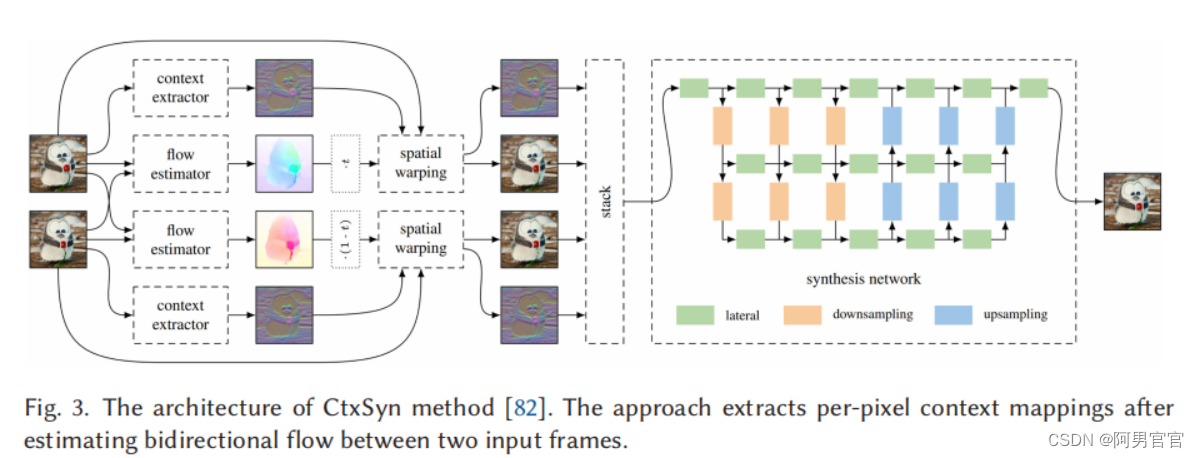
Niklaus等人提出了CtxSyn [82]算法,图3显示了该方法的概述,该方法采用上下文映射来扭曲输入帧及其像素级上下文信息来合成中间帧。他们使用PWC-Net [113]来估计双向流并提取像素级上下文图,然后应用GridNet [35]来生成最终的插值。
Liu等人引入了一种新的损失函数,循环一致性损失,以增强插值结果。循环基因[71] 4建立在DVF [73]之上,共享相同的设置;然而该方法不能很好地处理大的运动。Reda等人[97]尝试以一种完全无监督的方式,仅从低帧率的原始视频中学习,并使用周期一致性约束来合成任意的高帧率视频。该方法基于超级Slo-mo模型,它可以预测任何时间戳的中间帧,而CyclicGen是专门训练来合成中间帧。此外,Park等人提出了一种基于双边运动估计的基于深度学习的VFI算法: BMBC [90],它可以在任意时间
t
∈
(
0
,
1
)
t\in(0,1)
t∈(0,1)插值一个新帧。BMBC由双边运动网络和动态滤波器生成网络组成,前者用于精确估计双边运动,后者用于扭曲两个输入帧并输入它们以学习滤波器系数。最后,将扭曲帧与生成的混合滤波器叠加合成新帧。
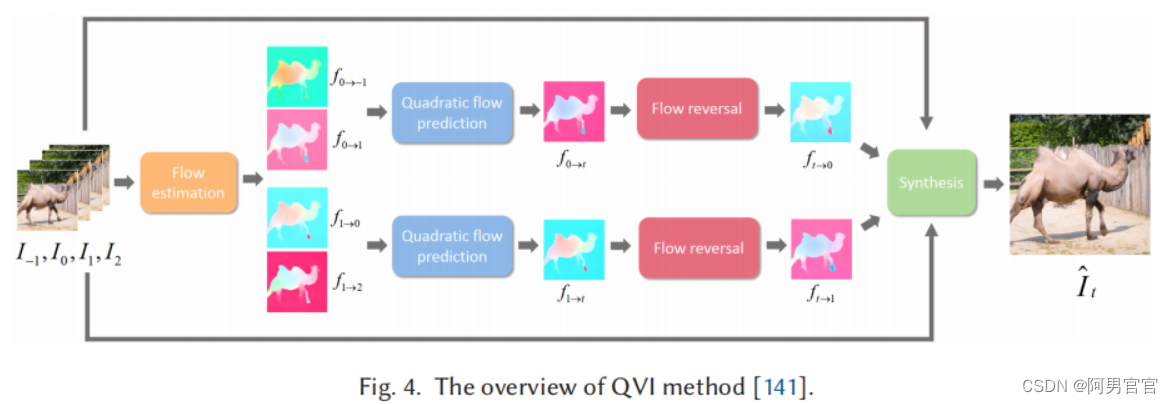
Xu等人提出了二次视频插值(QVI)[141] 6算法,利用了连续帧中的加速度信息。QVI方法的概述如图4所示。首先,作者应用PWC-Net来估计输入帧 ( T − 1 , I 0 , I 1 , I 2 ) (T_{-1},I_{0},I_{1},I_{2}) (T−1,I0,I1,I2)之间的光流。然后利用二次流 f 0 → − 1 f_{0\rightarrow-1} f0→−1和 f 0 → 1 f_{0\rightarrow 1} f0→1预测模块预测中间流图 f 0 → t f_{0\rightarrow t} f0→t。后向流 f t → 0 f_{t\rightarrow 0} ft→0被正向流 f 0 → t f_{0\rightarrow t} f0→t反转, f t → 1 f_{t\rightarrow 1} ft→1可以用类似的方法计算。最后,通过扭曲和使用输入帧 f t → 0 f_{t\rightarrow 0} ft→0和 f t → 1 f_{t\rightarrow 1} ft→1来合成中间帧。然而,该算法生成的中间帧仍然包含一些伪影,特别是当输入帧之间存在大规模和复杂的运动时。为了解决大的运动问题,Liu等人提出了一种增强的QVI(EQVI)[70] 7模型。他们从三个方面进一步提高了QVI的性能: (1)采用最小二乘法对原二次流预测模块进行校正,以提高插值光流的精度;(2)提出一种残差上下文合成网络(RCSN),结合预先提取的高维特征的上下文信息,从而减少运动估计不准确和目标遮挡的问题;(3)提出了一种新颖的、可学习的增强多尺度融合网络来提高性能。Zhang等人[155]提出了一种不知道时间先验的通用二次VFI方法,该方法结合恢复网络从模糊帧中提取时间明确的敏锐内容。
另一方面,Yan等[145]提出了一种新的细粒度运动估计方法(FGME)来解决VFI任务的大运动问题,它主要包含两种策略: (1)逐步细化光流和权重图;(2)生成多个光流和权值图,提供细粒度的运动特性。该方法可以处理不同尺度的运动,包括小运动和大运动。Zhao等人[156]引入了一种边缘感知网络,将边缘信息集成到VFI问题中,以减少图像模糊。Gui等人[38]关注了介于相应的深度特征之间的特征流(FeFlow)8,并为VFI设计了一个结构到纹理的生成模型。插值过程分为结构引导插值和纹理细化两个步骤。
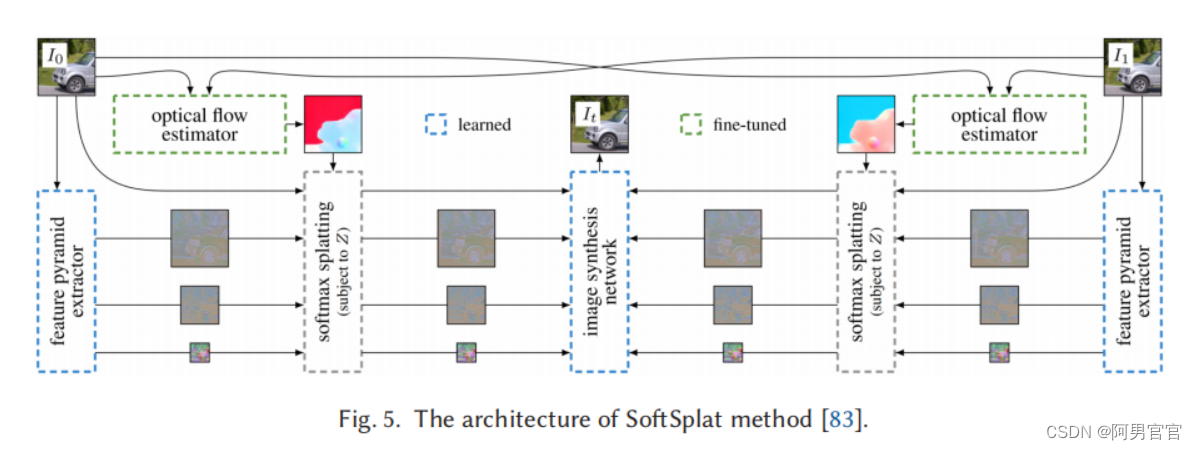
Park等人[91] 9提出了一种基于向后翘曲的VFI方法,该方法由非对称双边运动估计(ABME)和帧插值模块组成。与普通的向后翘曲不同,软splat[83]10模型关注前向翘曲。图5显示了SoftSplat方法的架构。具体来说,SoftSplat是基于光流估计,应用softmax分割,前扭曲两个输入帧及其特征金字塔表示,然后使用合成网络从扭曲表示中插值新帧。然而,向前和向后的扭曲都只利用了第一帧。Xue等人[142]引入了双侧翘曲来充分利用光流,并提出了这一局限性。Choi等人[24]提出了一种多尺度扭曲模块,它对小运动和大运动都能稳健地插值帧。
上面介绍的方法都集中于插值性能。大多数算法都是在gpu上进行训练和测试的。目前,随着边缘器件的增加,其速度的加快提出了一些轻量级算法。Yuan等人[149]提出了一个轻量级的VFI框架放大到检查,Li等人[65]引入了一个轻量级的模型FI-Net,它接受任意大小的两帧作为输入。FI-Net是在特征级而不是图像级计算光流,且模型尺寸较小。Yu等人提出了一个4x VFI模型,旨在使用特定位置流(PoSNet[147])将15帧转换为60帧的视频。11为了提高中间帧的质量,他们使用了两个输入帧和流图作为模型中的附加信息。
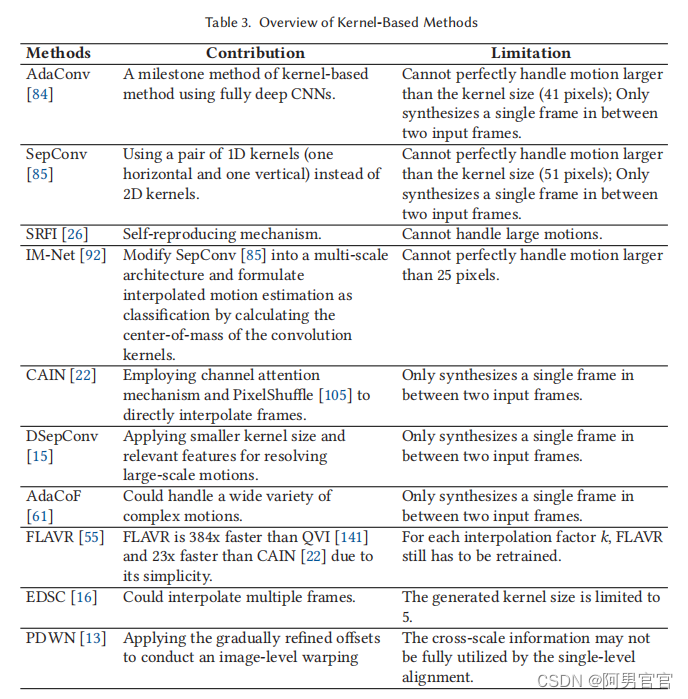
3.4. Kernel-Based Methods
基于光流的方法的插值结果受到光流估计质量的影响,而光流估计质量很容易受到亮度突变和光照变化的影响。在VFI领域中,另一种常用的方法是基于核的方法。
作为VFI领域的一个里程碑方法,AdaConv [84]率先使用全深度CNNs来估计每个像素的空间自适应卷积核。AdaConv将两步插值方法(运动估计和像素合成)结合成一个具有两个输入帧的卷积过程。然而,AdaConv的性能受到卷积核大小的限制,需要大内存,作者设计核大小为41×41,如果大运动超过41像素,插值帧会模糊。为了解决这个问题,Niklaus等人提出了SepConv [85] 12,使用对1D内核(一个水平和一个垂直)而不是2D内核,1080p视频帧需要1.27 GB而不是26 GB内存。此外,该方法应用了一个深度完全CNN,并可以使用公共可访问的基准数据集进行端到端训练。然而,SepConv仍然有两个缺点。首先,SepConv可以处理的运动量受到内核大小的限制,即51像素,甚至大于AdaConv方法,如果两个输入帧的运动大于51像素,该方法仍然会产生重影伪影。估计小于内核大小的微小运动也同样是浪费的。其次,SepConv和AdaConv在两个输入帧的中间时间位置插值一个帧,而不能在任意的时间位置合成一个帧。在[86]中,Niklaus等人重新设计了自适应可分离卷积,并通过一组直观的改进优化了SepConv的单个部分,如延迟填充、输入和核规范化、上下文训练。这些改进使得所提出的SepConv++方法在米德尔伯里数据集上的所有可用方法中排名第四。
Deng等人[26]提出了一种新的自复制机制,称为自复制帧插值(SRFI),以有效地提高VFI的一致性和性能,它可以与最先进的算法结合和改进。受可变形卷积的启发,Chen等人[13]设计了一个金字塔可变形扭曲网络(PDWN),利用金字塔网络来合成未知的中间帧。
Peleg等人[92]提出了一种插值运动神经网络(IM-Net),旨在实现高分辨率和实时参考时间。IM-Net由三个模块组成:特征提取、编码器-解码器和估计。特征提取模块处理六个输入帧中的每一帧,并将提取的特征发送到下一个模块,然后编码器-解码器模块将三个合并后的输出传递到三个并行估计路径。作者比较了ToFlow [143]和SepConv [85]在低分辨率和高分辨率基准数据集上的性能和参考时间。这三种方法在低分辨率下的质量是相等的,但当使用高分辨率视频(1376×768)时,IM-Net在三种算法中表现最好。Ahn等人,[1]也关注了高分辨率的VFI。他们提出了基于任务的混合CNN来实现快速和准确的4K VFI任务。该方法由插值中间帧的时间插值网络和从合成帧重建原始尺度帧的空间插值网络组成。与SepConv和超级Slomo相比,在泰坦X(Pascal)GPU上,所提出的算法只运行620 ms来插值4K帧,比SepConv快2.69倍,并且在PSNR和SSIM值上也优于这两种方法。
Cheng等人[15]受到可变形卷积网络[25,162]成功的启发,提出了DSepConv,旨在解决大型运动问题。DSepConv可以通过学习可变形的偏移量、mask和空间自适应的可分离卷积核来处理使用小核大小的大运动。与其他基于内核的方法一样,DSepConv的局限性是它只能插值一个帧。作者提出了一种新的方法,称为增强变形可分离卷积(EDSC)[16] 13来解决这个问题。该模型不受核大小的约束,能够处理大的运动。作者设计了不同的估计器,其中涉及到时间信息作为一个控制。EDSC可以在任何时间位置直接插帧,而不使用递归方法。另一种受可变形卷积网络启发的VFI方法是自适应流体协作(AdaCoF)[61],14,它指的是任意数量的像素和连续帧中的任意位置。这种方法具有更多的自由度(DoF),因为内核的大小和形状都是不规则的。
为了解决光流的缺陷,Choi等人提出了一种新的方法(CAIN)[22] 15,用简单的特征图变换代替光流,称为PixelShuffle[105],并结合通道注意[154]来合成高质量的帧,而没有显式的估计运动。他们还构建了一个更全面的基准数据集,称为SNU-FILM,以评估可用的VFI方法对具有挑战性的运动和遮挡,而CAIN方法在高清分辨率(1280×720)帧上取得了优异的性能。
基于CAIN方法,Choi等人[23]提出了一种运动感知的动态体系结构来计算帧的不同区域的计算量。静态区域通过较少的层,而运动幅度较大的区域被缩小比例,以进行更好的运动推理。该方法可以显著降低计算成本(FLOPs)。Kalluri等人提出了一种无光流的VFI方法,称为FLAVR [55],16,该方法能够在两个输入帧之间插值多个中间帧。FLAVR是一种高效的3D CNN架构,它用编码器和解码器中的3D卷积取代了所有的2D卷积,以精确地模拟输入帧之间的时间动态,即使没有光流或深度图等外部输入,也能获得更好的插值质量。由于其简单性,FLAVR比QVI [141]快384倍,比CAIN [22]快23倍。
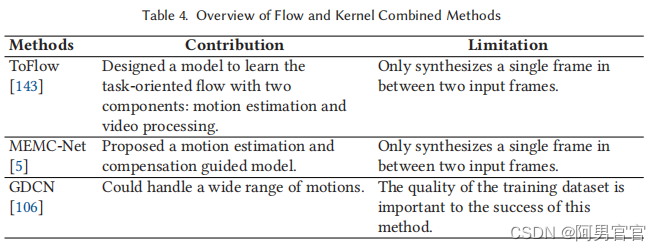
3.5. Flow and Kernel Combined Methods
为了弥补彼此之间的局限性,最近提出了集成基于内核和基于流程的机制的方法。它们将核与流向量的指示位置相乘。因此,它们可以引用任何位置以及附近的某些像素。
Xue等人提出了一种自监督方法ToFlow(任务导向流)[143]来学习运动表示。在VFI任务中的光流方法。Bao等人提出了一种用于VFI任务的运动估计和运动补偿引导神经网络(MEMC-Net)[5] 18。Shi等人提出了基于广义可变形卷积机制的GDCN [106] 19方法。GDCN能够处理广泛的运动,因为它能有效地以数据驱动的方式学习运动信息,并在时空中自由选择采样点。
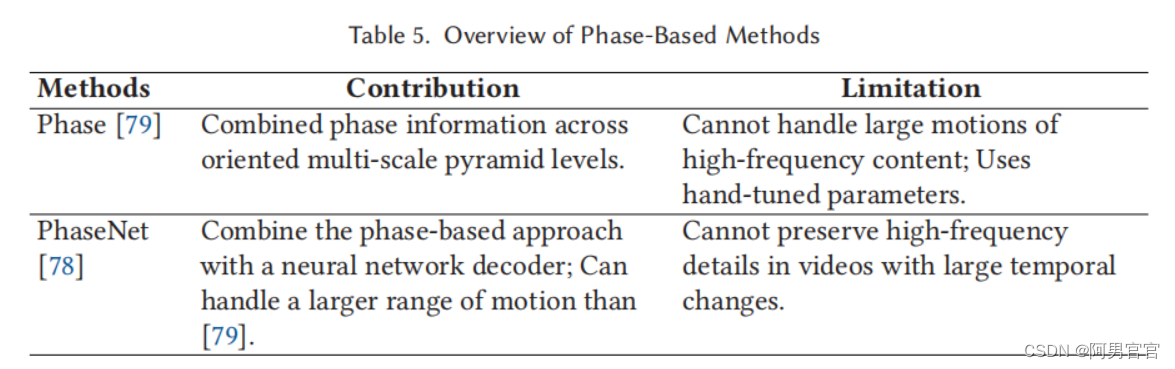
3.6. Phase-Based Methods
另一个研究方向使用相位信息在帧之间进行插值,以处理在包含运动模糊或照明变化的基于光流的方法上的具有挑战性的场景。正如傅里叶理论所述,图像可以表示为一系列正弦函数的和。例如,假设我们有两个正弦函数,它们被定义为 y 1 = s i n ( x ) y_{1}=sin(x) y1=sin(x)和 y 2 = s i n ( x − π / 3 ) y_{2}=sin(x-\pi/3) y2=sin(x−π/3),如图1(d)所示, y 1 y_{1} y1, y 2 y_{2} y2是相同的正弦函数, y 1 y_{1} y1通过 π / 3 \pi/3 π/3转换得到 y 2 y_{2} y2。平移,即运动,可以用 π / 3 \pi/3 π/3的相位差来表示。基于相位的方法表示运动作为单个像素之间的相位差。在图1(d)中,这两条正弦曲线将对应于两个输入帧。一个中间曲线将表示合成的中间帧。但由于相位值的 2 π 2\pi 2π-模糊性(i.e., y = s i n ( x − π / 3 ) = s i n ( x − π / 3 + 2 π ) y=sin(x-\pi/3)=sin(x-\pi/3+2\pi) y=sin(x−π/3)=sin(x−π/3+2π),存在两个有效的解,即 y 3 = s i n ( x − π / 6 ) y_{3}=sin(x-\pi/6) y3=sin(x−π/6)和 y 4 = s i n ( x − π / 6 + π ) y_{4}=sin(x-\pi/6+\pi) y4=sin(x−π/6+π))。
基于相位的VFI方法所面临的挑战是确定哪个选项是正确的解决方案。Meyer等人[79]介绍了一种基于相位的VFI算法,该算法使用一种新的有界位移校正策略,结合了跨定向多尺度金字塔水平的相位信息。这种方法的性能比当时任何其他基于流的方法都要好,并且运行得更快。然而,这种基于相位的方法不能代表高频内容的大运动,即使在小运动的区域仍然模糊。为了提高性能,作者提出了另一种新的基于相位的方法,相位网[78]。它包括一个直接计算输入帧的相位信息的神经网络解码器。中间帧的相位和振幅值。在不同的层次上,根据这些预测重建最终的帧。相位可以处理[79]更大的运动,并由于跨通道和金字塔级别共享权重而减少参数。该方法适用于有亮度变化和运动模糊的场景。然而,它仍然不能实现与显式匹配和扭曲像素的方法相同的性能。
3.7. Other
6. 挑战和未来规划
Computational Inefficiency.
Large Motion and Occlusion.
Event Cameras in VFI Field.
与传统相机相比,事件相机具有多种优点,包括低延迟、高时间分辨率、高动态范围、低功耗和稀疏的数据输出。

















 81
81

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









