






前言:CVPR2017基于kernel做插帧的典型方法
代码:【here】
Video Frame Interpolation via Adaptive Convolution
引言
目前的插帧算法都是两阶段的,即先进行运动估计,再进行像素级合成
这种方法容易受到 遮挡、亮度突然变化、模糊的影响
本文提出了一种基于核的方法,直接用一个全卷机网络学习每个像素上的内核,实现的运动估计和像素完成
贡献:
更鲁棒,不用考虑模糊亮度变化的约束
端到端训练,不用考虑中间的光流真值
做了实验验证,的确在模糊、亮度变化等场景更有优势
方法
首先,作者分析了基于流和基于核的方法局别
基于流的方法如下图图a所示,先估计出运动,再由运动信息插值得到像素值,这种方法受到模糊遮挡的损害
而基于核的方法直接学习像素区域的值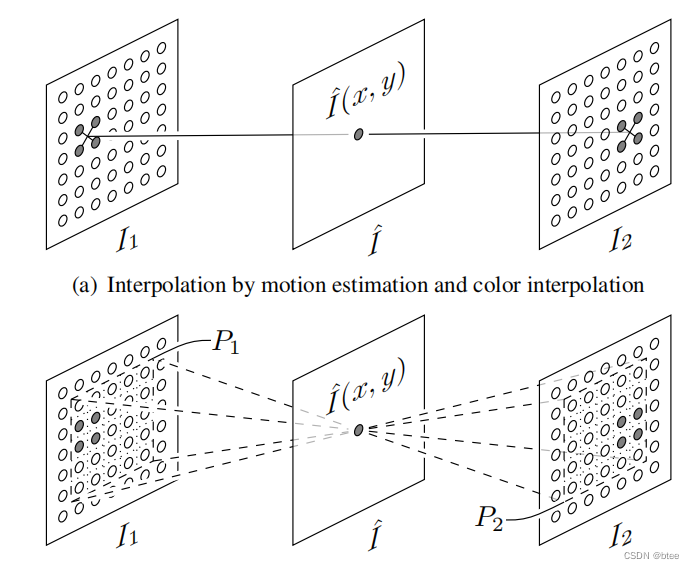
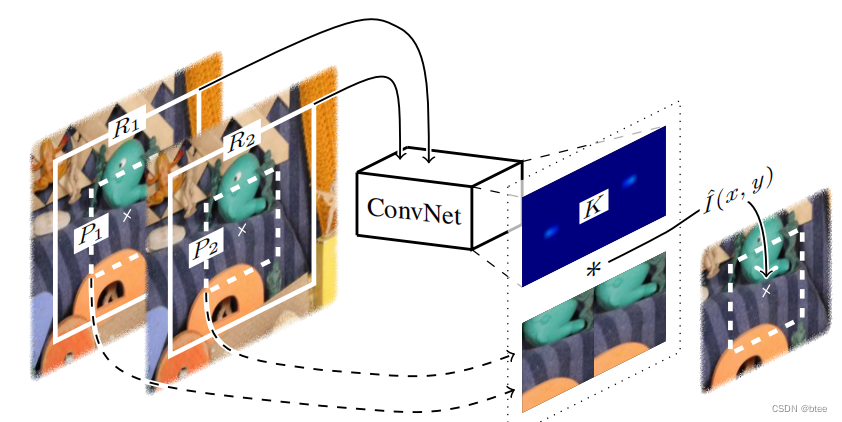
如上图,通过对P1P2为中心的像素块进行拼接,然后卷积,学习到一个比较大的卷积核,这个卷积核卷积这块像素区域即得到新的像素点的值
网路的参数如下,其中,输入的两张图在通道拼接,卷积的两张图在宽拼接,因此卷积核也在宽拼接
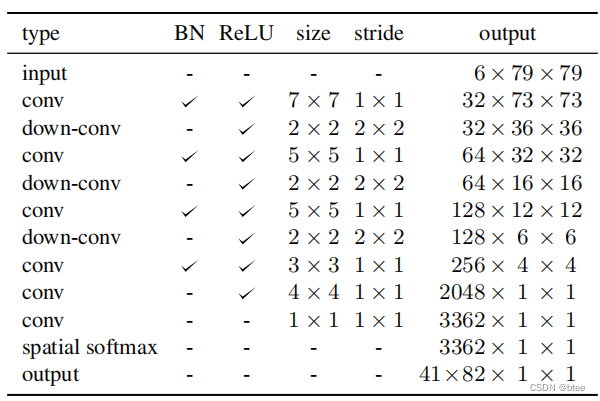
由于生成的核的权重是加起来为0,因此得过一个 spatial softmax
实验
对比实验
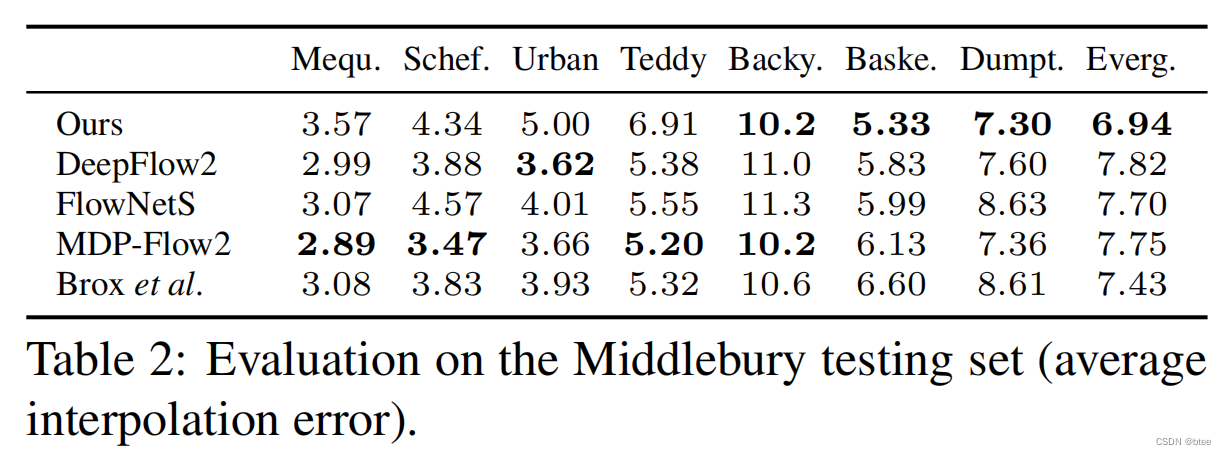
模糊场景效果验证

亮度突变效果验证

遮挡效果验证(光流方法出现孔洞)

作者最后还分析了一些基于核方法目前的问题,即只能插一帧,不能插任意时刻的帧
总结
早些年的视频插帧文章,基于卷积网络得到卷积核的思想来学习两张图像之间区域间的插帧值还是很值得学习的














 933
933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









